







《MECT: Multi-Metadata Embedding based Cross-Transformer forChinese Named Entity Recognition》的论文解析
纯属个人理解,欢迎批评指正
如果有时间的话,会有源码解析,欢迎关注一波
首先,本文的作者信息

个人理解
首先从我个人阅读这篇文章的感觉来看,作者的想法确实挺棒的,在FLAT BERT的基础上通过卷积神经网络提取汉字的笔画embedding ,然后通过一个交叉的transform 和 random attention 的方法将笔画、字符和单词信息融入到模型中。在最后对label 做预测的时候,将cross transformer 笔画一侧的token mask。
关于FLAT 预计这两天会写文章介绍一下,想了解的同学可以看一下我之后写的解读。
这里的motivation 在于 作者认为,在汉语里面,笔画,尤其是偏旁部首是可以引入一部分信息的,例如,草字头的多与植物有关,月字旁的多与身体部位有关。
因此,作者想在词汇的基础上引入笔画 信息。
模型部分
笔画embedding
作者的笔画embedding 个人理解采用的是首先把字里面的笔画提取出来,然后将笔画建立一个随机的embeddding lookup 表,也可能是one-hot 形式,然后利用CNN 将其卷成一个一维的embedding ,维度大小应该与token 的embedding 大小一致
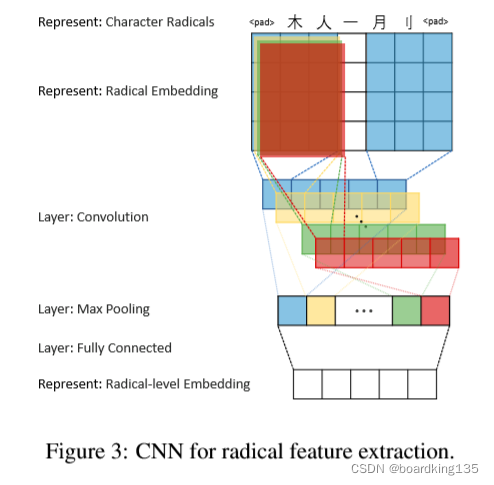
有趣的是,作者通过余弦相似度 证明了这种提取embedding 的方法是有效的。

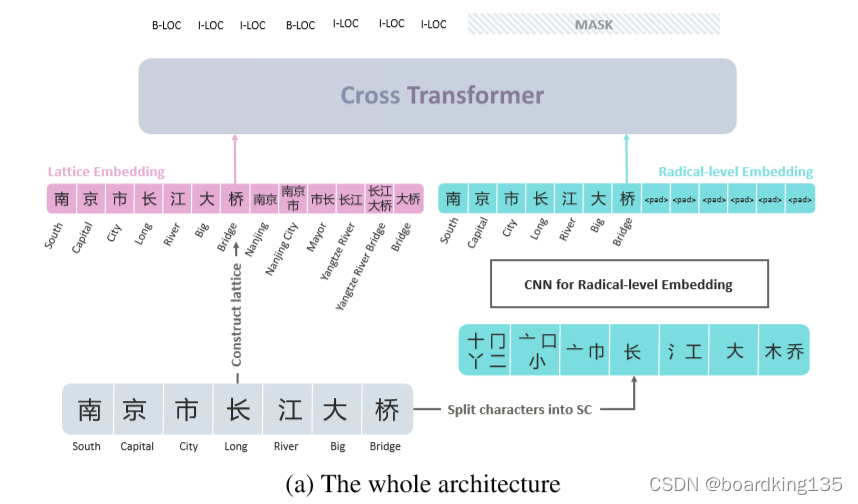
之后采用 cross 的方式将 字符、单词和笔画信息链接起来,其模型架构如下图所示:
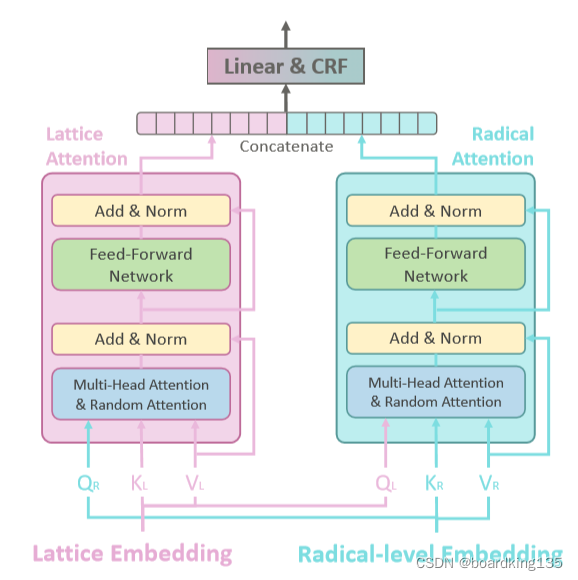
左边为 FLAT模型,右边为笔画的transformer
之所以称为cross,是因为双方做attention 的Q 是来自对方的。
详细的模型信息可以看下图
左边的FLAT 可以看我的另一篇关于FLAT的解析
这里详细说一下右边,右边的embedding 就是由CNN得到的笔画embedding。
其QKV 通过下列公式计算得到:

这里值得注意的是,作者采用的Random attention.

同时作者也做了速度和效率的对比
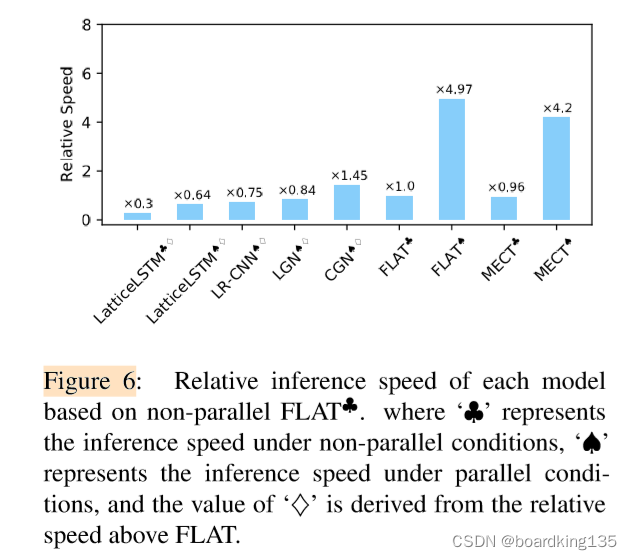
在实验效果方面,这里就不过多介绍了

















 2801
2801

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









