







awk用术语解释如下:
awk是一个报告生成器,它拥有强大的文本格式化的能力
awk早期是在unix上实现的,所以,我们现在在linux的所使用的awk其实是gawk,也就是GNU awk,简称为gawk,awk还有一个版本,New awk,简称为nawk,但是linux中最常用的还是gawk。
[root@iZbp19obnr01zl0jrho17wZ ~]# ll /usr/bin/awk
lrwxrwxrwx. 1 root root 4 Jul 11 2019 /usr/bin/awk -> gawk
awk其实是一门编程语言,它支持条件判断、数组、循环等功能。所以,我们也可以把awk理解成一个脚本语言解释器。awk 更适合格式化文本,对文本进行较复杂格式处理
awk基本语法如下
awk [options] ‘program’ file1 file2 …
对于上述语法中的program来说,又可以细分成pattern和action,也就是说,awk的基本语法如下
awk [options] ‘Pattern{Action}’ file
从字面上理解 ,action指的就是动作,awk擅长文本格式化,并且将格式化以后的文本输出,所以awk最常用的动作就是print和printf,因为awk要把格式化完成后的文本输出啊,所以,这两个动作最常用。
我们先从最简单用法开始了解awk,我们先不使用[options] ,也不指定pattern,直接使用最简单的action,从而开始认识awk,示例如下:
[root@iZbp19obnr01zl0jrho17wZ ~]# echo hahaha > test
[root@iZbp19obnr01zl0jrho17wZ ~]# awk '{print}' test
hahaha
上面例子中,我们只是使用awk执行了一个打印的动作,将test文件中的内容打印了出来。
现在,我们来操作一下另一个类似的场景。
[root@iZbp19obnr01zl0jrho17wZ ~]# df
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/vda1 41147472 1825828 37418152 5% /
devtmpfs 930572 0 930572 0% /dev
tmpfs 941024 0 941024 0% /dev/shm
tmpfs 941024 428 940596 1% /run
tmpfs 941024 0 941024 0% /sys/fs/cgroup
tmpfs 188208 0 188208 0% /run/user/0
[root@iZbp19obnr01zl0jrho17wZ ~]# df |awk '{print $5}'
Use%
5%
0%
0%
1%
0%
0%
上面例子中的示例没有使用到options和pattern,上图中的awk ‘{print $5}’,表示输出df的信息的第5列,$5表示将当前行按照分隔符分割后的第5列,不指定分隔符时,默认使用空格作为分隔符,细心的你一定发现了,上述信息用的空格不止有一个,而是有连续多个空格,awk自动将连续的空格理解为一个分割符了
awk是逐行处理的,逐行处理的意思就是说,当awk处理一个文本时,会一行一行进行处理,处理完当前行,再处理下一行,awk默认以”换行符”为标记,识别每一行,也就是说,awk跟我们人类一样,每次遇到”回车换行”,就认为是当前行的结束,新的一行的开始,awk会按照用户指定的分割符去分割当前行,如果没有指定分割符,默认使用空格作为分隔符。
$0 表示显示整行 ,$NF表示当前行分割后的最后一列($0和$NF均为内置变量)
注意,$NF 和 NF 要表达的意思是不一样的,对于awk来说,$NF表示最后一个字段,NF表示当前行被分隔符切开以后,一共有几个字段。
也就是说,假如一行文本被空格分成了7段,那么NF的值就是7,$NF的值就是$7, 而$7表示当前行的第7个字段,也就是最后一列,那么每行的倒数第二列可以写为$(NF-1)。
我们也可以一次输出多列,使用逗号隔开要输出的多个列,如下,一次性输出第一列和第二列
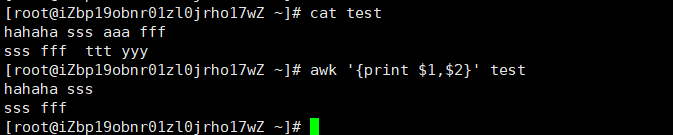
除了输出文本中的列,我们还能够添加自己的字段,将自己的字段与文件中的列结合起来,如下做法,都是可以的。

