







树(Tree)是n(n>=0)个结点的有限集。
在任意一棵非空树中:
(1)有且仅有一个特定的称为根(Root)的结点;
(2)当n>1时,其余结点可分为m(m>0)个互不相交的有限集T1,T2,...,Tn,其中每个集合本身又是一棵树,并称为根的子树(SubTree)
森林:n棵互不相交的树
二叉树:度最多为2的树
二叉树特点:1>n0 = n2 + 1
2>非空二叉树上第k层上至多有个结点(k >= 1)
3>高度为H的二叉树至多有个结点(H >=1)
满二叉树:对于一棵高度为H的二叉树,将含有个结点的二叉树称为满二叉树
满二叉树特点:满二叉树只有最下面一层含有叶结点,并且除了叶结点外每个结点的度均为2,第i层(1<= i =< H-1)上结点的个数为
完全二叉树:与满二叉树相比,第H层从右边开始连续缺失若干个叶结点,这样的二叉树称为完全二叉树。满二叉树是完全二叉树的特例。
完全二叉树特点:叶结点只可能在层次最大的两层上出现,且最下层的叶结点都集中在左边连续的位置;如果有度为1的结点,只可能有一个,且该结点只有左孩子。
二叉排序树(二叉查找树,BST):左子树结点值 <= 根结点值 =< 右子树结点值
二叉排序树特点:1>若左子树非空,则左子树上所有结点关键字值均不大于根结点的关键字值
2>若右子树非空,则右子树上所有结点关键字值均不小于根结点的关键字值
3>左、右子树本身也是一棵二叉排序树。进行中序遍历的时候可以得到一个非递减的有序序列。
二叉平衡树(AVL树):左右子树的高度差(平衡因子,BF)为-1、0或1
如何调整二叉树成为平衡二叉树:1>LL平衡旋转(右单旋转):
(操作)在结点A的左孩子(L)的左子树(L)上插入新结点,以A为根的子树失去平衡
(调整)将A的左孩子B向右上旋转代替A成为根结点,A结点向右下旋转成为B的右子树的 根结点
2>RR平衡旋转(左单旋转):
(操作)在结点A的右孩子(R)的右子树(R)上插入新结点,以A为根的子树失去平衡
(调整)将A的右孩子B向左上旋转代替A成为根结点,A结点向左下旋转成为B的左子树的 根结点
3>LR平衡旋转(先左后右旋转):
(操作)在结点A的左孩子(L)的右子树(R)上插入新结点,以A为根的子树失去平衡
(调整)将A的左孩子B的右子树的根结点C向左上旋转至B的位置,然后再把C向右上旋转 至A的位置
3>RL平衡旋转(先右后左旋转):
