







PLT, Procedure Linkage Table, 过程链接表
GOT, Global Offset Table, 全局偏移表
简略来说就是从PLT去GOT找api真实地址。
rel表的作用是:
本程序装载进内存时,通过自己的rel表项告诉链接器,哪些地方需要重定位。
got表的作用是:
用来存放链接器找到的 函数/变量地址。
plt表的作用是:
在动态链接过程中, 函数在加载共享库之后,会对got表进行重定向。当程序执行到引用变量或调用函数时候利用plt跳转到got表中项指定的地址即可。
共享库是现代操作系统的一个重要组成部分,但是我们对它背后的实现知之甚少。当然,很多文档从各个角度对动态库进行过介绍。希望我的这边文章能给对动态库的理解带来一种新的理解。
让我们以此开始——在elf格式中,重定位记录是一些允许我们稍后填写的二进制信息——链接阶段由编译工具填充或者在运行时刻由动态连接器填写。一个二进制的重定位记录从本质上说就是“确定符号X的值,然后把这个值放入二进制文件中的偏移量为Y的地方”——每一个重定向记录都有个特定的类型,这个类型在ABI文档中定义,用来准确的描述在实际中是如何确定X的值。
下面是一个简单的例子:
$ cat a.c
extern int foo;
int function(void) {
return foo;
}
$ gcc -c a.c
$ readelf --relocs ./a.o
Relocation section '.rel.text' at offset 0x2dc contains 1 entries:
Offset Info Type Sym.Value Sym. Name
00000004 00000801 R_386_32 00000000 foo
在编译生成a.o文件的时候,编译器并不知道符号foo的值,所以预留一个重定位记录(类型为R_386_32),表示“在最终的二进制文件中,把这个目标文件中符号foo的地址填入偏移量为4的地方(相对于text 区而言)”。如果你观察下a.o的汇编结果,你就会发现在text区偏移量为4的地方,有4个字节为0,这四个字节最终将会填入真实的地址。
$ objdump --disassemble ./a.o
./a.o: file format elf32-i386
Disassembly of section .text:
00000000 <function>:
0: 55 push %ebp
1: 89 e5 mov %esp,%ebp
3: a1 00 00 00 00 mov 0x0,%eax
8: 5d pop %ebp
9: c3 ret
在链接的时候,如果你编译的另外一个目标文件含有foo的地址,并且把这个目标文件与a.o一起编译为一个最终的可执行文件,那么重定位记录就会消失。但是仍然有很多的东西直到运行的时候才能确定,当编译一个可执行文件或者动态库的时候。正如我马上要解释的,PIC,与地址无关的代码是一个很重要的原因(PIC,即Position independent code,直接翻译就是位置无关代码,简单的说就是这个代码可以被load到内存的任意位置而不用做任何地址修正。这里指的是代码段,数据段可能需要地址修正。)。当你观察一个可执行文件,你会注意到它有一个固定的加载地址:
$ readelf --headers /bin/ls
[...]
ELF Header:
[...]
Entry point address: 0x8049bb0
Program Headers:
Type Offset VirtAddr PhysAddr FileSiz MemSiz Flg Align
[...]
LOAD 0x000000 0x08048000 0x08048000 0x16f88 0x16f88 R E 0x1000
LOAD 0x016f88 0x0805ff88 0x0805ff88 0x01543 0x01543 RW 0x1000
这并不是地址无关。代码段(权限为RE,可读可执行)必须被加载到虚拟地址0x08048000,数据段(RW)必须被加载到0x0805ff88。
这对于可执行文件来说很不错,因为每一次你创建一个新的进程(fork,然后exec),都会有一个全新的地址空间。考虑到时间的消耗提前计算好地址并把它们固定到最终的输出文件中,这种方式是值得考虑的。(当然也可以采取 与地址无关的可执行文件 的方式来实现,但这是另外的一个话题了)
这对于共享库来说就不是那么好了。关键点是,你可以为了达到你的目标而对共享库随意的组合。如果你的共享库必须要在固定的地址上运行,32位的系统的地址空间很快就不够用了。因此当你查看一个共享库,它们并不指定一个固定的加载地址:
$ readelf --headers /lib/libc.so.6
Program Headers:
Type Offset VirtAddr PhysAddr FileSiz MemSiz Flg Align
[...]
