







越界访问并不都是坏事,不过只有一种情况。
当用户堆栈过小时,可以通过越界访问使其得到伸展。
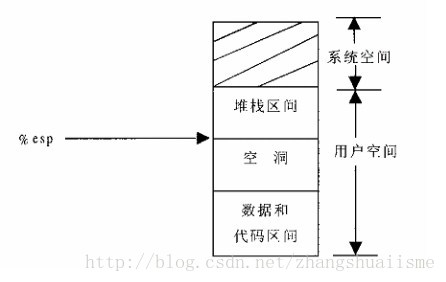
进程地址空间如下图所示(从下到上地址增加),每个进程在逻辑上都有这样一个内存描述图。这种内存描述图是mm_struct结构的图形化描述。它描述了进程的内存需求。
堆栈的扩展引发的缺页异常:
正常的堆栈扩展操作:正常的堆栈操作可能会引发一次缺页异常,(%esp - 4)可能属于堆栈区和数据\代码区之间的空洞,这必然会引发一次缺页异常。
如何判断是否为正常的对扩展操作:
x86 汇编指令有:push和pusha,push是扩展4个字节(%esp-4),pusha是扩展32个字节(%esp-32),所以扩展的数量超过32Byte,就一定是错的了。
if (!(vma->vm_flags & VM_GROWSDOWN))goto bad_area;if (error_code & 4) {/** accessing the stack below %esp is always a bug.* The "+ 32" is there due to some instructions (like* pusha) doing post-decrement on the stack and that* doesn't show up until later..*/if (address + 32 < regs->esp)goto bad_area;}if (expand_stack(vma, address))goto bad_area;//后面有good_area的处理
堆栈的扩展操作:
进程的 task_struct 结构中有一个rlim结构数组,里面规定了每种资源的限制。我们利用一些宏和该数组访问资源的限制值。
rlim[RLIMIT_STACK] 里面存放了进程堆栈的相关限制,expend_stack需要检查这一点。一般情况下,进程的堆栈空间是够用的,但是当动态分配过多时,就不能扩展了,会返回-ENOMEM。
但是,expend_stack只是改变了堆栈区的vma结构,并没有建新的映射。(修改了进程的内存描述)
static inline int expand_stack(struct vm_area_struct * vma, unsigned long address){unsigned long grow;address &= PAGE_MASK;grow = (vma->vm_start - address) >> PAGE_SHIFT;if (vma->vm_end - address > current->rlim[RLIMIT_STACK].rlim_cur ||((vma->vm_mm->total_vm + grow) << PAGE_SHIFT) > current->rlim[RLIMIT_AS].rlim_cur)return -ENOMEM;vma->vm_start = address;vma->vm_pgoff -= grow;vma->vm_mm->total_vm += grow;if (vma->vm_flags & VM_LOCKED)vma->vm_mm->locked_vm += grow;return 0;}
(参见 include/linux/mm.h)
good_area处理:
expend_stack成功后会进入good_area的处理
首先,根据error进行一些可知错误的判断,如果错误就进入bad_area
然后,处理错误
/* * Ok, we have a good vm_area for this memory access, so * we can handle it.. */ good_area: info.si_code = SEGV_ACCERR; write = 0; switch (error_code & 3) { default: /* 3: write, present */ #ifdef TEST_VERIFY_AREA if (regs->cs == KERNEL_CS) printk("WP fault at %08lx\n", regs->eip); #endif /* fall through */ case 2: /* write, not present */ if (!(vma->vm_flags & VM_WRITE)) goto bad_area; write++; break; case 1: /* read, present */ goto bad_area; case 0: /* read, not present */ if (!(vma->vm_flags & (VM_READ | VM_EXEC))) goto bad_area; } /* * If for any reason at all we couldn't handle the fault, * make sure we exit gracefully rather than endlessly redo * the fault. */ switch (handle_mm_fault(mm, vma, address, write)) { case 1: tsk->min_flt++; break; case 2: tsk->maj_flt++; break; case 0: goto do_sigbus; default: goto out_of_memory;}
非错误处理:
这里的非错误处理是指排除已知错误后进行的处理,其实主要就是物理页面未映射。处理包括申请物理页面、交换页面的准备工作
1189 /*1190 * By the time we get here, we already hold the mm semaphore1191 */1192 int handle_mm_fault(struct mm_struct *mm, struct vm_area_struct * vma,1193 unsigned long address, int write_access)1194 {1195 int ret = -1;1196 pgd_t *pgd;1197 pmd_t *pmd;11981199 pgd = pgd_offset(mm, address); //计算pgd表项的指针1200 pmd = pmd_alloc(pgd, address); //由于是32bit,所以pmd的分配一定会成功12011202 if (pmd) {1203 pte_t * pte = pte_alloc(pmd, address); //分配pte表项1204 if (pte)1205 ret = handle_pte_fault(mm, vma, address, write_access, pte);1206 }1207 return ret;1208 }
