







记录下锁如何实现的。
以下是spin_lock()函数的代码调用流程片段:




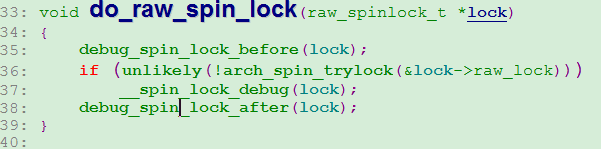
注意__raw_spin_lock这里调用了preept_disable()函数关闭了cpu抢占。这个函数不用关心LOCK_CONTENDED宏的作用,知道这里调用do_raw_spin_lock()函数就可以,参数是lock。

锁的结构介绍:


从__spin_lock_debug开始初见端倪,先尝试for循环4096×HZ次加锁,这里并没有挂死,400多万次的尝试加锁很快的。加锁失败后调用arch_spin_lock进行正式加锁,这里才是关键,才会导致cpu挂死。
static inline unsigned int arch_spin_trylock(arch_spinlock_t *lock)
{
int tmp, tmp2, tmp3;
int inc = 0x10000;
__asm__ __volatile__ (
" .set push # arch_spin_trylock \n"
" .set noreorder \n"
" \n"
"1: ll %[ticket], %[ticket_ptr] \n"
" srl %[my_ticket], %[ticket], 16 \n"
" andi %[now_serving], %[ticket], 0xffff \n"
" bne %[my_ticket], %[now_serving], 3f \n"
" addu %[ticket], %[ticket], %[inc] \n"
" sc %[ticket], %[ticket_ptr] \n"
" beqz %[ticket], 1b \n"
" li %[ticket], 1 \n"
"2: \n"
" .subsection 2 \n"
"3: b 2b \n"
" li %[ticket], 0 \n"
" .previous \n"
" .set pop \n"
: [ticket_ptr] "+" GCC_OFF_SMALL_ASM() (lock->lock),
[ticket] "=&r" (tmp),
[my_ticket] "=&r" (tmp2),
[now_serving] "=&r" (tmp3)
: [inc] "r" (inc));
smp_llsc_mb();
return tmp;
}try lock函数, 通过【bne %[my_ticket], %[now_serving], 3f】这个代码可以看出如果家解锁不对称直接调到标签3,标签3会将【li %[ticket], 0】函数会将ticket作为返回值返回,那么父函数for循环会一直循环多次。
static inline void arch_spin_lock(arch_spinlock_t *lock)
{
int my_ticket;
int tmp;
int inc = 0x10000;
__asm__ __volatile__ (
" .set push # arch_spin_lock \n"
" .set noreorder \n"
" \n"
"1: ll %[ticket], %[ticket_ptr] \n"
" addu %[my_ticket], %[ticket], %[inc] \n"
" sc %[my_ticket], %[ticket_ptr] \n"
" beqz %[my_ticket], 1b \n"
" srl %[my_ticket], %[ticket], 16 \n"
" andi %[ticket], %[ticket], 0xffff \n"
" bne %[ticket], %[my_ticket], 4f \n"
" subu %[ticket], %[my_ticket], %[ticket] \n"
"2: \n"
" .subsection 2 \n"
"4: andi %[ticket], %[ticket], 0xffff \n"
" sll %[ticket], 5 \n"
" \n"
"6: bnez %[ticket], 6b \n"
" subu %[ticket], 1 \n"
" \n"
" lhu %[ticket], %[serving_now_ptr] \n"
" beq %[ticket], %[my_ticket], 2b \n"
" subu %[ticket], %[my_ticket], %[ticket] \n"
" b 4b \n"
" subu %[ticket], %[ticket], 1 \n"
" .previous \n"
" .set pop \n"
: [ticket_ptr] "+" GCC_OFF_SMALL_ASM() (lock->lock),
[serving_now_ptr] "+m" (lock->h.serving_now),
[ticket] "=&r" (tmp),
[my_ticket] "=&r" (my_ticket)
: [inc] "r" (inc));
smp_llsc_mb();
}该函数不仔细分析了,如果连续调用了两次的spin_lock会导致该汇编一直循环在【6: bnez %[ticket], 6b】,导致死锁。
首先这里参考了两篇文章:
2、MIPS中LL/SC指令介绍_mrwangwang的博客-CSDN博客_ll mips
C语言是无法做到原子操作的,这个只能借助CPU来完成,每种架构的CPU实现方案不一样,x86就自带锁总线的汇编,mips的实现就稍微复杂一下,通过两条汇编指令LL和SC来完成原子操作,而arm是锁内存的汇编。
首先我们要支持对于多核处理器,每个核心都有自己独立的一套寄存器,这点很重要。
要明确多核心下对共享数据的冲突访问的发生过程。核心A和核心B都有独立的寄存器Ra和Rb,加入A和B同时读取同一块内存地址中的数据到寄存器Ra和Rb中,Ra+=1,此时Rb也开始进行Rb+=1,最后二者都将数据刷到内存中。但是注意一点,我们是要要内存中的数据进行两次加的操作,就如果引用计数,两个核心都引用了这个内存的数据,但结果上来看该内存的数据仅仅加了1。这就是问题所在。
LL 指令的功能是从内存中读取一个字,以实现接下来的 RMW(Read-Modify-Write) 操作;SC 指令的功能是向内存中写入一个字,以完成前面的 RMW 操作。LL/SC 指令的独特之处在于,它们不是一个简单的内存读取/写入的函数,当使用 LL 指令从内存中读取一个字之后,比如 LL d, off(b),处理器会记住 LL 指令的这次操作(会在 CPU 的寄存器中设置一个不可见的 bit 位),同时 LL 指令读取的地址 off(b) 也会保存在处理器的寄存器中。接下来的 SC 指令,比如 SC t, off(b),会检查上次 LL 指令执行后的 RMW 操作是否是原子操作(即不存在其它对这个地址的操作),如果是原子操作,则 t 的值将会被更新至内存中,同时 t 的值也会变为1,表示操作成功;反之,如果 RMW 的操作不是原子操作(即存在其它对这个地址的访问冲突),则 t 的值不会被更新至内存中,且 t 的值也会变为0,表示操作失败。
那么SC是如何实现RMW是否有冲突的操作的,在一般实现中,处理器有两个专门的域给LL和SC指令,即上文中的“不可见的bit位”以及保存ll操作地址的“寄存器”。在See mips run这本书中说到是利用mips 协处理器检测地址来实现,但具体怎么实现没有说明。也可能在LL之后,处理器核心会监测各种事件,当发生异常或者有别的处理器核心对该地址发了invalid请求时,会将不可见的bit位重置,那么当前操作的处理器核心发现bit被重置了,从而导致了SC的失败。
这是See mips run中的描述:

以上都是mips处理器来实现对内存中的数据进行原子的读写操作,spin_lock就是利用这个来实现。
根据以上理论我们开始分析mips汇编代码:
假如这里连续调用了两次的spin_lock()函数,那么第二次调用的时内存中的数据应该是0x30002,
有[ticket_ptr] "+" GCC_OFF_SMALL_ASM() (lock->lock),看出ticket_ptr中存放的就是lock数据。%表示寄存器操作,
" .set push # arch_spin_trylock \n"
" .set noreorder \n"
" \n"
"1: ll %[ticket], %[ticket_ptr] \n" //mips ll特殊加载到ticket中,ticket=0x30002
" srl %[my_ticket], %[ticket], 16 \n" // ticket=0x30002,my_ticket=0x3
" andi %[now_serving], %[ticket], 0xffff \n" // ticket=0x30002,my_ticket=0x3, now_serving = 0x2
" bne %[my_ticket], %[now_serving], 3f \n" // ticket=0x30002,my_ticket=0x3, now_serving = 0x2,别忘了延迟槽,此时结果是不相等跳到了标签3
" addu %[ticket], %[ticket], %[inc] \n" // ticket=0x40002,my_ticket=0x3, now_serving = 0x2
" sc %[ticket], %[ticket_ptr] \n"
" beqz %[ticket], 1b \n"
" li %[ticket], 1 \n"
"2: \n"
" .subsection 2 \n"
"3: b 2b \n"
" li %[ticket], 0 \n" //ticket 赋值为0,该函数会返回ticket,从父函数可以看出会一直循环
" .previous \n"
" .set pop \n"
有以上分析可以看出,spin_lock流程是通过mips处理器提供的对内存的原子操作来实现对一段代码的防冲突访问,根本上是利用的astomic_add等操作,通过判断内存中的数据来确定该段代码是否被允许进入。
以下是测试代码,测试spin_lock和spin_unlock操作后内存中的值是多少:
函数:

结果:
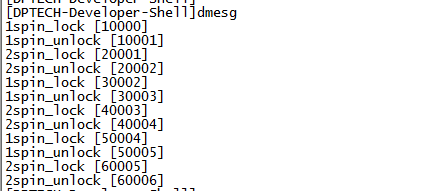
可以看出,加解锁是对不同的字节操作。
2021.7.26
---------------------------------------------------------------------------------------
基于ARM的处理:
arm下的锁结构定义:

在Linux2.6.25以后,spin_lock锁的定义被修改,目的是支持spin锁的排队自旋,名为“FIFO ticket-based”算法的spinlock机制。
以下截图解释如何排队自旋。

这个处理很巧妙,前提是要保证netx++和owner++的原子操作,而所有目前阻塞的cpu都在判断next和owner是否相等,只有相等了才能获得锁,以此来保证排队。
下面分析代码:

88行:预期锁,因为下面一定会用到,直接取出锁,不用等到缓存不命中再取,浪费cpu。
96-98行:
%0=slock(锁的临时变量),
%1=contended(临时变量),
%2=res(临时变量) ,
%3=slock的地址,
%4=1<<16(立即数)
91行:将全局锁的值slock加载到临时变量slock中。
92行:给res赋值为0.
93行:subs的s是只计算结果要更新条件寄存器,比如Z表示0。ROR表示循环右移,这条语句是slock变量 - slock循环右移16位,这里主要就是计算next和owner是否相等,如果相等则Z=1,以供接下来的两个语句使用。
94行:addeq 的eq表示条件执行,如果当前Z=1则执行改语句。如果Z=1表明当前锁的全局变量的next和owner相同,那么当前可以获取锁,并将next++。
95行:同样,eq是条件执行,如果Z=1则表明可以获得锁,此时需要做的是将修改后的锁独占地写到内存中,用到的命令就是strexeq。将%0即锁写入到%3(slock的内存地址),strex命令是有返回值的,返回值写入到%2中,如果内存是当前cpu独占那么返回0,如果不是独占那么返回1到%2.
99行:循环判断res,这样实现了判断next和owner相同并且独占内存时才会跳出循环,表明获得了锁。
解锁:

以上优化后的排队自旋锁仍然有缺点,假设在一个锁激烈竞争的系统中,所有cpu都在同一个变量上自旋申请和释放锁都在同一个变量上修改,根据缓存一致性MESI会导致cache line变得无效,在锁竞争激烈的过程中,会导致严重的CPU告诉缓存颠簸的现象,即多个CPU的cache line反复失效,大大降低系统整体的性能。
进而有优化的办法,即MCS锁机制。
2022.11.13
-------------------------------------------------------------------------------------------------------------------
x86 spin_lock实现(基于MCS的queue锁):
不基于MCS锁存在的问题是smp下多cpu争用锁,会出现MESI消息通知等待,虽然cpu对MESI消息的处理已经很快了,但是对于高并发环境lock操作还是不能忽视,所以排队锁只允许下一个加锁的cpu读取内存信息,其他cpu自选在各自的cache。
queued_spin_loc_slowpath是基于MCS锁的实现,主要是将所有加锁cpu基于每cpu的mcs_spinlock节点单链表排队,只有头节点和占用实际内存,其他节点自旋在各自cpu的cache上。
函数有些关键的点:
- pending标记只为预防同时最开始多个cpu同时进入/* 关键1 */处,保护后续cpu可以排队并自旋等待,其他情况下pending会被清空,高竞争环境下大部分之后看到的pending是清空的;
- mcs_spinlock节点是4个,因为单个cpu只有task, softirq, hardirq和nmi这几个context会竞争,而一个CPU在一种context下,至多试图获取一个spinlock;
- 排队的cpu通过mcs_spinlock节点的locked标记判断是否结束自旋,链表头解锁会将next的mac_spinlock的locked置1.
- 当前lock的tail存的是最后一个加锁的cpu index
加解锁流程不复杂,但是简短的代码考虑的很多情况的各cpu在多种情况下的重入处理,不仅要考虑性能还要考虑功能,代码的每一行在当前版本下经过大佬的处理都不无用代码,所以这里从另一个角度记录下某些流程为什么这么实现。
/* 实现1 */为什么这里用smp_lock_acquire?