LOAD 0x000000 0x00000000 0x00000000 0x236ac 0x236ac R E 0x1000
LOAD 0x023edc 0x00024edc 0x00024edc 0x0015c 0x001a4 RW 0x1000
共享库还有第二个目的,代码分享。如果有一百个进程使用一个共享库,就没有必要在内存中产生100分代码拷贝。如果代码是完全只读,并且永远不会修改,那么每一个进程就可以分享相同的代码。然而,对于共享库有一个约束:对于每一个进程都必须有一份自己的数据实例。然而,在运行时刻,将库数据放到任何我们想要的地址上也是可行的,这就要我们预留重定义记录为代码段打上“补丁”,告知代码段到哪里找到实际的数据——这种方法实际上是不行的,因为破环了动态库的代码只读属性和共享性。就如同你从头文件信息中看到的一样,解决方案为:可读可写的数据段相对于代码段有一个固定的偏移量。通过这种方式,利用虚拟内存的魔力,每个进程都有属于自己的数据段,而共享不可修改的代码段。所以访问数据段的算法是很简单的:我想访问的数据的地址 = 当前地址+ 固定偏移。
但是,当前的地址有可能不是那么简单的知道:
$ cat test.c
static int foo = 100;
int function(void) {
return foo;
}
$ gcc -fPIC -shared -o libtest.so test.c
foo位于数据段,与函数function中的指令有一个固定的偏移量。我们要做的就是找到它。在amd64上,这很简单:
000000000000056c <function>:
56c: 55 push %rbp
56d: 48 89 e5 mov %rsp,%rbp
570: 8b 05 b2 02 20 00 mov 0x2002b2(%rip),%eax # 200828 <foo>
576: 5d pop %rbp
上面的代码的意思是说“把与当前指令地址偏移0x2002b2处的值放入eax”。另一方面,i386并没有提供访问当前指令偏移的能力。所以有一些限制:
0000040c <function>:
40c: 55 push %ebp
40d: 89 e5 mov %esp,%ebp
40f: e8 0e 00 00 00 call 422 <__i686.get_pc_thunk.cx>
414: 81 c1 5c 11 00 00 add $0x115c,%ecx //%ecx=0x414
41a: 8b 81 18 00 00 00 mov 0x18(%ecx),%eax
420: 5d pop %ebp
421: c3 ret
00000422 <__i686.get_pc_thunk.cx>:
422: 8b 0c 24 mov (%esp),%ecx
425: c3 ret
这里的魔数是__i686.get_pc_thunk.cx。i386不允许我们得到当前指令的地址,但是我们可以得到一个已知的固定地址——__i686.get_pc_thunk.cx的值,%ecx中的值是call的返回地址,这里是0x414.我们做一个简单的算术:0x115c+0x414 = 0x1570.最终的数据和0x1588偏移了0x18个字节,查看汇编代码:
00001588 <global>:
1588: 64 00 00 add %al,%fs:(%eax)
正是100所处的地址。
现在我们越来越接近了,但是还是有很多的问题要处理。如果一个共享库可以被加载到任意的地址,那么,一个可执行文件或者其他的共享库,如何知道怎么访问它的数据或者调用它的函数呢?从理论上,我们是可以的,加载库,然后把数据的地址或者函数的地址填入到库相应的地方。然后这正如之前所讲的,违反了代码共享性。就如同我们所了解的,所有的问题都可以通过增加一个中间层来解决,在这种情形下,称之为全局偏移表(got)。
考虑下面的库:
$ cat test.c
extern int foo;
int function(void) {
return foo;
}
$ gcc -shared -fPIC -o libtest.so test.c
这和之前的文件很像,但是foo是extern的。假设是由其他的库提供。让我们看一下在amd64上它是如何工作的:
$ objdump --disassemble libtest.so
[...]