从上述实验中可以看出,awk可以灵活的将我们指定的字符与每一列进行拼接,或者把指定的字符当做一个新列插入到原来的列中,也就是awk格式化文本能力的体现。但是要注意,$1这种内置变量的外侧不能加入双引号,否则$1会被当做文本输出
我们也可以输出整行,比如,如下两种写法都表示输出整行。
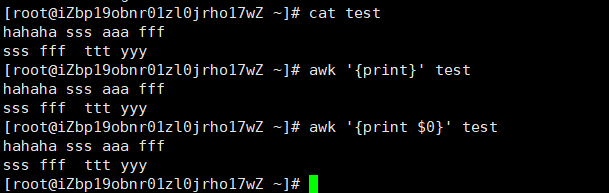
我们说过,awk的语法如下
awk [options] ‘Pattern{Action}’ file
而且我们说过awk是逐行处理的, 刚才已经说过了最常用的Action:print
现在,我们来认识下一Pattern,也就是我们所说的模式
我们先来说两个特殊的模式,普通模式在后面的篇幅中会讲到
AWK 包含两种特殊的模式:BEGIN 和 END。
BEGIN 模式指定了处理文本之前需要执行的操作:
END 模式指定了处理完所有行之后所需要执行的操作:
我们来看一些小例子,先从BEGIN模式开始,示例如下:

上图中,红色标注的部分表示BEGIN模式指定的动作,这部分动作需要在处理指定的文本之前执行,所以,上图中先打印出了”aaa bbb”,当BEGIN模式对应的动作完成后,在使用后面的动作处理对应的文本,即打印test文件中的所有内容,这样解释应该比较清楚了吧。
看完上述示例,似乎更加容易理解BEGIN模式是什么意思了,BEGIN模式的作用就是,在开始逐行处理文本之前,先执行BEGIN模式所指定的动作。以此类推,END模式的作用就一目了然了,举例如下。
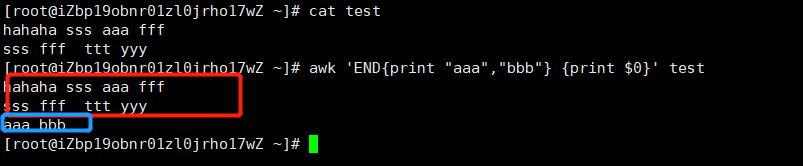
END模式就是在处理完所有的指定的文本之后,需要指定的动作。
AWK分隔符
分隔符可以分为两种,”输入分隔符” 和 “输出分隔符” 。
输入分隔符,英文原文为field separator,此处简称为FS
输入分割符,默认是空白字符(即空格),awk默认以空白字符为分隔符对每一行进行分割。
输出分割符,英文原文为output field separator,此处简称为OFS
awk将每行分割后,输出在屏幕上的时候,以什么字符作为分隔符,awk默认的输出分割符也是空格。
可能只看概念不是那么清楚,往下看几个示例:
我们先看一些”输入分隔符”的小例子
输入分隔符比较容易理解,当awk逐行处理文本的时候,以输入分隔符为准,将文本切成多个片段,默认使用空格,但是,如果一段文字中没有空格,我们可以指定以特定的文字或符号作为输入分割符,比如下图中的例子,我们指定使用”#”作为输入分隔符。

上图中,我们使用了-F 选项,指定了使用#号作为输入分隔符,于是,awk将每一行都通过#号为我们分割了。
除了使用 -F 选项指定输入分隔符,还能够通过设置内部变量的方式,指定awk的输入分隔符,awk内置变量FS可以用于指定输入分隔符,但是在使用变量时,需要使用-v选项,用于指定对应的变量,比如 -v FS=’#’,如下图

其实不管是通过-F选项,还是通过FS这个内置变量,目的都是设置指定的输入分隔符,达到的效果是相同的
输出分隔符
当awk为我们输出每一列的时候,会使用空格隔开每一列,其实,这个空格,就是awk的默认的输出分隔符,下图中红线标注的空格部分,就是awk的默认的输出分隔符。

输出分割符的意思就是:当我们要对处理完的文本进行输出的时候,以什么文本或符号作为分隔符。
我们可以使用awk的内置变量OFS来设定awk的输出分隔符,当然,使用变量的时候要配合使用-v选项,示例如下

