







一、
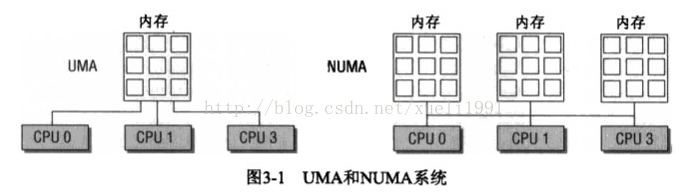
UMA,一致性内存访问(uniform memory access),将可用内存以连续方式组织起来。SMP系统的每个处理器访问的都是同一个内存区。
NUMA,非一致性内存访问,总是多处理器计算机。系统各个CPU都有本地内存,可支持特别快速的访问。各个处理器之间通过总线连接起来,支持对其他CPU的本地内存的访问,当然比访问本地内存要慢一些。
二、NUMA内存组织
内存划分的图示
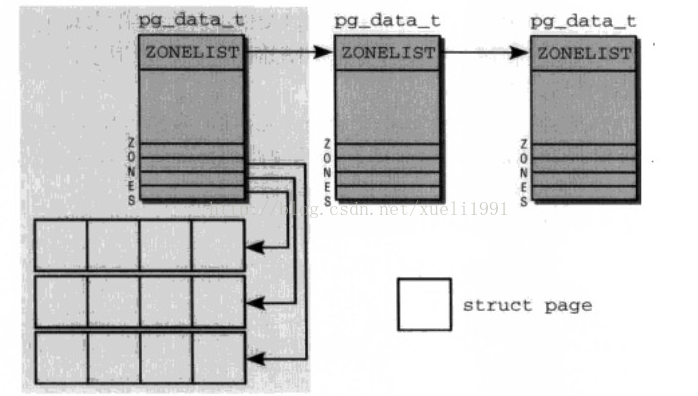
首先,内存划分为结点。每个结点关联到一个处理器,内核用表示为pg_data_t的实例。
其次,各个结点又划分为内存域,是内存的进一步细分。
由于硬件的限制,内核并不能对所有的页一视同仁。有些页位于内存中特定的物理地址上,所以不能将其用于一些特殊的任务。由于存在这些限制,所以内核把页划分为不同的区zone。
ZONE_DMA,DMA的内存域,一般长度是16M。
ZONE_NORMAL,标记了可直接映射到内存段的普通内存域。这是所有体系结构上保证都会存在的唯一内存域。
ZONE_HIGNMEM,标记了超出内核段的物理内存。
各个内存结点保存在一个单链表中,供内核遍历。
出于性能考虑,在为进程分配内存时,内核总是试图在当前的CPU相关联的NUMA结点上进行。但是如果该结点的内存耗尽,每个结点都提供了一个备用列表(struct zonelist),该列表包含了其他结点(和其他的内存域),这样可以为当前结点分配内存。列表项的位置越靠后,就越不适合分配内存。
三、数据结构
1、结点管理pg_datak_t
typedef struct pglist_data {
struct zone node_zones[MAX_NR_ZONES]; //结点中各个内存域的数据结构
struct zonelist node_zonelists[MAX_ZONELISTS];//指定了备用结点及其内存域的列表,以便在当前结点没有可用空间时,在备用结点分配内存
int nr_zones;//结点中不同内存域的数目
struct page *node_mem_map;//执行page实例数组的指针,用于描述结点所有的物理内存页。它包含了所有内存域的页。
#ifndef CONFIG_NO_BOOTMEM
struct bootmem_data *bdata;//系统在启动期间,内存管理子系统初始化之前,内核也需要使用内存。为解决这个问题,内核使用了之后提到的自举内存分配器。bdata指向自举内存分配器数据结构的实例。
#endif
#if defined(CONFIG_MEMORY_HOTPLUG) || defined(CONFIG_DEFERRED_STRUCT_PAGE_INIT)
/*
* Must be held any time you expect node_start_pfn, node_present_pages
* or node_spanned_pages stay constant. Holding this will also
* guarantee that any pfn_valid() stays that way.
*
* pgdat_resize_lock() and pgdat_resize_unlock() are provided to
* manipulate node_size_lock without checking for CONFIG_MEMORY_HOTPLUG
* or CONFIG_DEFERRED_STRUCT_PAGE_INIT.