00000000000005ac <function>:
5ac: 55 push %rbp
5ad: 48 89 e5 mov %rsp,%rbp
5b0: 48 8b 05 71 02 20 00 mov 0x200271(%rip),%rax # 200828 <_DYNAMIC+0x1a0>
5b7: 8b 00 mov (%rax),%eax
5b9: 5d pop %rbp
5ba: c3 retq
$ readelf --sections libtest.so
Section Headers:
[Nr] Name Type Address Offset
Size EntSize Flags Link Info Align
[...]
[20] .got PROGBITS 0000000000200818 00000818
0000000000000020 0000000000000008 WA 0 0 8
$ readelf --relocs libtest.so
Relocation section '.rela.dyn' at offset 0x418 contains 5 entries:
Offset Info Type Sym. Value Sym. Name + Addend
[...]
000000200828 000400000006 R_X86_64_GLOB_DAT 0000000000000000 foo + 0
反汇编的结果显示返回值位于当前指令偏移0x200271处:0x0200828(0x5b7+0x200271 = 0x200828)。查看section header,这个地址位于.got区。接着我们查看重定位记录,可以发现有一个类型为R_X86_64_GLOB_DAT的重定位的意思是“找到foo的值,然后把它放在地址0x200828处”。
所以,当这个动态库被加载,动态加载器将会检查重定位记录,找到foo的值,并按照要求为.got中的条目打上“补丁”。当动态库中的代码运行并访问foo的时候,访内指针将会指向正确的地址,一切都会正常工作,而不用去修改指令的值,以避免代码的共享性。
以上是数据的处理,那么函数调用呢?函数调用的中间层称之为procedure linkage table 或者PLT.代码不会直接调用外部的函数,而是通过一个plt stub。
$ cat test.c
int foo(void);
int function(void) {
return foo();
}
$ gcc -shared -fPIC -o libtest.so test.c
$ objdump --disassemble libtest.so
[...]
00000000000005bc <function>:
5bc: 55 push %rbp
5bd: 48 89 e5 mov %rsp,%rbp
5c0: e8 0b ff ff ff callq 4d0 <foo@plt>
5c5: 5d pop %rbp
$ objdump --disassemble-all libtest.so
00000000000004d0 <foo@plt>:
4d0: ff 25 82 03 20 00 jmpq *0x200382(%rip) # 200858 <_GLOBAL_OFFSET_TABLE_+0x18>
4d6: 68 00 00 00 00 pushq $0x0
4db: e9 e0 ff ff ff jmpq 4c0 <_init+0x18>
$ readelf --relocs libtest.so
Relocation section '.rela.plt' at offset 0x478 contains 2 entries:
Offset Info Type Sym. Value Sym. Name + Addend
000000200858 000400000007 R_X86_64_JUMP_SLO 0000000000000000 foo + 0
现在,我们function跳转到0x4d0.反汇编,我们看到这是一个有趣的调用,我们跳转到当前rip指针偏移0x200382,也就是0x200858处。可以发现,这个地址存放着符号foo的重定位的记录。
I让我们来看一下0x200858的初始值:
$ objdump --disassemble-all libtest.so
Disassembly of section .got.plt:
0000000000200840 <.got.plt>:
200840: 98 cwtl
200841: 06 (bad)
200842: 20 00 and %al,(%rax)
...
200858: d6 (bad)
200859: 04 00 add $0x0,%al
20085b: 00 00 add %al,(%rax)
20085d: 00 00 add %al,(%rax)
20085f: 00 e6 add %ah,%dh
200861: 04 00 add $0x0,%al
200863: 00 00 add %al,(%rax)
200865: 00 00 add %al,(%rax)
...