pte_alloc函数处理:
get_pte_fast 返回的物理页面 是从物理页面缓冲池(内核释放的页面表先不释放物理页面,而是构建一个缓冲池)中获取的
get_pte_slow 是从 get_pte_kernel_slow()分配的
set_pmd处理了一些标志位(在pmd表项中)
但是,此时尚未处理pte表项
120 extern inline pte_t * pte_alloc(pmd_t * pmd, unsigned long address)121 {122 address = (address >> PAGE_SHIFT) & (PTRS_PER_PTE - 1);123124 if (pmd_none(*pmd))125 goto getnew;126 if (pmd_bad(*pmd))127 goto fix;128 return (pte_t *)pmd_page(*pmd) + address;129 getnew:130 {131 unsigned long page = (unsigned long) get_pte_fast();132133 if (!page)134 return get_pte_slow(pmd, address);135 set_pmd(pmd, __pmd(_PAGE_TABLE + __pa(page)));136 return (pte_t *)page + address;137 }138 fix:139 __handle_bad_pmd(pmd);140 return NULL;141 }
handle_pte_fault:
物理页面映射,重点在于do_no_page。
当我们发现page不在内存当中时(pte_present),我们需要执行do_no_page
如果vma->vm_ops->nopage()被指定了,那么我们就执行该函数。但是,有可能为未被指定,那么内核会调用do_anonymous_page()完成物理页面的分配。
1153 static inline int handle_pte_fault(struct mm_struct *mm,1154 struct vm_area_struct * vma, unsigned long address,1155 int write_access, pte_t * pte)1156 {1157 pte_t entry;11581159 /*1160 * We need the page table lock to synchronize with kswapd1161 * and the SMP-safe atomic PTE updates.1162 */1163 spin_lock(&mm->page_table_lock);1164 entry = *pte;1165 if (!pte_present(entry)) {1166 /*1167 * If it truly wasn't present, we know that kswapd1168 * and the PTE updates will not touch it later. So1169 * drop the lock.1170 */1171 spin_unlock(&mm->page_table_lock);1172 if (pte_none(entry))1173 return do_no_page(mm, vma, address, write_access, pte);1174 return do_swap_page(mm, vma, address, pte, pte_to_swp_entry(entry), write_access);1175 }11761177 if (write_access) {1178 if (!pte_write(entry))1179 return do_wp_page(mm, vma, address, pte, entry);11801181 entry = pte_mkdirty(entry);1182 }1183 entry = pte_mkyoung(entry);1184 establish_pte(vma, address, pte, entry);1185 spin_unlock(&mm->page_table_lock);1186 return 1;1187 }
do_anonymous_page函数:
该函数为映射的最低一层
只要是只读页面,一开始都是映射到同一个物理页面empty_zero_page,不管其虚拟地址是什么。
只有可写的页面才会申请物理页面,alloc_page分配了一个物理页面
set_pte为止,虚拟页面到物理页面的映射就建立了。
/* * This only needs the MM semaphore */ static int do_anonymous_page(struct mm_struct * mm, struct vm_area_struct * vma, pte_t *page_table, write_access, unsigned long addr) { struct page *page = NULL; pte_t entry = pte_wrprotect(mk_pte(ZERO_PAGE(addr), vma->vm_page_prot)); if (write_access) { page = alloc_page(GFP_HIGHUSER); if (!page) return -1; clear_user_highpage(page, addr); entry = pte_mkwrite(pte_mkdirty(mk_pte(page, vma->vm_page_prot))); mm->rss++; flush_page_to_ram(page); } set_pte(page_table, entry); /* No need to invalidate - it was non-present before */ update_mmu_cache(vma, addr, entry); return 1; /* Minor fault */ }














 2501
2501











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