*
* Nests above zone->lock and zone->span_seqlock
*/
spinlock_t node_size_lock;
#endif
unsigned long node_start_pfn;
/*是该NUMA结点第一个页帧的逻辑编号。系统所有结点的页帧是依次编号的,每个页帧的号码都是
全局唯一的(不只是结点内唯一)。该字段在UMA系统中总是0,因为其中只有一个结点,因此
其第一个结点编号总是0(对于NUMA来说是有多个结点,第一个结点的该字段为0,但是第二个
结点的该字段一定不是0了,因为所有结点的页帧是依次编号的)*/
unsigned long node_present_pages; /* total number of physical pages *///指定了结点中页帧的数目
unsigned long node_spanned_pages; /* total size of physical page
range, including holes */
/*给出了该结点以页帧为单位计算的长度。与上一个字段不一定相同,因为结点中可能有一
些空洞,并不对应真正的页帧*/
int node_id;//全局结点ID,系统中的NUMA结点都是从0开始编号的
wait_queue_head_t kswapd_wait; //交换守护进程的等待队列
wait_queue_head_t pfmemalloc_wait;
struct task_struct *kswapd; /* Protected by
mem_hotplug_begin/end() */
int kswapd_order;
enum zone_type kswapd_classzone_idx;
int kswapd_failures; /* Number of 'reclaimed == 0' runs */
#ifdef CONFIG_COMPACTION
int kcompactd_max_order;
enum zone_type kcompactd_classzone_idx;
wait_queue_head_t kcompactd_wait;
struct task_struct *kcompactd;
#endif
/*
* This is a per-node reserve of pages that are not available
* to userspace allocations.
*/
unsigned long totalreserve_pages;
#ifdef CONFIG_NUMA
/*
* zone reclaim becomes active if more unmapped pages exist.
*/
unsigned long min_unmapped_pages;
unsigned long min_slab_pages;
#endif /* CONFIG_NUMA */
/* Write-intensive fields used by page reclaim */
ZONE_PADDING(_pad1_)
spinlock_t lru_lock;
#ifdef CONFIG_DEFERRED_STRUCT_PAGE_INIT
/*
* If memory initialisation on large machines is deferred then this
* is the first PFN that needs to be initialised.
*/
unsigned long first_deferred_pfn;
/* Number of non-deferred pages */
unsigned long static_init_pgcnt;
#endif /* CONFIG_DEFERRED_STRUCT_PAGE_INIT */
#ifdef CONFIG_TRANSPARENT_HUGEPAGE
spinlock_t split_queue_lock;
struct list_head split_queue;
unsigned long split_queue_len;
#endif
/* Fields commonly accessed by the page reclaim scanner */
struct lruvec lruvec;
unsigned long flags;
ZONE_PADDING(_pad2_)
/* Per-node vmstats */
struct per_cpu_nodestat __percpu *per_cpu_nodestats;
atomic_long_t vm_stat[NR_VM_NODE_STAT_ITEMS];
} pg_data_t;
结点状态:
如果系统中有多个结点,内核会维护一个位图,表示各个结点的状态信息。
enum node_states {
N_POSSIBLE, /* The node could become online at some point */
N_ONLINE, /* The node is online */
N_NORMAL_MEMORY, /* The node has regular memory */
#ifdef CONFIG_HIGHMEM
N_HIGH_MEMORY, /* The node has regular or high memory */
#else
N_HIGH_MEMORY = N_NORMAL_MEMORY,
#endif
N_MEMORY, /* The node has memory(regular, high, movable) */
N_CPU, /* The node has one or more cpus */
NR_NODE_STATES
};
N_NORMAL_MEMORY和N_HIGH_MEMORY表明这个结点的内存域包含了普通内存域和高端内存域
专有函数来设置和清除特定结点的一个比特位:
void node_set_state(int node, enum node_states state)
void node_clear_state(int node, enum node_states state)
参数node一看就知道是结点的全局ID。
此外,宏for_each_node_state(__node, __state)用来遍历处于特定状态的所有结点。如果内核编译为只支持单个结点,则没有结点位图,上述操作该位图的函数都为空
2、内存域 struct zone
enum zone_watermarks {
WMARK_MIN,
WMARK_LOW,
WMARK_HIGH,
NR_WMARK
};
struct zone {
/* Read-mostly fields */
/* zone watermarks, access with *_wmark_pages(zone) macros */
unsigned long watermark[NR_WMARK];
/*是页换出时使用的“水印”。如果内存不足,内核可以将页写到硬盘。这3个数组成员会影响到
交换守护进程的行为。
如果空闲页多余WMARK_HIGH,则内存域的状态是理想的
如果空闲页的数目低于WMARK_LOW,则内核开始讲页换出到硬盘
如果空闲页的数目低于WMARK_MIN,那么页回收工作的压力就比较大,因为内存域中急需空闲页。
这些水印的重要性,之后会讲到*/
unsigned long nr_reserved_highatomic;
/*
* We don't know if the memory that we're going to allocate will be
* freeable or/and it will be released eventually, so to avoid totally
* wasting several GB of ram we must reserve some of the lower zone
* memory (otherwise we risk to run OOM on the lower zones despite
* there being tons of freeable ram on the higher zones). This array is
* recalculated at runtime if the sysctl_lowmem_reserve_ratio sysctl
* changes.