0x200858的初始值是0x4d6,居然是下一条指令的地址!这条指令把0要入栈中,然后跳转到0x4c0.通过查看代码我们可以发现,把GOT一个值压入栈中,然后跳到GOT中的第二个值。
00000000000004c0 <foo@plt-0x10>:
4c0: ff 35 82 03 20 00 pushq 0x200382(%rip) # 200848 <_GLOBAL_OFFSET_TABLE_+0x8>
4c6: ff 25 84 03 20 00 jmpq *0x200384(%rip) # 200850 <_GLOBAL_OFFSET_TABLE_+0x10>
4cc: 0f 1f 40 00 nopl 0x0(%rax)
这里究竟是在做什么呢?这就是 lazy binding(延迟绑定)——按照约定,动态连接器加载一个动态库,首先应该在got中的已知地址存放能够解析符号的默认函数。因此,上面的处理流程大体是这样子的:当第一次调用一个函数的时候,因为此时got中还没有它的地址,所以调用失败,从而进入默认的stub处理流程,这个stub用来解决符号解析。当找到foo的地址之后,就会把这个值填入到got,这样下次调用的时候,就直接调用到foo的实际地址。
原文地址:
https://www.technovelty.org/linux/plt-and-got-the-key-to-code-sharing-and-dynamic-libraries.html
GOT表和PLT表知识详解
转:https://blog.csdn.net/qq_18661257/article/details/54694748
GOT表和PLT表在程序中的作用非常巨大,接下来的讲解希望大家可以仔细看看
我们用一个非常简单的例子来讲解,代码如下:
图1
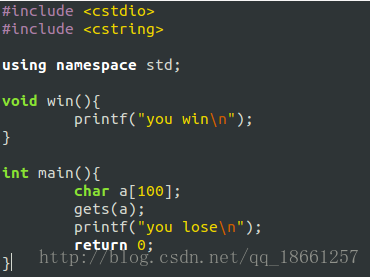
然后我们编译
我们直接gdb ./a.out来进行反编译处理,然后通过disas main查看main函数中的反编译代码如下:
图3
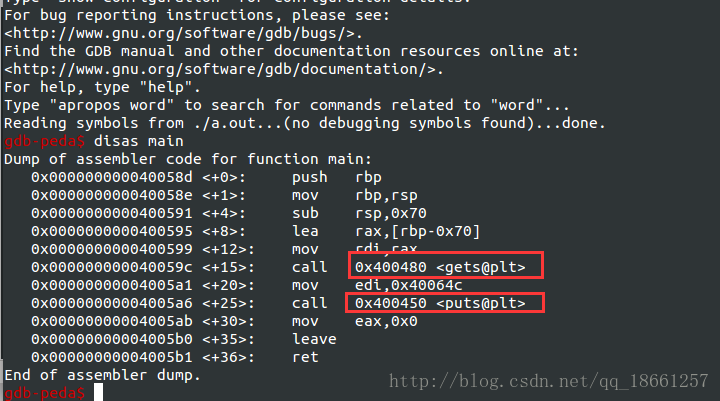
我们可以观察到gets@plt和puts@plt这两个函数,为什么后面加了个@plt,因为这个为PLT表中的数据的地址。那为什么反编译中的代码地址为PLT表中的地址呢。
原因
为了更好的用户体验和内存CPU的利用率,程序编译时会采用两种表进行辅助,一个为PLT表,一个为GOT表,PLT表可以称为内部函数表,GOT表为全局偏移表,这两个表是相对应的,什么叫做相对应呢,PLT表中的数据就是GOT表中的一个地址,如下图:
图44
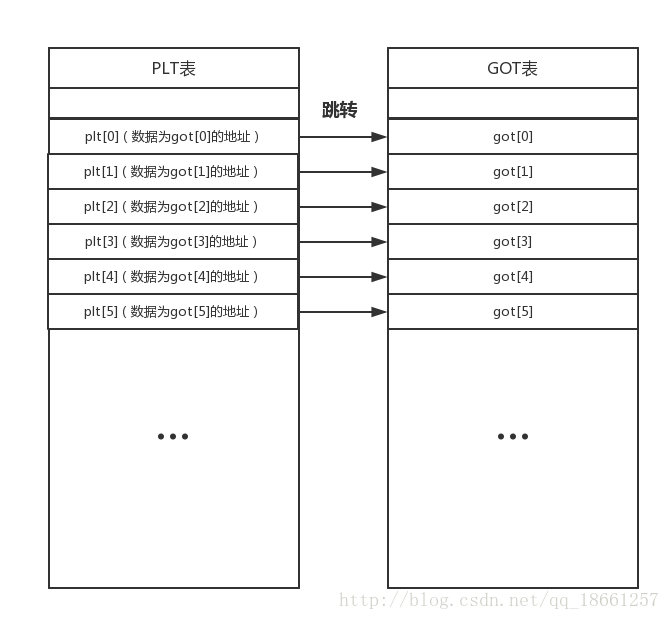
PLT表中的每一项的数据内容都是对应的GOT表中一项的地址,这个是固定不变的,到这里大家也知道了PLT表中的数据根本不是函数的真实地址,而是GOT表项的地址,好坑啊。
其实在大家进入带有@plt标志的函数时,这个函数其实就是个过渡作用,因为GOT表项中的数据才是函数最终的地址,而PLT表中的数据又是GOT表项的地址,我们就可以通过PLT表跳转到GOT表来得到函数真正的地址。
那问题来了,这个@plt函数时怎么来的,这个函数是编译系统自己加的,大家可以通过disas gets看看里面的代码,如下图:
图55

大家可以发现,这个函数只有三行代码,第一行跳转,第二行压栈,第三行又是跳转,解释:
第一行跳转,它的作用是通过PLT表跳转到GOT表,而在第一次运行某一个函数之前,这个函数PLT表对应的GOT表中的数据为@plt函数中第二行指令的地址,针对图中来说步骤如下:
- jmp指令跳转到GOT表
- GOT表中的数据为0x400486
- 跳转到指令地址为0x400486
- 执行
push 0x3#这个为在GOT中的下标序号 - 在执行
jmp 0x400440 - 而0x400440为PLT[0]的地址
- PLT[0]的指令会进入动态链接器的入口
- 执行一个函数将真正的函数地址覆盖到GOT表中
这里我们要提几个问题:
1. PLT[0]处到底做了什么,按照我们之前的思路它不是应该跳转到GOT[0]吗?
2. 为什么中间要进行push压栈操作?
3. 压入的序号为什么为0x3,不是最开始应该为0x0吗?
解决问题
问题1
看下图:
图66

我们尝试着查看0x400440地址的数据内容发现一个问题,从0x400440−0x400450之间的数据完全不知道是什么,而真正的PLT[x]中的数据是从0x400450开始的,从这里才有了@plt为后缀的地址,但是我们disas gets看代码的时候是从0x400440开始的,我们可以通过x /5i 0x400440查看0x400440处的代码,如下:
图77

我们看到了后面的#之后又一个16进制数,一看便可以知道是GOT表的地址,为什么这么肯定呢,因为我们可以通过objdump -R ./a.out查看一个程序的GOT函数的地址,如下图:
图88
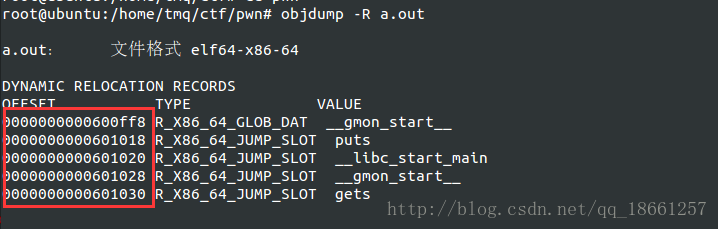
这里都是些GOT地址,我们发现都是0x601...这些,所以可以断定图77中的也是GOT地址,那么我们可以猜想出,在正式存储一个函数的GOT地址前,我们的PLT表前面有一项进行一些处理,我们暂且不具体深入剖析这些代码有什么用,但是我们可以肯定puts@plt前面那16个字节也算是PLT表中的内容,这其实就是我们的PLT[0],正如我们之前问题提到的那样,我们的PLT[0]根本没有跳转到GOT[0],它不像我们的PLT[1]这些存储的是GOT表项的地址,它是一些代码指令,换句话说,PLT[0]是一个函数,这个函数的作用是通过]GOT[1]和GOT[2]来正确绑定一个函数的正式地址到GOT表中来。
咦,这里问题好像又产生了,本来按照最开始的思路PLT[1]也是跳转到GOT[1]的,GOT[2]同理,但是这两个数据好像被PLT[0]利用了,同时GOT[0]好像消失了,这里GOT[0]暂且不说它的作用是什么,针对GOT[1]和GOT[2]被PLT[0]利用,所以我们程序中真实情况其实是从PLT[1]到GOT[3],PPLT[2]到GOT[4],所以我们推翻了我们的图44,建立一张新的处理表
图99
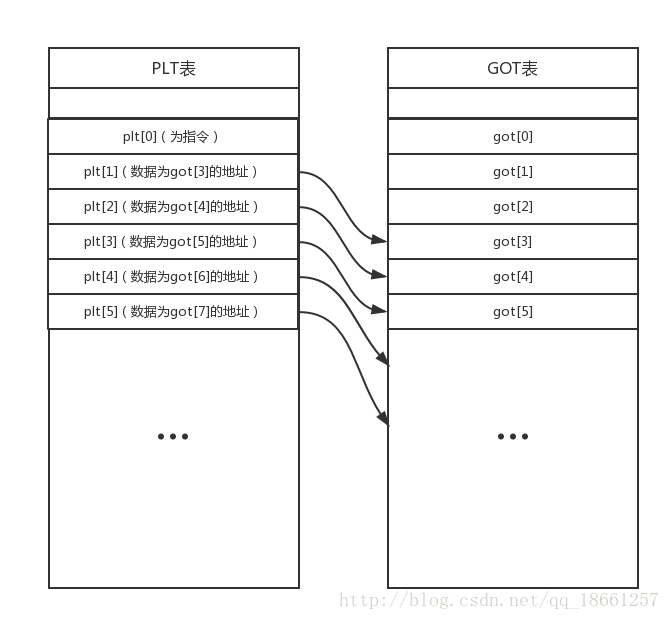
而plt[0]代码做的事情则是:由于GOT[2]中存储的是动态链接器的入口地址,所以通过GOT[1]中的数据作为参数,跳转到GOT[2]所对应的函数入口地址,这个动态链接器会将一个函数的真正地址绑定到相应的GOT[x]中。
这就是PLT表和GOT表,总而言之,我们调用一个函数的时候有两种方法,一个是通过PLT表调用,一个则是通过GOT表调用,因为PLT表最终也是跳转GOT表,GOT表中则是一个函数真正的地址,这里需要注意的是,在一个函数没有运行一次之前,GOT表中的数据为@plt函数中下一条指令的地址,图55有说。
问题2
中间进行的压栈是为了确定PLT对应的GOT表项,即是PLT[1]−>GOT[3],0x3就是GOT的下标3,也就是说压栈后我们跳转到PLT[0],接着PLT[0]中的指令会通过这次压栈的序号来确定操作的GOT表项的位置
问题3
好像都在第一个问题都已经解决了,这里压入0x3的原因是因为,我们的GOT[0],GOT[1],GOT[2]都有额外用处。要从GOT[3]开始
PIC的实现
转:https://blog.csdn.net/cody_kai/article/details/6589263
今天研究了下PIC,记录下。
1)什么是PIC,为什么要PIC
PIC,即Position independent code,直接翻译就是位置无关代码,简单的说就是这个代码可以被load到内存的任意位置而不用做任何地址修正。这里指的是代码段,数据段可能需要地址修正。
