







算法分析
@(基础)[概念|学习笔记|用途|渐进符号|内存引用计数|排序分析]
前言:开始对自己的学习做一个记录,看看自己的知识图谱是什么样子。如果可以帮助到其他人是也是一件非常开心的事,更多的是对学习的东西的一个整理。
学习地址:网易公开课的算法导论。链接:
http://open.163.com/special/opencourse/algorithms.html
Analysis of Algorithms
@[概念]
The analysis of algorithms is the theretical study of computer program prtformance and resource usage.
What is mot import than performance ?
· Correctness 正确性
· Simplicity 简洁行
· Maintainability 可维护性
· Cost 成本
· Stability 稳定性
· Robustness of the software 软件健壮性
· Features 特性
· Functionality 功能性
· Modularity 模块化
· Security 安全
· User-friendliness 友好性
It‘s almost more important than performance .Why study algorithms and performance?
· One is often performance measures the line between the feasible and infeasible.
· What you find is algorithms are one the cutting edge of entrepreneurship.解决问题的最前沿
· Algoritms give you a language for talking about program behavior.
@[渐进符号]
Big IDEA : Asymptotic analysis(渐进分析)
- Ignore machine-dependent constants
忽略掉那些依赖机器的常量 - Look at the growth of T(n) as n -> ∞
不是检查实际的运行时间,而是关注运行时间的增长
Asymptotic notation(渐进符号)
θ(Theta) - notation : drop low order terms and ignore leading constants
弃去他的低阶项,并忽略前面的常数因子
Ex:
As n -> ∞ , θ(n^2) algorithm always beats θ(n^3) algorithm .
It satisfes out issue of being able to compute both relative and absolute speed.
他能一举满足我们对相对和绝对速度的双重重要比较要求
Even if you can run the θ(n^2) algoritm on a slow computer and θ(n^3) algoritm on a fast computer. The θ(n^2) will always be faster than θ(n^3)
On different platforms we may get different constants here .
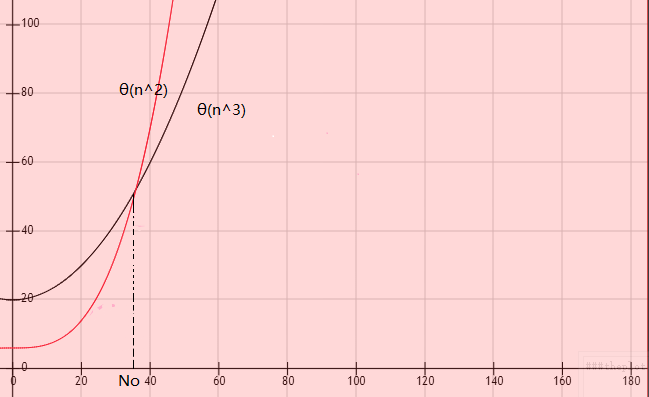
There is always going to be some point No where for everything larger. The θ(n^2) algorithm is going to be cheaper than the θ(n^3) algorithm .
From a enineering of View : sometimes it could be that no is so large the computer aren’t big enough to run the problem . That’s why we, nevertheless , are interested in some of the slower algorithms , because some of the slower algorithms even though they may not asymptotically be slower .They may still be faster on reasonable size of things.
@[内存引用计数]
Counting memorg references : How many times do you actually access some variable.
注:内存引用计数就是 用实际访问多少次某个变量来替代时间的使用长度。
@[排序分析-插入排序]
Problem of sorting :
Insertion sort(插入排序)
We have a sequence {a1,a2 … an} of numbers as input
And out output is a permutation of those number such as a1’ <= a2’ <= … <= an’
//pseudo code
//key : is that there is an invariant that is maintained by this loop each time through
Insertion Sort(A,n)//Sort A[1....n]
for j <- 2 to n
do key <- A[j]
i<-j-1
while(i > 0 and A[i] > key)
do A[i+1] <- A[i]
i<- i-1
A[i+1] <- keyRunning time
· Depends on input (eg : already sorted , reverse sorted)
· Depends on size (eg : 6 elem VS 6*10^9)
we can parameterize things in the input size
we often care of upper bonds(运行上界) also guarantee to the user
kinds of analysis
· Warst-case (usually)
T(n) = max time on any input of size
· Average-case(sometimes)
T(n) = expected time over all inputs of size n
(need a assumption of the statistical distribution 需要假设统计分布)
· Bast-case(bogus)
It can say to be cheating ,we can run fast to use aspecified sets.
What’s insertion sorts worst-cast time?
·Depends on computer
- relative speed (on same machine)
- absoluce speed (on diff machine)
Insertion sort analysis
Warst-case : input resorted sorted
注: 当插入排序是最坏的情况时,每次A[i]都要移动 j-1次 才可以到达正确的位置上去,从 j=2 循环到 j = n次时 ,总共需要做 1+2+3+….+n-1 次可以完成 正好是等差数列求和是个 θ(n^2) 的复杂度。
就是大学里老师说的为什么可以吧一个 for 成是 θ(n) 的复杂度, 当循环嵌套是要提高一个等级的复杂度,以两个for嵌套为例 外层需要 m 次循环, 内层需要 n 次循环总共就需要的是 m * n 次操作, 复杂度是 θ(n^2) 。同理可以推出 k 层嵌套循环复杂度为θ(n^k)。也就是为什么 不鼓励写 循环嵌套的原因。
Is insertion sort fast?
- Moderately so,for small n
- Not at all for large n
@[排序分析-归并排序]
//Describe
Merge sort A[1...n]
// 时间复杂度 θ(1)
If n = 1 , done
//时间复杂度 2T(N/2)
Recursively sort A[1...[n/2]] and A[[n/2]-1 ... n]
//时间复杂度 θ(n)
Merge 2 shorted list nSubroutine Merge
Time(θ) = θ(n)
注: 每一次的归并,两个 List 都是有序的,因为之前的的递归已经帮助该次归并排序完成了两个 List ,归并的时候只需要不断判断两个List 的首个数字的大小,完成一次排序只需要 n 次 , 复杂度为 θ(n) , 如果子链是无序的 每次还要循环查找两个 List 中最小的值,此时复杂度为 θ(n^2)。
Recurrence
Recurrence Tree : When constant >0
注: 使用常量 cn 来代替 θ(n) 所包含的 次数
推出T(n/2) 的复杂都度如下:
令T(n/2) =T(m) = cn (常量)
Tm =··cn···················=··············cn·································=················=··
·······/·····\·································/··············\···························
··T(m/2) ·T(m/2)············cm/2·············cn/2·····················
············································/········\········/···········\················
····························T(m/4)···T(m/4)···T(m/4)···T(m/4)·········
··—–··································cn·······································θ(n)
····|·································/··············\·····································
····|···························cn/2·············cn/2···························θ(n)
h=lgn·····················/········\········/·········\························
····|···················n/4········n/4····n/4··········n/4···················θ(n)
····|····················/···························································
··—–·············θ(1)·························································θ(n)
···································#leaves = n····················································
T(m) = θ(mlgm)
带入公式得:
m = n/2
T(n) = T(m)+ θ(n) = θ(mlgm) + θ(n)= θ(nlgn)















 3749
3749

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