*/
long lowmem_reserve[MAX_NR_ZONES];//为各种内存域预留了若干页,用于一些无论如何都不能失败的关键性内存分配
#ifdef CONFIG_NUMA
int node;
#endif
struct pglist_data *zone_pgdat;//内存域和父结点之间的关联由这个字段建立,指向父结点的pglist_data实例
struct per_cpu_pageset __percpu *pageset;//每CPU页框高速缓存,分为冷热帧,注意每CPU页框高速缓存只针对单页框
#ifndef CONFIG_SPARSEMEM
/*
* Flags for a pageblock_nr_pages block. See pageblock-flags.h.
* In SPARSEMEM, this map is stored in struct mem_section
*/
unsigned long *pageblock_flags;
#endif /* CONFIG_SPARSEMEM */
/* zone_start_pfn == zone_start_paddr >> PAGE_SHIFT */
unsigned long zone_start_pfn;//内存域第一个页帧的索引
/*
* spanned_pages is the total pages spanned by the zone, including
* holes, which is calculated as:
* spanned_pages = zone_end_pfn - zone_start_pfn;
*
* present_pages is physical pages existing within the zone, which
* is calculated as:
* present_pages = spanned_pages - absent_pages(pages in holes);
*
* managed_pages is present pages managed by the buddy system, which
* is calculated as (reserved_pages includes pages allocated by the
* bootmem allocator):
* managed_pages = present_pages - reserved_pages;
*
* So present_pages may be used by memory hotplug or memory power
* management logic to figure out unmanaged pages by checking
* (present_pages - managed_pages). And managed_pages should be used
* by page allocator and vm scanner to calculate all kinds of watermarks
* and thresholds.
*
* Locking rules:
*
* zone_start_pfn and spanned_pages are protected by span_seqlock.
* It is a seqlock because it has to be read outside of zone->lock,
* and it is done in the main allocator path. But, it is written
* quite infrequently.
*
* The span_seq lock is declared along with zone->lock because it is
* frequently read in proximity to zone->lock. It's good to
* give them a chance of being in the same cacheline.
*
* Write access to present_pages at runtime should be protected by
* mem_hotplug_begin/end(). Any reader who can't tolerant drift of
* present_pages should get_online_mems() to get a stable value.
*
* Read access to managed_pages should be safe because it's unsigned
* long. Write access to zone->managed_pages and totalram_pages are
* protected by managed_page_count_lock at runtime. Idealy only
* adjust_managed_page_count() should be used instead of directly
* touching zone->managed_pages and totalram_pages.
*/
unsigned long managed_pages;//上面英文很好解释了这三个字段
unsigned long spanned_pages;
unsigned long present_pages;
const char *name;
#ifdef CONFIG_MEMORY_ISOLATION
/*
* Number of isolated pageblock. It is used to solve incorrect
* freepage counting problem due to racy retrieving migratetype
* of pageblock. Protected by zone->lock.
*/
unsigned long nr_isolate_pageblock;
#endif
#ifdef CONFIG_MEMORY_HOTPLUG
/* see spanned/present_pages for more description */
seqlock_t span_seqlock;
#endif
int initialized;
/* Write-intensive fields used from the page allocator */
ZONE_PADDING(_pad1_)
/* free areas of different sizes */
struct free_area free_area[MAX_ORDER]; //伙伴系统
/* zone flags, see below */
unsigned long flags;
/* Primarily protects free_area */
spinlock_t lock;
/* Write-intensive fields used by compaction and vmstats. */
ZONE_PADDING(_pad2_)
/*
* When free pages are below this point, additional steps are taken
* when reading the number of free pages to avoid per-cpu counter
* drift allowing watermarks to be breached
*/
unsigned long percpu_drift_mark;
#if defined CONFIG_COMPACTION || defined CONFIG_CMA
/* pfn where compaction free scanner should start */
unsigned long compact_cached_free_pfn;
/* pfn where async and sync compaction migration scanner should start */
unsigned long compact_cached_migrate_pfn[2];
#endif
#ifdef CONFIG_COMPACTION
/*
* On compaction failure, 1<<compact_defer_shift compactions
* are skipped before trying again. The number attempted since
* last failure is tracked with compact_considered.