AWK变量
对于awk来说”变量”又分为”内置变量” 和 “自定义变量” , “输入分隔符FS”和”输出分隔符OFS”都属于内置变量。
内置变量就是awk预定义好的、内置在awk内部的变量,而自定义变量就是用户定义的变量。
awk常用的内置变量以及其作用如下
FS:输入字段分隔符, 默认为空白字符
OFS:输出字段分隔符, 默认为空白字符
RS:输入记录分隔符(输入换行符), 指定输入时的换行符
ORS:输出记录分隔符(输出换行符),输出时用指定符号代替换行符
NF:number of Field,当前行的字段的个数(即当前行被分割成了几列),字段数量
NR:行号,当前处理的文本行的行号。
FNR:各文件分别计数的行号
FILENAME:当前文件名
ARGC:命令行参数的个数
ARGV:数组,保存的是命令行所给定的各参数
上面描述到的”输入字段分隔符FS和输出字段分隔符OFS在之前的文章中已经解释过了,字段数量NF也大致说了。
RS、ORS、NR、FNR、FILENAME、ARGC、ARGV这些术语对于我们来说是新接触的,但是触类旁通,RS其实与FS类似,ORS与OFS类似,FS是字段输入分隔符,RS是行输入分隔符,OFS是字段输出分隔符,ORS是行输出分隔符,它们的原理都很相似。不要着急,我们来慢慢解释
内置变量NR
NR比较简单,我们先看NR的例子。
首先,如下图所示,test1文件中一共有两行文本,使用空格隔开,第1行有4列,第2行有5列,而内置变量NR表示每一行的行号,内置变量NF表示每一行中一共有几列,那么,也就是说,我们可以通过下例中的方法,得到test1文本中,每一行的行号以及每一行对应的列的数量。
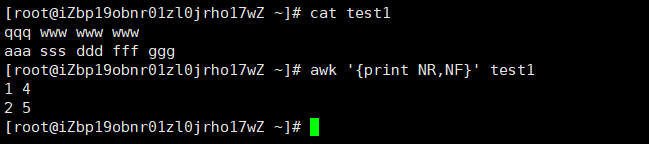
或者,利用NR内置变量,先打印出行号,再打印出整行的内容,相当于为test1中的每一行都添加了行号以后再进行输出,示例如下。

内置变量FNR
FNR这个内置变量是什么意思呢?我们一起来看看。
当我们使用awk同时处理多个文件,并且使用NR显示行号的时候,效果如下图。

从返回结果可以看出,awk处理多个文件的时候,如果使用NR显示行号,那么,多个文件的所有行会按照顺序进行排序。
可是,如果我们想要分别显示两个文件的行号,该怎么办呢,这个时候就会用到内置变量FNR,效果如下。

对比完上述两个示例,你肯定明白了FNR内置变量的作用,没错,它的作用就是当awk处理多个文件时,分别对每个文件的行数进行计数。
内置变量RS
现在,我们来看看RS这个变量,我们说了,RS是输入行分隔符,如果不指定,默认的”行分隔符”就是我们所理解的”回车换行”。
假设,我们不想以默认的”回车换行”作为”行分隔符”,而是想使用空格作为所谓的行分隔符,也就是说,我们想让awk认为,每遇到一个空格,就换行,换句话说,我们想让awk以为每次遇到一个空格就是新的一行。那么我们该怎么做呢?示例如下。

如上图所示,我们先使用了默认的”回车换行”作为”行分隔符”输出了test1文本,这时显示文本一共有2行。
而后来,我们又指定了使用”空格”作为”行分隔符”输出test1文本,这时显示文本一共有8行。
看到了吗?当我们指定使用空格作为”行分隔符”时,在awk解析文本时,每当遇到空格,awk就认为遇到的空格是换行符,于是awk就将文本换行了,而此时人类理解的”回车换行”,对于awk来说并不是所谓的换行符,所以才会出现上图中第4行的现象,即使从人类的角度去看是两行文本,但是在awk的世界观里,它就是一行。
内置变量ORS
我们直接看下面的例子

这个我不解释了,悟一下吧,我也解释不清 哈哈 原谅我
自定义变量
好了,内置变量解释完了,现在我们来看看自定义变量,自定义变量,顾名思义,就是用户定义的变量,有两种方法可以自定义变量。
方法一:-v varname=value 变量名区分字符大小写。
方法二:在program中直接定义。
我们来看一些小例子,即可明白上述两种方法。
通过方法一自定义变量。

使用方法二自定义变量,直接在program中定义即可,但是注意,变量定义与动作之间需要用分号”;”隔开。

AWK格式化
利用awk中的printf动作,即可对文本进行格式化输出,printf动作的用法与printf命令的用法非常相似,只是有略微的不同而已,不过,我们还是从最简单的示例开始看起,首先对比一下print动作与printf动作的区别,示例如下
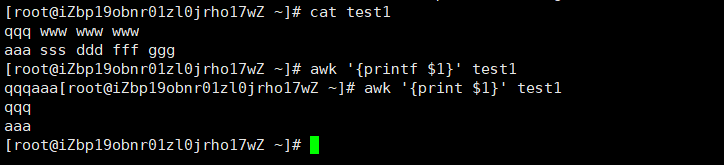
可以看出printf动作与printf命令一样,都不会输出换行符,默认会将文本输出在一行里面。
我们看下面一个例子:

%s是格式替换符,\n是换行符
AWK模式(01)
我们之前一直在提,awk的使用语法如下(我想你已经很熟悉了):
awk [options] ‘Pattern {Action}’ file1 file2 ···
对于options(选项)而言,我们使用过-F选项,也使用过-v选项。
对于Action(动作)而言,我们使用过print与printf,之后的文章中,我们还会对Action进行总结。
对于Pattern(模式)而言,我们在刚开始学习awk时,就介绍了两种特殊模式,BEGIN模式和END模式,但是,我们并没有详细的介绍”模式”是什么,怎么用,而此处,我们将详细的介绍一下awk中的模式。
“模式”这个词听上去文绉绉的,不是特别容易理解,那么我们换一种说法,我们把”模式”换成”条件”,可能更容易理解,那么”条件”是什么意思呢?我们知道,awk是逐行处理文本的,也就是说,awk会先处理完当前行,再处理下一行,如果我们不指定任何”条件”,awk会一行一行的处理文本中的每一行,如果我们指定了”条件”,只有满足”条件”的行才会被处理,不满足”条件”的行就不会被处理。这样说是不是比刚才好理解一点了呢?这其实就是awk中的”模式”。
再啰嗦一遍,当awk进行逐行处理的时候,会把pattern(模式)作为条件,判断将要被处理的行是否满足条件,是否能跟”模式”进行匹配,如果匹配,则处理,如果不匹配,则不进行处理。
看个小例子,就能秒懂,前提是建立在之前知识的基础之上。
如下图所示,test2文件中有3行文本,第一行有4列,第二行有5列,第三行只有2列。而下图的awk命令中,就使用到了一个简单的模式。

上图中,我们使用了一个简单的”模式”,换句话说,我们使用了一个简单的”条件”,这个条件就是,如果被处理的行正好有5列字段,那么被处理的行则满足”条件”,满足条件的行会执行相应的动作,而动作就是{print $0},即打印当前行,换句话说,就是只打印满足条件的行,条件就是这一行文本有5列(NF是内置变量,表示当前行的字段数量,如果你忘了,那么请你重新看一遍之前的文章),而上例中,只有第二行有5列,所以,只有第二行能与我们指定的”模式”相匹配,最终也就只输出了第二行。
举一反三如下

”模式”怎样写,取决于我们想要给出什么样的限制条件。
上图中使用的”模式”都有一个共同点,就是上述”模式”中,都使用到了关系表达式(关系操作符),比如 ==,比如<=,比如>,当经过关系运算得出的结果为”真”时,则满足条件(表示与指定的模式匹配),满足条件,就会执行相应的动作,而上例中使用到的运算符都是常见的关系运算符,我们就不解释了,那么awk都支持哪些关系运算符呢?我们来总结一下。

AWK模式(02正则模式)
先说说什么是正则模式。
见名知义,”正则模式”肯定与”正则表达式”有关,所以,如果想要使用这种模式,则必须先学会在Linux中使用正则表达式,如果你对正则表达式还不是特别熟悉,可以参考我以前的关于正则的文章
前文中提到过,”模式”可以理解为”条件”,当不指定模式时,文本中的每一行都会执行对应的动作,当指定模式时,只有被模式匹配到的、符合条件的行才会执行对应的动作。
那么什么是正则模式呢?正则模式可以理解为,把”正则表达式”当做”条件”,能与正则匹配的行,就算满足条件,满足条件的行才会执行对应的动作,不能被正则匹配到的行,则不会执行对应的动作。如果你觉得我说的不明白,来看一个小例子,就能理解。
不过在进行示例之前,我们先来思考一个小问题。
我们知道,在Linux中,/etc/passwd文件中存放了用户信息,那么假设 ,我们想要从/etc/passwd文件中找出”用户名以root开头”的用户,我们该怎么办呢?