PIC是share library机制的基础之一,要实现library在各个process之间可以share,代码必须是PIC。为什么?有了load时的relocation还不够么?答案是也可以够,但是仅仅有load时的relocation,基本等于没有用。share library的主要目的是让各个process可以共享common的代码(指代码段),这部分代码只在内存中占用一次内存,所有process共享这部分代码,而不需要每个process都有一份拷贝。因为代码段是要被share的,所以代码段的内容不能被改变。load时的relocation是在load时对代码做地址修正,所以一旦library被load了,这个library在所有共享该library的process的地址空间中的位置也确定了。有人会问这样有什么问题么?OS在第一次load这个library的时候完全可以找个available的地址空间阿,因为第一次load的时候,是可以被load到内存的任意地方的,所以只要有地址空间就可以。遗憾的是,这种情况下地址空间很可能不够,而导致没法load。考虑这样的问题,如果某人写了个捣蛋的library,占用很大的地址空间,一旦这个library被load了,就会导致其他library不能被load,因为已经没有available的地址空间了,这样这个系统就会崩溃。所以要实现share library,仅仅load时的relocation是不够的,我们需要一种机制,可以让library被load进process的任意地址空间,或者说library在不同的process中,可以被load到不同的地址空间,然后在OS层,通过OS的地址空间映射,来实现library在物理内存上的share。所以PIC是必须的。
2)怎么实现PIC
PIC需要解决的问题就是找到一种办法,避免load时的地址修正(relocation)。以下面的代码为例,该代码把内存中符号one_dword对应的地址的一个dword的内容放到%eax里。如果一个library包含下面的代码,则这个代码不是PIC的。因为$one_byte会随着该代码被load到不同的地址而有不同的值,这就导致了代码段在load到不同地址时,内容(第一句mov指令)会不同,这就导致了无法share。
.text
movl $one_byte, %ebx
movl (%ebx), %eax
.data
.align 4
one_dword:
.byte 1
以ELF格式为例来说明PIC如何避免地址修正。在ELF格式中,各个代码段数据段都有固定的位置,代码段中某条代码的位置到数据段的地址都是固定的。所以如果某条指令要引用一个数据的时候,如果能得到当前指令的地址,就可以通过加上到数据段的固定偏移来找到这个数据。ELF格式中引入了Global Offset Table (GOT)来实现这个机制。GOT就是一系列地址的数组,包含了所有全局数据的地址。
| |
|---------------|
| data_A |
Data section |---------------|
| data_B |
------->|---------------|
| |
| ... |
| |
|---------------|
| addr of data_A|
|---------------|
GOT base| addr of data_B|
------->|---------------|
| |
| |
| |
| ... |
Text section | |
------->|---------------|
根据GOT,经过下面的三步,就可以寻址到特定数据。
1)得到当前指令的地址
2)根据固定的偏移找到GOT的地址
3)根据数据的符号固定偏移找到该数据的地址
下面的代码实现了这一过程:
call tmp_label /* will push EIP to stack */
tmp_label:
popl %ecx /* %ecx now has address of $tmp_label */
addl $GOT_TABLE_OFFSET_TO_CUR +[. - $tmp_label], %ecx /* %ecx now has the base address of GOT */
上面的代码中,GOT_TABLE_OFFSET_TO_CUR是所在代码的地址到GOT基地址的固定偏移,这个是compiler & linker决定的。执行上面最后一句后,%ecx里已经是GOT的基地址了,然后就可以根据%ecx寻址数据:
movl data_symbol_offset(%ecx), %ebx /* %ebx now has address of target data */
movl (%ebx), %eax /* move data to %eax */
data_symbol_offset也是在编译连接的过程中确定,是固定值。
一个library中包含了一个全局的GOT,每个library都有自己的GOT。在load时,GOT对每个进程都是私有的,这个和数据段一样。如果某个library引用了另一个library的数据,则该library的GOT里也包含这个数据的地址,只不过这个地址是在dynamic linker在load library的时候负责填入的,编译链接阶段无法确定这个值,ELF格式中定义了特定的类型来表示这种数据。
3)一个具体例子
写一个简单的例子来验证PIC的实现。libtest2.so只包含一个数据,被libtest.so引用,main调用libtest.so里的test函数。
kai@opensolaris-kai:~/src/tmp$ cat test.c
static int data = 1;
extern int test2_data;
void test(int p1, int p2, int p3)
{
data += p2;
test2_data += p1;
}
kai@opensolaris-kai:~/src/tmp$ cat test2.c
int test2_data = 3;
kai@opensolaris-kai:~/src/tmp$ cat main.c
void test(int p1, int p2, int p3);
int main(void)
{
int i = 5;
test(2, i, 2);
}
kai@opensolaris-kai:~/src/tmp$ make
gcc -nostdlib -shared -fPIC -s -o libtest2.so test2.c
gcc -nostdlib -shared -fPIC -s -o libtest.so test.c -ltest2
gcc -o main main.c -ltest
objdump -D libtest2.so > test2.S
objdump -D libtest.so > test.S
objdump -D main > main.S
反汇编后的test.S:
Disassembly of section .text:
0000056c <test>:
56c: 55 push %ebp /* %ebp指向caller的stack frame base pointer */
56d: 89 e5 mov %esp,%ebp /* %esp指向test的stack frame base pointer,存进%ebp,用来访问传给test的参数 */
56f: 53 push %ebx
570: e8 00 00 00 00 call 575 <test+0x9> /* 地址575会被压入stack */
575: 5b pop %ebx /* %ebx现在等于地址575 */
576: 81 c3 2b 00 01 00 add $0x1002b,%ebx /* %ebx现在等于GOT的base address,0x1002b是compiler & linker计算的 */
57c: 8b 45 0c mov 0xc(%ebp),%eax /* 把p2的值move到%eax,传给test的三个参数分别在%ebp+0x8, %ebp + 0xc, %ebp + 0x10 */
57f: 01 83 10 00 00 00 add %eax,0x10(%ebx) /* %ebp+0x10直接指向了libtest.so里的data,这里没有经过GOT去寻址,猜测应该是经过优化了 */