*/
unsigned int compact_considered;
unsigned int compact_defer_shift;
int compact_order_failed;
#endif
#if defined CONFIG_COMPACTION || defined CONFIG_CMA
/* Set to true when the PG_migrate_skip bits should be cleared */
bool compact_blockskip_flush;
#endif
bool contiguous;
ZONE_PADDING(_pad3_)
/* Zone statistics */
atomic_long_t vm_stat[NR_VM_ZONE_STAT_ITEMS];//维护大量有关内存域的统计信息
atomic_long_t vm_numa_stat[NR_VM_NUMA_STAT_ITEMS];
}
之前的内核有一部分字段涉及到换出规则。有些字段对内存域中使用的页进行编目。
如果页访问频繁,则内核认为他是活动的;而不活动页则显然相反。在需要换出页时,
这种区别是很重要的。如果可能的话,频繁使用的页应该保持不动,而多余的不活动页
可以换出而没有什么损害。
3、水印的计算
在计算水印之前,一定要确定内核关键性保留内存的最小值,这个最小值可随着内存增大而非线性增长,并保存在全局变量min_free_kbytes中,图和表可看出保留内存大小。


水印计算代码:水印的初始化是在设备启动时调用
/*
* Initialise min_free_kbytes.
*
* For small machines we want it small (128k min). For large machines
* we want it large (64MB max). But it is not linear, because network
* bandwidth does not increase linearly with machine size. We use
*
* min_free_kbytes = 4 * sqrt(lowmem_kbytes), for better accuracy:
* min_free_kbytes = sqrt(lowmem_kbytes * 16)
*
* which yields
*
* 16MB: 512k
* 32MB: 724k
* 64MB: 1024k
* 128MB: 1448k
* 256MB: 2048k
* 512MB: 2896k
* 1024MB: 4096k
* 2048MB: 5792k
* 4096MB: 8192k
* 8192MB: 11584k
* 16384MB: 16384k
*/
int __meminit init_per_zone_wmark_min(void)
{
unsigned long lowmem_kbytes;
int new_min_free_kbytes;
lowmem_kbytes = nr_free_buffer_pages() * (PAGE_SIZE >> 10);//计算出系统最小内存空闲Kb数
new_min_free_kbytes = int_sqrt(lowmem_kbytes * 16);//这里只是一个计算用户可用最小内存KB数的公式,平方根。就用这个结果赋值给min_free_kbytes
if (new_min_free_kbytes > user_min_free_kbytes) {
min_free_kbytes = new_min_free_kbytes;
if (min_free_kbytes < 128)
min_free_kbytes = 128;
if (min_free_kbytes > 65536)
min_free_kbytes = 65536;
} else {
pr_warn("min_free_kbytes is not updated to %d because user defined value %d is preferred\n",
new_min_free_kbytes, user_min_free_kbytes);
}
setup_per_zone_wmarks();
refresh_zone_stat_thresholds();
setup_per_zone_lowmem_reserve();
setup_per_zone_inactive_ratio();
return 0;
}
static void __setup_per_zone_wmarks(void)
{
unsigned long pages_min = min_free_kbytes >> (PAGE_SHIFT - 10);//计算最小用户可用内存的页数
unsigned long lowmem_pages = 0;
struct zone *zone;
unsigned long flags;
/* Calculate total number of !ZONE_HIGHMEM pages */
for_each_zone(zone) {
if (!is_highmem(zone))
lowmem_pages += zone->managed_pages;
}
for_each_zone(zone) {
u64 tmp;
spin_lock_irqsave(&zone->lock, flags);
tmp = (u64)pages_min * zone->managed_pages;//不要纠结这个公式为什么这么算,这就是一个算法,来计算出page_min的值
do_div(tmp, lowmem_pages);
if (is_highmem(zone)) {
/*
* __GFP_HIGH and PF_MEMALLOC allocations usually don't
* need highmem pages, so cap pages_min to a small
* value here.
*
* The WMARK_HIGH-WMARK_LOW and (WMARK_LOW-WMARK_MIN)
* deltas control asynch page reclaim, and so should
* not be capped for highmem.