上图中,awk命令在使用正则表达式时,将正则表达式放入了”/ /”中。
其实,这就是我们今天要介绍的”正则模式”,在使用”正则模式”时,文本行如果能够被正则表达式匹配到,就会执行对应的动作,如果没有被正则匹配到,则不会执行对应的动作,而上例中,对应的动作就是{print $0},也就是打印整行,所以,上例中的grep命令与awk命令所实现的效果是完全相同的,那么你可能会问,既然效果完全相同,为什么还要使用awk呢?似乎grep更加简单一些,没错,上例中,grep是更加简单一些,但是不要忘了,awk有自己的优势,就是格式化能力,那么,我们换一个场景,可能使用awk就会更加实用了,示例如下。

猛然一看,上例似乎非常复杂,但是如果你已经掌握了前文中的知识,那么你一定能够看明白,上例中使用了BEGIN模式,并且格式化输出了一行文本作为”表头”,上例中还使用了正则模式,并且格式化输出了/etc/passwd文件中的第一列与第三列(用户名字段与用户ID字段),上例中,只使用了awk一条命令就完成了如下多项工作。
1、从/etc/passwd文件中找出符合条件的行(用户名以root开头的用户)。
2、找出符合条件的文本行以后,以”:”作为分隔符,将文本行分段。
3、取出我们需要的字段,格式化输出。
4、结合BEGIN模式,输出一个格式化以后的文本,提高可读性。
因为我们在处理文本时,往往需要用到正则表达式,所以,awk的正则模式应该会经常用到。
但是需要注意,在使用正则模式时,如果正则中包含”/”,则需要进行转义
行范围模式
在介绍行范围模式之前,先来思考一个小问题,有一个文本文件,文件内容如下。
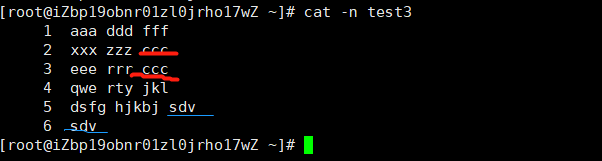
如上图所示,ccc个字符串出现了两次,第一次出现是在第2行,sdv这个名字也出现了两次,第一次出现是在第5行。
假设我想从上述文本中找出,从ccc第一次出现的行,到sdv第一次出现的行之间的所有行,我该怎么办呢?
使用awk的行范围模式,即可完成上述要求,示例如下。

上图中第一种语法是正则模式的语法,表示被正则表达式匹配到的行,将会执行对应的动作。
上图中第二种语法是行范围模式的语法,它表示,从被正则1匹配到的行开始,到被正则2匹配到的行结束,之间的所有行都会执行对应的动作,所以,这种模式被称为行范围模式,因为它对应的是一个范围以内的所有行,但是需要注意的是,在行范围模式中,不管是正则1,还是正则2,都以第一次匹配到的行为准,就像上述示例中,即使ccc在第2行与第3行中都出现了,但是由于正则1先匹配到第2行中的ccc,所以,最终打印出的内容从第2行开始,即使sdv在第5行与第7行中都出现了,但是由于sdv第一次出现在第5行,所以最终打印出的内容到第5行结束,也就是说,最终打印出了第2行到第5行以内的所有行。
AWK动作(01控制语句)
if 条件判断语句
if(条件)
{
语句1;
语句2;
...
}
在awk中,我们同样可以使用if这种语法进行条件判断,只不过,上例中的语法结构是由”多行”组成,而在命令行中使用awk时,我们可以将上例中的”多行”语句写在”一行”中,示例如下。

“if(NR == 1)”中的NR为awk的内置变量,NR为行号之意,所以,”if(NR == 1)”表示行号为1时,条件成立。
“if(NR == 1){ print $0 }”表示行号为1是满足条件,条件满足时,打印整行,换句话说就是只打印第一行。
为什么最外侧还需要有一层大括号呢?
告诉你原因,原因就是·····
没有为什么,就是要这样写,否则会报错。
编程语言中,除了”if”之外,还有”if…else…”或者”if…else if…else”这样的语法,awk中也有这样的用法。
“if…else…”的语法如下:
if(条件)
{
语句1;
语句2;
...
}
else
{
语句1;
语句2;
...
}
“if…else if…else”的语法如下:
if(条件1)
{
语句1;
语句2;
...
}
else if(条件2)
{
语句1;
语句2;
...
}
else
{
语句1;
语句2;
...
}
我们知道,/etc/passwd文件中的第3列存放了用户的ID,root用户ID为0,用户ID大于0的用户都属于非root用户。
所以,我们可以以0为分界线,根据用户ID判断用户是属于root用户还是非root用户
我们可以通过一条awk命令,判断出/etc/passwd文件中的哪些用户属于root用户,哪些用户属于非root用户,示例如下。
















 562
562











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