READ_ONCE是将变量强转volatile,阻止编译器优化,同时数据不会从寄存器中读取,每次都是从内存读取。smp_mb处理是为了刷新MESI的store buffers和invalidate queue,为什么要加smp_mb?加入多cpu竞争锁,cpu0自旋等待,cpu1解锁,解锁会将lock的locket(不是mac_spinlock的locked)置0 ,涉及到写入操作,cpu1将写操作入store buffer中,同时发invalidate消息给cpu0,cpu0收到消息入队到invalidate queue后回复ack给cpu1,cpu1将数据写入缓存,并将缓存修改为M状态,此时cpu0的invalidate queue处理需要时间,这段时间cpu0会获取不到锁,这对业务上的性能会有影响,虽然smp_mb也会消耗性能,但内核专家应该是做了性能测试对比,smp_mb()可能会更好一些。为什么这里不用原子变量?原子变量读操作只是将变量转换成了volatile并没有考虑smp_mb。
/* 实现2 */为什么需要用READ_ONCE WRITE_ONCE?
为什么不直接赋值?编译器优化选项可能将node->next存入到寄存器中,这样可以防止编译器优化,临时转换volatile比直接定义成volatile节省性能。
void queued_spin_lock_slowpath(struct qspinlock *lock, u32 val)
{
struct mcs_spinlock *prev, *next, *node;
u32 new, old, tail;
int idx;
BUILD_BUG_ON(CONFIG_NR_CPUS >= (1U << _Q_TAIL_CPU_BITS));
if (pv_enabled())
goto queue;
if (virt_spin_lock(lock))
return;
/*
* wait for in-progress pending->locked hand-overs
*
* 0,1,0 -> 0,0,1
*/
if (val == _Q_PENDING_VAL) {
while ((val = atomic_read(&lock->val)) == _Q_PENDING_VAL)
cpu_relax();
}
/*
* trylock || pending
*
* 0,0,0 -> 0,0,1 ; trylock
* 0,0,1 -> 0,1,1 ; pending
*/
/* 关键1 */ for (;;) {
/*
* If we observe any contention; queue.
*/
if (val & ~_Q_LOCKED_MASK)
goto queue;
new = _Q_LOCKED_VAL;
if (val == new)
new |= _Q_PENDING_VAL;
old = atomic_cmpxchg(&lock->val, val, new);
if (old == val)
break;
val = old;
}
/*
* we won the trylock
*/
if (new == _Q_LOCKED_VAL)
return;
/*
* we're pending, wait for the owner to go away.
*
* *,1,1 -> *,1,0
*
* this wait loop must be a load-acquire such that we match the
* store-release that clears the locked bit and create lock
* sequentiality; this is because not all clear_pending_set_locked()
* implementations imply full barriers.
*/
/* 实现1 */ while ((val = smp_load_acquire(&lock->val.counter)) & _Q_LOCKED_MASK)
cpu_relax();
/*
* take ownership and clear the pending bit.
*
* *,1,0 -> *,0,1
*/
clear_pending_set_locked(lock);
return;
/*
* End of pending bit optimistic spinning and beginning of MCS
* queuing.
*/
queue:
node = this_cpu_ptr(&mcs_nodes[0]);
idx = node->count++;
tail = encode_tail(smp_processor_id(), idx);
node += idx;
node->locked = 0;
node->next = NULL;
pv_init_node(node);
/*
* We touched a (possibly) cold cacheline in the per-cpu queue node;
* attempt the trylock once more in the hope someone let go while we
* weren't watching.
*/
if (queued_spin_trylock(lock))
goto release;
/*
* We have already touched the queueing cacheline; don't bother with
* pending stuff.
*
* p,*,* -> n,*,*
*/
old = xchg_tail(lock, tail);
/*
* if there was a previous node; link it and wait until reaching the
* head of the waitqueue.
*/
if (old & _Q_TAIL_MASK) {
prev = decode_tail(old);
/* 实现2 */ WRITE_ONCE(prev->next, node);
pv_wait_node(node);
arch_mcs_spin_lock_contended(&node->locked);
}
/*
* we're at the head of the waitqueue, wait for the owner & pending to
* go away.
*
* *,x,y -> *,0,0
*
* this wait loop must use a load-acquire such that we match the
* store-release that clears the locked bit and create lock
* sequentiality; this is because the set_locked() function below
* does not imply a full barrier.
*
*/
pv_wait_head(lock, node);
while ((val = smp_load_acquire(&lock->val.counter)) & _Q_LOCKED_PENDING_MASK)
cpu_relax();
/*
* claim the lock:
*
* n,0,0 -> 0,0,1 : lock, uncontended
* *,0,0 -> *,0,1 : lock, contended
*
* If the queue head is the only one in the queue (lock value == tail),
* clear the tail code and grab the lock. Otherwise, we only need
* to grab the lock.
*/
for (;;) {
if (val != tail) {
set_locked(lock);
break;
}
old = atomic_cmpxchg(&lock->val, val, _Q_LOCKED_VAL);
if (old == val)
goto release; /* No contention */
val = old;
}
/*
* contended path; wait for next, release.
*/
/* 实现2 */ while (!(next = READ_ONCE(node->next)))
cpu_relax();
arch_mcs_spin_unlock_contended(&next->locked);
pv_kick_node(lock, next);
release:
/*
* release the node
*/
this_cpu_dec(mcs_nodes[0].count);
}1、cpu_relax
反汇编是pause指令,intel针对spin-lock-loop的优化,通知cpu此处是spin-lock循环,不要进行memory reorder,提升流程效率。
intel 文档pause介绍:
Improves the performance of spin-wait loops. When executing a “spin-wait loop,” a Pentium 4 or Intel Xeon processor suffers a severe performance penalty when exiting the loop because it detects a possible memory order violation. The PAUSE instruction provides a hint to the processor that the code sequence is a spin-wait loop. The processor uses this hint to avoid the memory order violation in most situations, which greatly improves processor performance. For this reason, it is recommended that a PAUSE instruction be placed in all spin-wait loops. An additional fucntion of the PAUSE instruction is to reduce the power consumed by a Pentium 4 processor while executing a spin loop.
memory reorder 介绍:
内存乱序是cpu执行的顺序可能与代码编写的顺序不一致。分为多种,比如编译乱序、运行乱序,以防这种情况发生,编译参数或者代码中会设置内存屏障,设置内存屏障后cpu会将数据及时从store中更新到cache line,cache line的修改对性能有影响,pause指令就是通知cpu此处是spin-lock 的空loop,忽略设置的内存屏障。
















 3652
3652











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