*/
unsigned long min_pages;
min_pages = zone->managed_pages / 1024;
min_pages = clamp(min_pages, SWAP_CLUSTER_MAX, 128UL);
zone->watermark[WMARK_MIN] = min_pages;
} else {
/*
* If it's a lowmem zone, reserve a number of pages
* proportionate to the zone's size.
*/
zone->watermark[WMARK_MIN] = tmp;
}
zone->watermark[WMARK_LOW] = min_wmark_pages(zone) + (tmp >> 2);
zone->watermark[WMARK_HIGH] = min_wmark_pages(zone) + (tmp >> 1);
...
spin_unlock_irqrestore(&zone->lock, flags);
}
/* update totalreserve_pages */
calculate_totalreserve_pages();
}
/**
* nr_free_zone_pages - count number of pages beyond high watermark
* @offset: The zone index of the highest zone
*
* nr_free_zone_pages() counts the number of counts pages which are beyond the
* high watermark within all zones at or below a given zone index. For each
* zone, the number of pages is calculated as:
* managed_pages - high_pages
*/
static unsigned long nr_free_zone_pages(int offset)
{
struct zoneref *z;
struct zone *zone;
/* Just pick one node, since fallback list is circular */
unsigned long sum = 0;
struct zonelist *zonelist = node_zonelist(numa_node_id(), GFP_KERNEL);
for_each_zone_zonelist(zone, z, zonelist, offset) {
unsigned long size = zone->managed_pages;
unsigned long high = high_wmark_pages(zone);
if (size > high)
sum += size - high;
}
return sum;
}
nr_free_buffer_pages()->nr_free_zone_pages() ,我们以单结点来看也就是单CPu来看会比较简单。这个函数就算的就是系统可管理内存 - 系统保留内存大小,也就是返回系统当前可分配的空闲页。
PAGE_SIZE在64位系统上是16,这个是一个宏左移计算得出。
由上述代码总结出水印的关键算法:
pages_min = min_free_kbytes >> (PAGE_SHIFT - 10)->
zone->watermark[WMARK_MIN] = (u64)pages_min * zone->managed_pages;
zone->watermark[WMARK_LOW] = min_wmark_pages(zone) + (zone->watermark[WMARK_MIN] >> 2);
zone->watermark[WMARK_HIGH] = min_wmark_pages(zone) + (zone->watermark[WMARK_MIN] >> 1);
以上暂时不明白为什么采用这种算法,不要纠结这个问题,主要了解调用流程和计算方式即可。
4、页帧
页帧代表系统物理内存的最小单位,对物理内存的每一个页都会创建struct page 的有一个实例。
struct page {
/* First double word block */
unsigned long flags; /* Atomic flags, some possibly
* updated asynchronously */
union {
struct address_space *mapping; /* If low bit clear, points to
* inode address_space, or NULL.
* If page mapped as anonymous
* memory, low bit is set, and
* it points to anon_vma object:
* see PAGE_MAPPING_ANON below.
*/
void *s_mem; /* slab first object */
};
/* Second double word */
struct {
union {
pgoff_t index; /* Our offset within mapping. */
void *freelist; /* sl[aou]b first free object */
char *free;
};
/* 页帧计数的一个大联合体 */
union {
#if defined(CONFIG_HAVE_CMPXCHG_DOUBLE) && \
defined(CONFIG_HAVE_ALIGNED_STRUCT_PAGE)
/* Used for cmpxchg_double in slub */
unsigned long counters;
#else
/*
* Keep _count separate from slub cmpxchg_double data.
* As the rest of the double word is protected by
* slab_lock but _count is not.
*/
unsigned counters;
#endif
struct {
union {
/*
* Count of ptes mapped in
* mms, to show when page is
* mapped & limit reverse map
* searches.
*
* Used also for tail pages
* refcounting instead of
* _count. Tail pages cannot
* be mapped and keeping the
* tail page _count zero at
* all times guarantees
* get_page_unless_zero() will
* never succeed on tail
* pages.
*/
atomic_t _mapcount;//内存管理中系统映射的页表计数,用于表示页是否映射
struct { /* SLUB */
unsigned inuse:16;
unsigned objects:15;
unsigned frozen:1;
};//用来表示该也被细分了多少个小的内存对象
int units; /* SLOB */
};
atomic_t _count; /* Usage count, see below. */
};
unsigned int active; /* SLAB */
};
};
/*
* Third double word block
*
* WARNING: bit 0 of the first word encode PageTail(). That means
* the rest users of the storage space MUST NOT use the bit to
* avoid collision and false-positive PageTail().
