







非阻塞I/O
本章了解原理没有特意去深入学习。
1.概述
套接字默认状态是阻塞的。也就是说当发出一个不能立即完成的套接字调用时,进程将被投入睡眠,等待相应操作的完成 ,一般分为四类:
1.输入操作:包括
read、readv、recv、recvfrom、recvmsg这5个函数。当套接字缓冲区没数据可读时,进程将被投入睡眠状态,直到有数据可达。
2.输出操作:包括write、writev、send、snedto和sendmsg这5个函数。如果发送缓冲区没有空间,则进程将被投入睡眠,因为这些操作需要将应用进程缓冲区的数据拷贝到套接字的发送缓冲区的数据(UDP不存在真正的发送缓冲,内核只是复制数据并把他们沿着协议栈向下传送并依次包装UDP首部和IP首部)。
3.接收连接:accept函数,这个就很熟悉了,当服务器等待客户端外来连接的到来时将被投入睡眠。
4.建立连接:根据一个TCP三路握手的过程,connect函数至少阻塞一个RTT的时间(自己的SYN发送和服务器的ACK的接收)。
2.非阻塞str_cli函数
主要复杂之处在于缓冲区的管理,设想一个场景:
如果标准输入可读,read返回,接着调用write,然而,如果这个时候套接字发送缓冲区已经满了,则write会阻塞,当write阻塞的时间里面,很有可能有来自接收缓冲区的数据可读;
因为要实现非阻塞的目标,函数的设计就很复杂了,这是书中给出的第一个版本所要考虑的缓冲设计
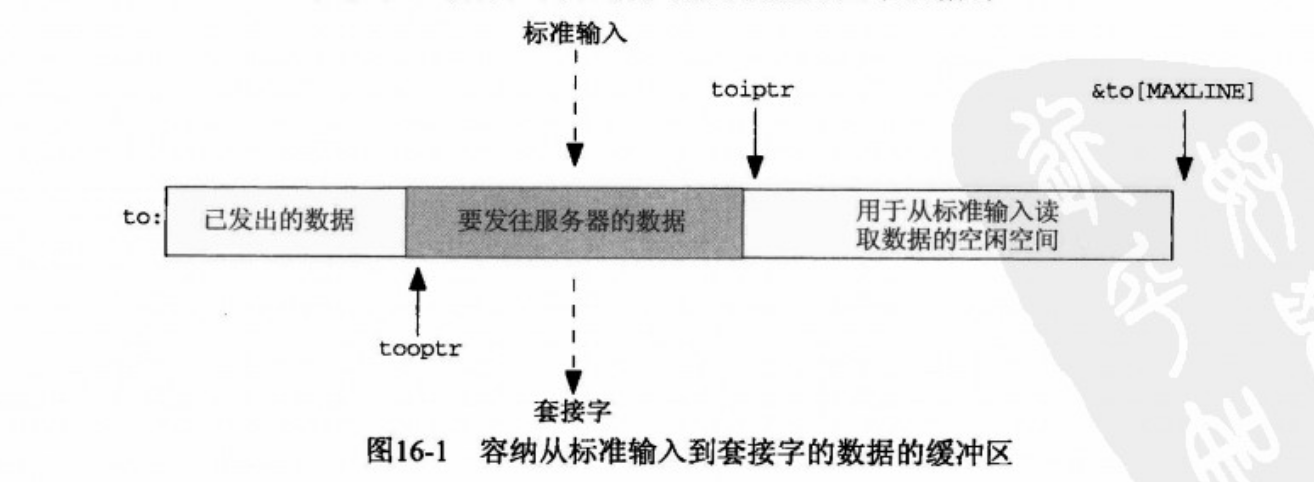
to容纳标准输入到服务器中去的数据。
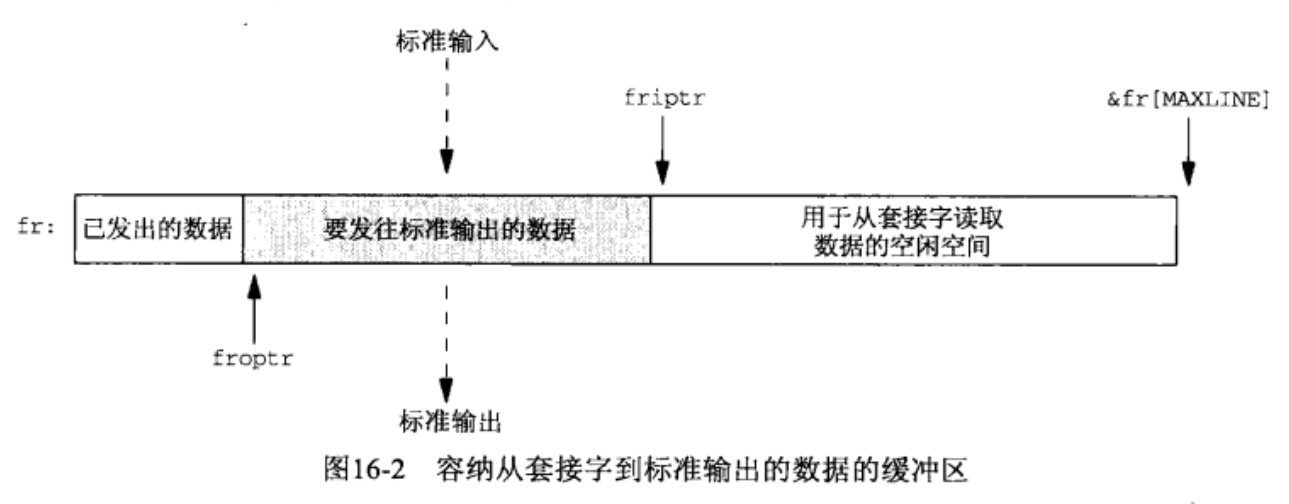
fr容纳服务器回射到标准输出的数据。
这个版本函数比较复杂,基本思路如下:
1.fcntl将标准输入、标准输出和网络套接字描述符都设置为非阻塞模式。
2.调用select之前对4中情况进行判断。
3.四种套接字可读或者可写后的操作,细节先忽略。
遗憾的是没有在我的ubuntu14.04用tcpdump调试出书中的效果。
2.1strcli的简单版本
函数一开始就不把进程划分为父进程和子进程,子进程用来将回射的文本复制到标准输出,父进程用来把标准输入的文本复制到服务器。如图所示:
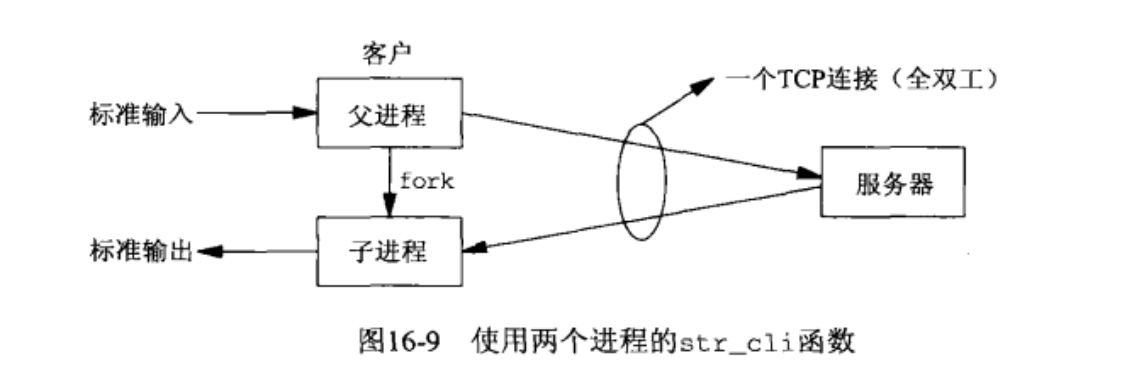
从图中可以看到,尽管只有一个套接字(父子进程共享),但由于TCP是全双工的,并且这个套接字有两个描述符(fork子进程时完成拷贝),所以父进程可以往里写,而子进程可以从中读。
这里需要注意一些边界条件,例如服务器关闭,客户子进程将收到EOF,此时子进程需要给父进程一个SIGTERM以防止父进程仍在执行。
另外,父进程中要用shutdown而不是close,因为此时是多进程共享描述符,引用计数大于1。(习题16.1 参考:高性能网络编程4–TCP连接的关闭)
3.非阻塞connect
当在一个非阻塞的套接字上调用connect的时候,会立刻返回一个EINPROGRESS错误,不过TCP三路握手连接将继续进行。当调用connect后,我们可以使用select检测这个连接成功、失败。非阻塞connect主要有三个用途:
1.三路握手的同时进行其他处理。
2.同时建立多个连接,例如web服务器。
3.减少connect的超时等待时间。
具体过程如下:
1.connect返回错误EINPROGRESS并返回。(这是我们期望的)
2.如果connect返回0,说明已经建立连接,跳过select。(这是客户和服务器在同一主机上的情形)
3.调用select等待套接字变为可读或者可写。
4.如果select返回0则发生超时,返回错误码并关闭套接字。
5.如果描述符可读或可写,则调用getsockopt取得套接字的待处理错误。
利用非阻塞的connect可以构建一个web客户端,例如我们在与一个web服务器建立一个http连接的时候,我们会获取一个homepage,随后这个主页往往还有对其他网页的引用,客户可以通过非阻塞的connect并行地获取多个网页,而不是阻塞的穿行获取,这样就提高了效率。
4.参考
1.《UNP1》
2.http://blog.csdn.net/yusiguyuan/article/details/11640729















 797
797

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