(操作)在结点A的右孩子(R)的左子树(L)上插入新结点,以A为根的子树失去平衡
(调整)将A的右孩子B的左子树的根结点C向右上旋转至B的位置,然后再把C向左上旋转 至A的位置
哈夫曼树(Huffman):在含有N个结点的带权二叉树中,带权路径长度WPL最小的二叉树成为哈夫曼树,也称为最优二叉树。
哈夫曼树的构造过程:1>将这N个结点分别作为N棵仅含一个结点的二叉树,构成森林F
2>构造一个新结点,并从F中选取两棵根结点权值最小的树作为新结点的左右子树,并且将新结点的权值 置为左右子树上根结点的权值之和
3>从F中删除刚才选中的两棵树,同时将新得到的树加入F中
4>重复步骤2,3,直至F中只剩下一棵树为止
哈夫曼树的特点:1>每个初始结点最终都成为叶结点,并且权值越小的结点到根结点的路径长度越大
2>构造过程中共新建了N-1个结点,因此哈夫曼树中结点总数为2N-1
树中每个节点表示表中的一个记录,节点里的值为该记录在表中的位置,通常称这个折半查找过程的二叉树为折半判定树。
二叉判定树的节点是各个元素的下标或在表中的位置。比如有一个文件【11,22,33,44,55,66】,我想查找44是否在该文件中,利用折半查找的思想,可以将此文件构造成一个二叉判定树。
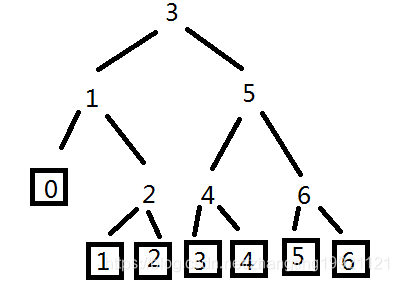
根节点是3,注意二叉判定树的节点是下标或位置,这里不能写33。
折半判定树的构造方法:1>当n=0时,折半查找判定树为空;
2>当n>0时,折半查找判定树的根结点为mid=(n+1)/2,
根结点的左子树是与有序表r[1] ~ r[mid-1]相对应的折半查找判定树,
根结点的右子树是与r[mid+1] ~ r[n]相对应的折半查找判定树。
折半判定树的特点:1>任意两棵折半查找判定树,若它们的结点个数相同,则它们的结构完全相同
2>具有n个结点的折半查找树的高度为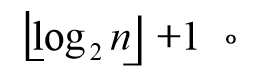
折半判定树的性质: 1>任意结点的左右子树中结点个数最多相差1
2>任意结点的左右子树的高度最多相差1
3>任意两个叶子所处的层次最多相差1
B树(B-树):是一种多路平衡查找树,一棵m阶的B-树,或为空树,或为满足下列特性的m叉树:
1>根结点的子树数:[2,m],所包含关键字数:[1,m-1]