*/
union {
struct list_head lru; /* Pageout list, eg. active_list
* protected by zone->lru_lock !
* Can be used as a generic list
* by the page owner.
用于各种链表维护这个页帧
*/
struct list_head list; /* slobs list of pages */
struct { /* slub per cpu partial pages */
struct page *next; /* Next partial slab */
#ifdef CONFIG_64BIT
int pages; /* Nr of partial slabs left */
int pobjects; /* Approximate # of objects */
#else
short int pages;
short int pobjects;
#endif
};
struct rcu_head rcu_head; /* Used by SLAB
* when destroying via RCU
*/
/* Tail pages of compound page */
struct {
unsigned long compound_head; /* If bit zero is set */
/* First tail page only */
#ifdef CONFIG_64BIT
/*
* On 64 bit system we have enough space in struct page
* to encode compound_dtor and compound_order with
* unsigned int. It can help compiler generate better or
* smaller code on some archtectures.
*/
unsigned int compound_dtor;
unsigned int compound_order;
#else
unsigned short int compound_dtor;
unsigned short int compound_order;
#endif
};
#if defined(CONFIG_TRANSPARENT_HUGEPAGE) && USE_SPLIT_PMD_PTLOCKS
struct {
unsigned long __pad; /* do not overlay pmd_huge_pte
* with compound_head to avoid
* possible bit 0 collision.
*/
pgtable_t pmd_huge_pte; /* protected by page->ptl */
};
#endif
};
/* Remainder is not double word aligned */
union {
unsigned long private; /* Mapping-private opaque data:
* usually used for buffer_heads
* if PagePrivate set; used for
* swp_entry_t if PageSwapCache;
* indicates order in the buddy
* system if PG_buddy is set.
*/
#if USE_SPLIT_PTE_PTLOCKS
#if ALLOC_SPLIT_PTLOCKS
spinlock_t *ptl;
#else
spinlock_t ptl;
#endif
#endif
struct kmem_cache *slab_cache; /* SL[AU]B: Pointer to slab */
#if defined(CONFIG_32BIT) && defined(CONFIG_MIPS)
struct page *first_page; /* Compound tail pages */
void *cblock_area;
#endif
};
#ifdef CONFIG_MEMCG
struct mem_cgroup *mem_cgroup;
#endif
/*
* On machines where all RAM is mapped into kernel address space,
* we can simply calculate the virtual address. On machines with
* highmem some memory is mapped into kernel virtual memory
* dynamically, so we need a place to store that address.
* Note that this field could be 16 bits on x86 ... ;)
*
* Architectures with slow multiplication can define
* WANT_PAGE_VIRTUAL in asm/page.h
*/
#if defined(WANT_PAGE_VIRTUAL)
void *virtual; /* Kernel virtual address (NULL if
not kmapped, ie. highmem) */
#endif /* WANT_PAGE_VIRTUAL */
#ifdef CONFIG_KMEMCHECK
/*
* kmemcheck wants to track the status of each byte in a page; this
* is a pointer to such a status block. NULL if not tracked.
*/
void *shadow;
#endif
#ifdef LAST_CPUPID_NOT_IN_PAGE_FLAGS
int _last_cpupid;
#endif
}
4、页表
我们知道页表用于建立用户进程的虚拟地址空间和系统物理内存(内存、页帧)之间的
关联
这里只介绍物理寻址的最后一级--页表,
typedef struct { unsigned long pgd; } pgt_t;
最后一级页表中的项不仅包含了只想页的内存位置的指针,还在上述多余比特位包含了与页有关的附加信息。下面介绍一些标记位,在大多数CPU都能找到。
- _PAGE_PRESENT指定了虚拟内存页是否存在与内存中,页不见得总在内存中,页可能已经换出到了交换区
- CPU每次访问页时都会自动设置_PAGE_ACCESSED。内核会定期检查该比特位,以确认使用的活跃程度(不经常使用的页比较适合换出)
- _PAGE_DIRTY表示该页是否是“脏的”,即页的内容是否被修改过。
- _PAGE_USER允许用户空间访问该页,否则只有内核能访问。
- _PAGE_READ、_PAGE_WRITE和_PAGE_EXECUTE指定了普通用户进程是否允许读取、写入和执行该页。
















 2464
2464











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









