







本篇是针对 《Lexicon Enhanced Chinese Sequence Labelling Using BERT Adapter》这篇文章的解析
纯属个人理解 欢迎批评指正
首先作者信息

个人理解
个人 对这篇文章的理解是,其通过引入一个单词适配器将词汇信息融入到bert 中间,从而将词汇信息加入给BERT
优点在于:1. 采用了word adapter 将词汇信息加入到bert 模型的中间层
2. 采用的融入方法是直接引入,不是模型融合
模型
总体模型图如下图所示:
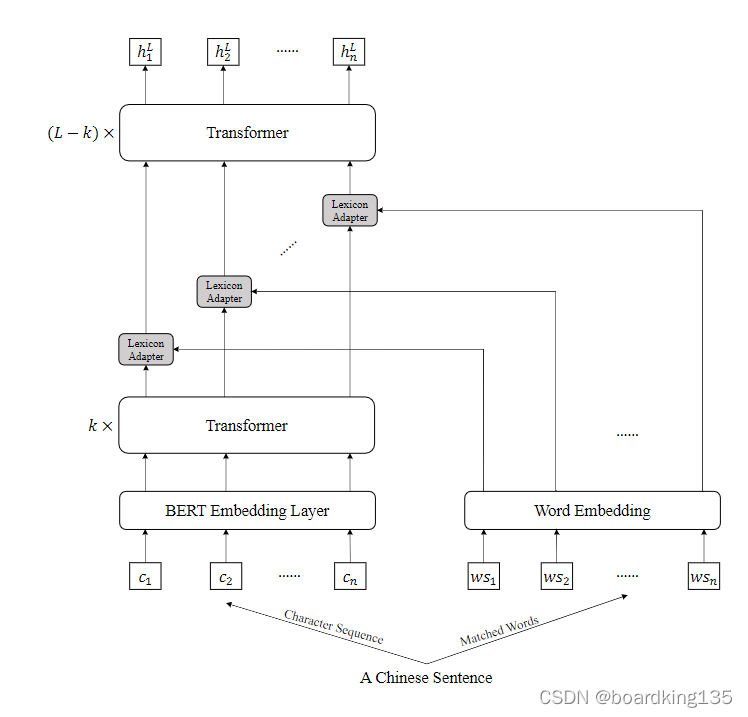
可以看到,左边为Bert 右边为word 融入部分,通过embedding 得到单词向量,然后加入到 word adapter 中。 word adapter的结构信息如下所示:
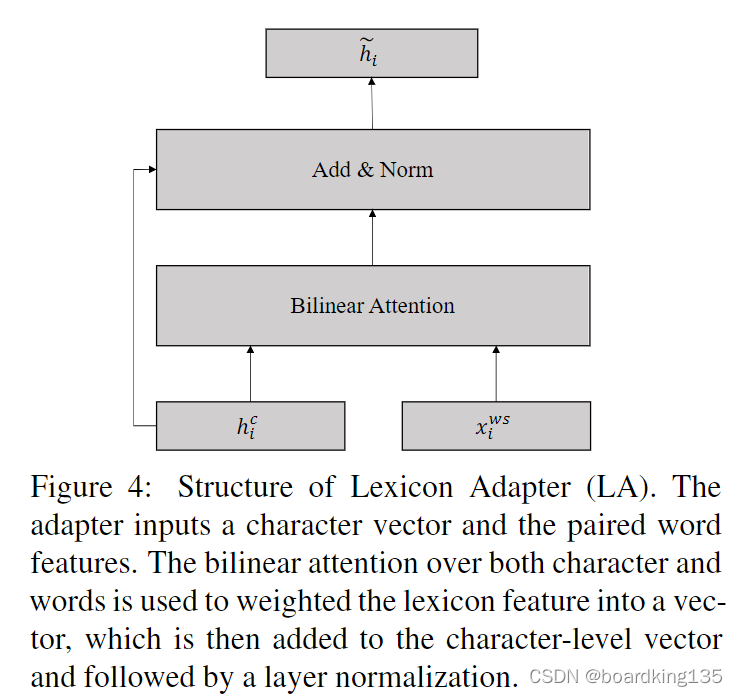
左边h是从Bert 内部直接得到的token 的embedding, 右边的是通过lexicon adapter 得到的单词embedding,通过一个双向线性层和残差网络的连接,得到下一层的输出表示。
效果肯定是所有模型里面最优的
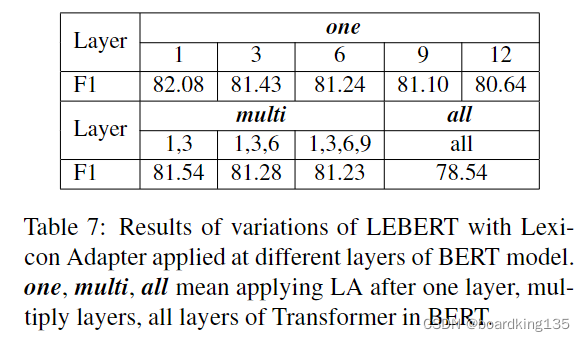
然后作者也做了一个对于融入层的研究,结果如下:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









