







1.1 维纳滤波概况
维纳滤波算法,最早起源于第二次世界大战期间,为解决军事上对空射击的控制问题,由数学家Norbert Wiener提出,主要用于从带噪的观测信号中提取出所需要的干净信号。维纳滤波算法至今已有近80年的历史,虽然古老,但是其思想一直延续至今,并得到了不断的完善和优化。维纳滤波算法的本质就是从噪声中提取信号的过滤和预测的方法,并以估计的结果与信号的真值间误差的最小均方值作为最佳准则。因此,维纳滤波器是统计意义上的最优滤波器,或者说是波形的最优线性估计器。此外,维纳滤波算法以其较小的运算复杂度和不错的降噪性能优势,在语音增强的工程领域一直发挥着很重要的作用。
经过了几十年的发展,维纳滤波算法的种类和变体很多,其中比较实用,且应用较广的,算是频域的维纳滤波算法,而频域的维纳滤波算法中的变体、优化形式又十分丰富,也使得维纳滤波算法在语音增强的学术和工程领域都占有一席之地。这些多样的维纳滤波算法的性能,各有利弊,有好有坏,因此也不能说具体哪种维纳滤波更好。但是,发展到现在,基于维纳滤波的卡尔曼滤波算是这其中的佼佼者,它通过引入卡尔曼信息,更适应于动态系统非平稳条件下和最小均方误差意义下的最优估计,所以在这几年学术研究中比较热门,关于这方面的论文也比较多。
1.2 维纳滤波算法的分类
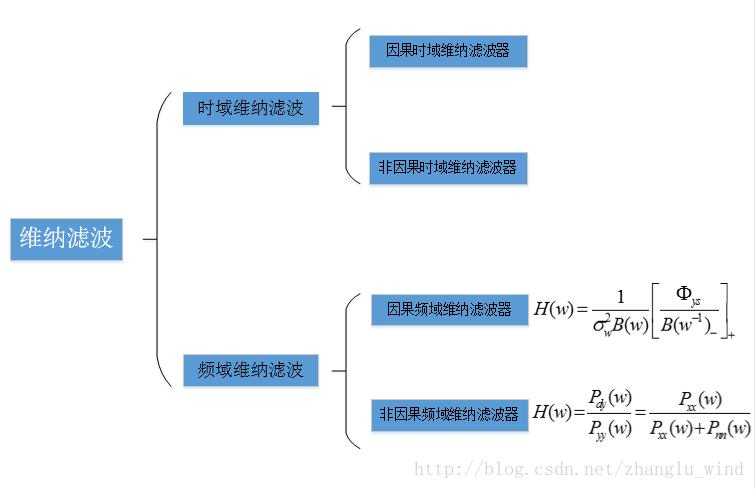
根据维纳滤波算法应用域的不同,可以分为:时域的维纳滤波和频域的维纳滤波。而根据是否利用未来的信息来估计当前的值,又可将其分成因果系统和非因果系统,于是所有的维纳滤波算法便可以划分成四大类:因果时域维纳滤波器、非因果时域维纳滤波器、因果频域维纳滤波器和非因果频域维纳滤波器。
对于因果的系统,只需要用到过去和当前的值来估计当前的期望值,而在非因果系统中,还需要用到未来的信息来估计当前的期望值,因此因果系统的维纳滤波和非因果系统的维纳滤波各自对应的增益函数解的形式也是不同的。并且由于非因果的维纳滤波器,可以运用未来的信息,所以效果较好;而因果的维纳滤波器不能利用“未来”的值,所以效果相比之下会差一点。另外,在工程应用中,频域的维纳滤波算法使用地更加广泛,因为其更容易实现,性能也相对更好;并且在学术领域,对于频域维纳滤波的研究也比较丰富,所以下面将着重介绍频域的维纳滤波算法。
首先,对于因果解的频域维纳滤波,其增益函数的表达形式如下:
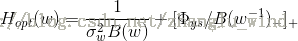
因为是因果系统,也就意味着上述增益函数的求解是物理可实现的,也就是说,我们不需要未来的信息,只是利用当前和过去的信息,便可以直接求得上述的维纳滤波器的增益函数值。但是,由于上述解的形式过于复杂,求解起来过于麻烦,所以因果的频域维纳滤波应用的并不是很广泛。
而对于非因果解的频域维纳滤波器,其增益函数的表达形式如下:
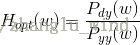
进一步地,如果假设语音和噪声是非相关的,我们有:
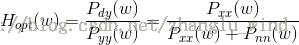
其中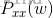
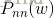

利用因果的方法去逼近求解非因果的增益函数,主要方法有两大类:迭代的方法和非迭代的方法。而为了进一步的提升维纳滤波的性能,又可以对这两种方法施加一定的约束,于是便有了四大类求解方法,分别为:无约束的迭代维纳滤波、有约束的迭代维纳滤波、无约束的非迭代维纳滤波和有约束的非迭代维纳滤波。关于这四类非因果的频域维纳滤波方法的具体介绍,会在后面的维纳滤波专题中详细介绍。
最后,必须提及的是,维纳滤波器是在一维平稳状态下的线性最优估计器,也就是说,只有输入信号是统计意义上是平稳信号时,其增益函数解才是最优解。并且由于是线性估计器,所以也就意味着其在解决一些复杂的非线性问题时(例如,噪音污染问题)不是最优的。再加上平时我们所使用的维纳滤波器,大多都是用因果的方法去近似非因果的增益函数表达式,所以这又进一步降低了其最优解的精确度。但是,不得不说,虽然受到这些理想假设和近似条件的限制,用因果方法实现的非因果频域维纳滤波器,在很多情况下的效果还是十分显著地。















 4473
4473

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