2>除根结点以外的所有非叶子结点的子树数:[m/2向上取整,m],所包含关键字数:[m/2向上取整 - 1,m -1]
3>非叶子结点的关键字个数=指向其子树的指针个数-1
4>所有叶子结点位于同一层
5>所有的叶结点都在同一层,并且不带信息(可以看作是外部结点或者类似于者半查找判定树中的失败结点,实际上这些结点不存在,指向这些结点的指针为空)。
6>包含n个关键字,高度为h,阶数为m的B-树的树高(在计算B树高度时,叶结点所在层不计算在内):logm(n+1)<= h<=log(ceil(m/2)) (n+1)/2 + 1 (ceil(m/2)表示m/2向上取整)
例:一棵3阶的B-树,
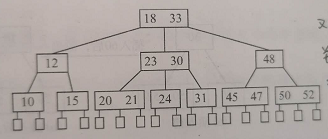
B-树检索指定数据的过程:首先从根节点进行二分查找,如果找到则返回对应结点的索引位置,否则对相应区间的指针指向的结点递归进行查找,直到找到结点或找到null指针,前者查找成功,后者查找失败。
BTree_Search(node, key) {
if(node == null) return null;
foreach(node.key)
{
if(node.key[i] == key) return node.data[i];
if(node.key[i] > key) return BTree_Search(point[i]->node);
}
return BTree_Search(point[i+1]->node);
}
data = BTree_Search(root, my_key);B+树:B+树是B-树的变体,也是一种多路平衡查找树。其定义基本与B-树相同,除了:
1>非叶子结点的子树指针与关键字个数相同。
2>所有的叶子结点包含了全部的关键字及每个关键字所指向相应记录的指针,叶子结点中将关键字按非递减的顺序进行排列,并且相邻叶子结点顺序链接起来(为所有叶子结点增加一个链指针),所有的叶子结点在同一层。
3>所有的分支结点(可以看成是索引的索引)中仅包含其子树中关键字的最大值以及指向其子树的指针。
4>有两个头指针:一个指向根结点,一个指向关键字最小的叶结点。(因此,B+树的查找运算可以分为两类,一是从最小关键字开始的顺序查找,一是从根结点开始进行的多路查找。)
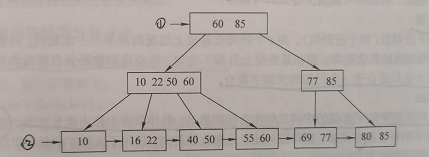
B+树的构建过程:
以4阶为例:依次插入43,48,36,32,37,49,28
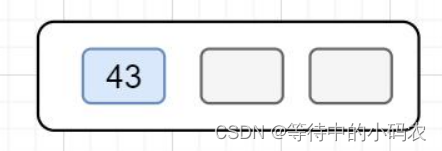
第一步:插入43
第二步:插入43,36

第三步:
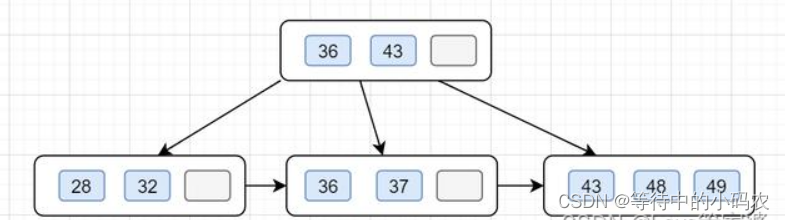
这时候跟节点拥有3个关键字,已经满了
继续插入 32,发现当前节点关键字已经不小于阶数4了,于是分裂 第4/2=2(下标0,1,2)个,也即43上移到父节点。

第四步:插入37,49,前节点关键字都是还没满的,直接插入

第五步:插入28,发现当前节点关键字也是不小于阶数4了,于是分裂, 第 4/2=2个,也就是36上移到父节点,因父子节点只有2个关键值,还是小于4的,所以不用继续分裂,插入完成。
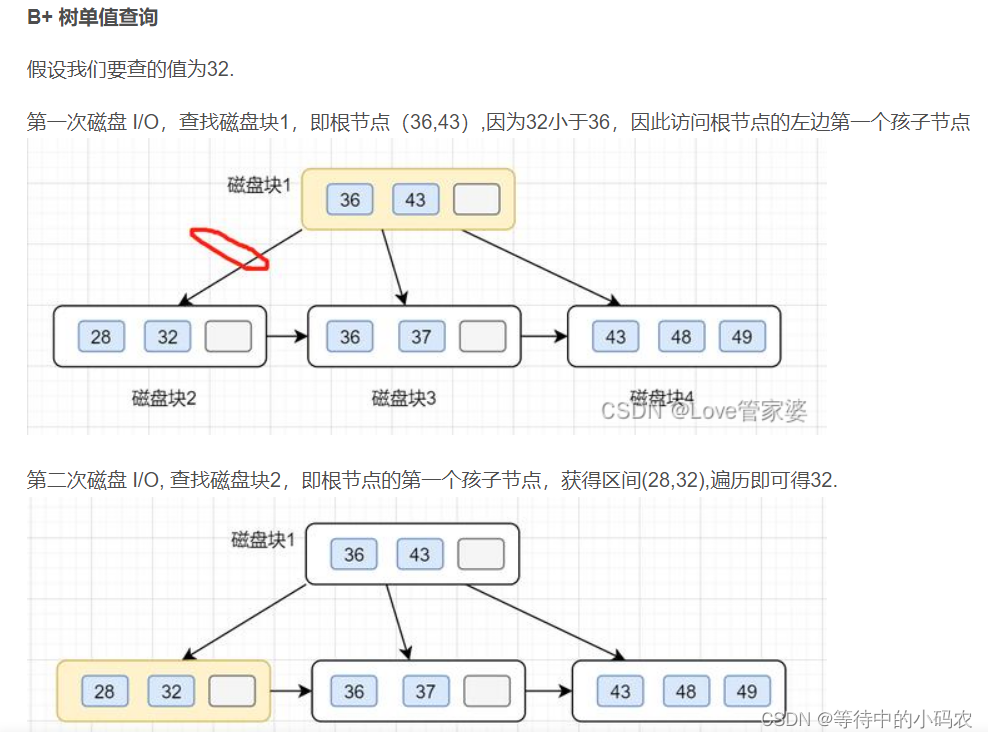
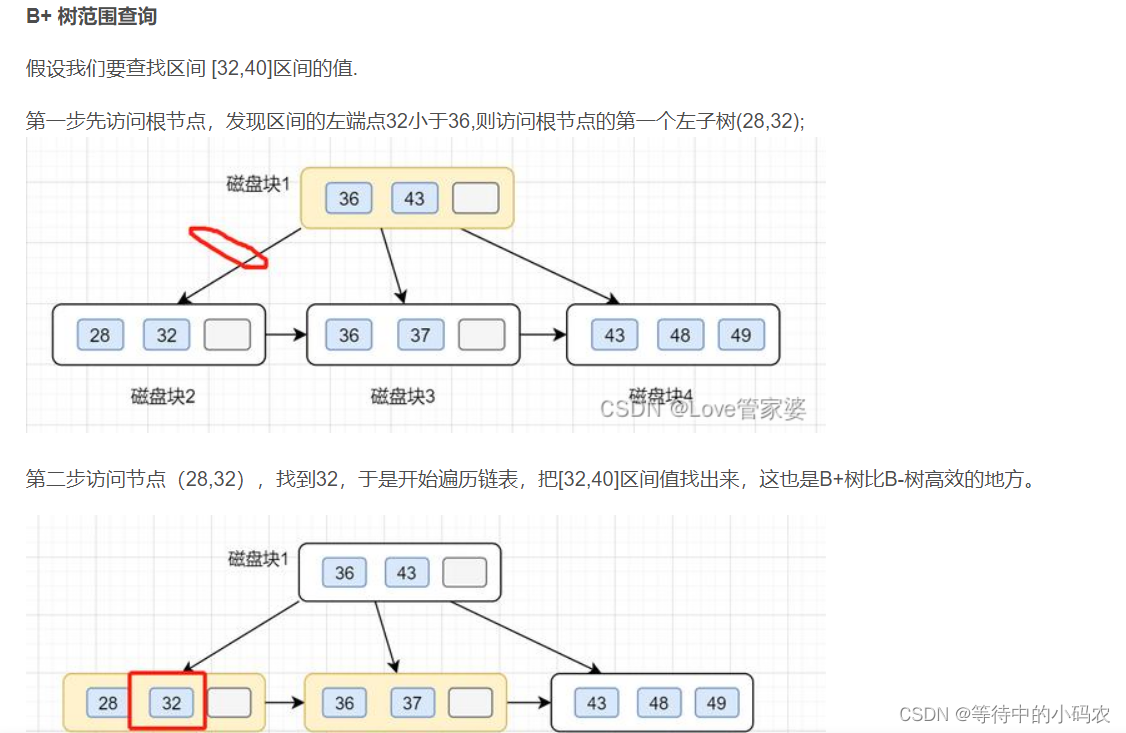
m阶B-树与m阶B+树的区别:
1>在B+树中,具有n个关键字的结点含有n课子树,即每个关键字对应一棵子树;
在B-树中,具有n个关键字的结点含有n+1课子树。
2>在B+树中,每个非根结点关键字个数n的范围是[m/2向上取整,m](根结点:[1,m]);
在B-树中,每个非根结点关键字个数n的范围是[m/2向上取整 - 1,m - 1](根结点:[1,m - 1])。
3>在B+树中,所有非叶子结点仅起到索引作用,即结点中的每个索引项只含有对应子树的最大关键字和其指向该子树的指针,不含有该关键字对应记录的存储位置。
4>在B+树中,叶子结点包含了全部的关键字,即其他非叶子结点中的关键字也包含在叶结点中;
在B-树中,叶子结点中所包含的关键字与其他节点包含的关键字是不重复的。
5>B+树的查找、插入和删除操作与B+树基本类似,只是在B+树查找的过程中,如果非叶子结点上的关键字值等于给定值时并不终止,而是继续向下查找直到叶子结点上的该关键字为止。所以,无论查找成功与否,每次查找都是一条从根结点到叶子结点的路径。
红黑树:
java面试题 --- 红黑树_等待中的小码农的博客-CSDN博客_java 红黑树面试题














 361
361











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