585: 8b 8b 0c 00 00 00 mov 0xc(%ebx),%ecx /* %ecx, %edx都指向libtest2.so里的test2_data */
58b: 8b 93 0c 00 00 00 mov 0xc(%ebx),%edx
591: 8b 45 08 mov 0x8(%ebp),%eax /* move test2_data到%eax */
594: 03 02 add (%edx),%eax /* add p1 to %eax */
596: 89 01 mov %eax,(%ecx) /* store %eax back to test2_data */
598: 5b pop %ebx
599: 83 c4 00 add $0x0,%esp /* ? */
59c: c9 leave
59d: c3 ret
Disassembly of section .got:
000105a0 <_GLOBAL_OFFSET_TABLE_>:
105a0: 94 xchg %eax,%esp
...
Disassembly of section .data:
000105b0 <_edata-0x4>:
105b0: 01 00 add %eax,(%eax)
...
一个问题:对于library自身数据的访问,似乎不需要GOT?因为可以数据段到代码的偏移也是固定的,完全可以直接得到数据段基地址。
给出执行了push %ebx后的stack的情况(期间有一次地址575的push和pop)。
SFBP = stack frame base pointer
| |
stack top when enter main ---> |-----------------------|
| |
| |
| |
| |
|-----------------------|
| p3 |
|-----------------------|
| p2 |
|-----------------------|
| p1 |
|-----------------------|
| return address in main|
stack top when enter test ---> |-----------------------|
| SFBP of main |
|-----------------------| <--- EBP
| original %ebx |
|-----------------------| <--- ESP
| |
| |
4) Advantage & disadvantage of PIC
PIC的好处显然是在load时可以被load到任意位置而不需要代码段的地址修正,代码可以被不同process share而只留有一份代码在内存中。坏处是增加了额外的对GOT的引用,以及一系列必须的额外的开销(比如对代码段地址的call 和pop等),使得代码运行速度比飞PIC的慢。
另外,由于GOT里的数据地址也是需要在load时计算的,所以对于一些拥有大量数据的library,load的时间也会变慢。
一个问题:对于library自身数据的访问,似乎不需要GOT?因为可以数据段到代码的偏移也是固定的,完全可以直接得到数据段基地址。这似乎可以大大减少load时对GOT里地址的修正所带来的额外时间的花销。
5) Reference
a. Intel IA-32 Architectures Manual Volume1 Basic Architecture, CHAPTER 6, PROCEDURE CALLS, INTERRUPTS, AND EXCEPTIONS
b. Linkers & Loaders, Chapter 8, Loading and overlays, Position indenpendent code
c. http://bottomupcs.sourceforge.net/csbu/x3824.htm














 1941
1941











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









