







 本文详细介绍了在Elsevier期刊投稿时,使用LaTeX编辑的论文如何正确上传至EES系统,避免生成PDF时出现乱码的问题。同时分享了一篇论文从投稿到录用的全过程,包括编辑部反馈的一审和二审意见及作者的修订过程。
本文详细介绍了在Elsevier期刊投稿时,使用LaTeX编辑的论文如何正确上传至EES系统,避免生成PDF时出现乱码的问题。同时分享了一篇论文从投稿到录用的全过程,包括编辑部反馈的一审和二审意见及作者的修订过程。
elsevier 投稿时,将 .tex 文件上传到EES,生成的PDF不是正文,而是一堆乱码,经过研究发现那些并非乱码,而是由于自己上传文件的问题。
上传时选择正确的文件以及文件对应的选项如下:
1.源文件(***.tex),选择类型Manuscript。
2.参考文献(***.bib),选择类型Manuscript。
3.样式(***.sty和***.cls),都要上传,选择类型Manuscript。
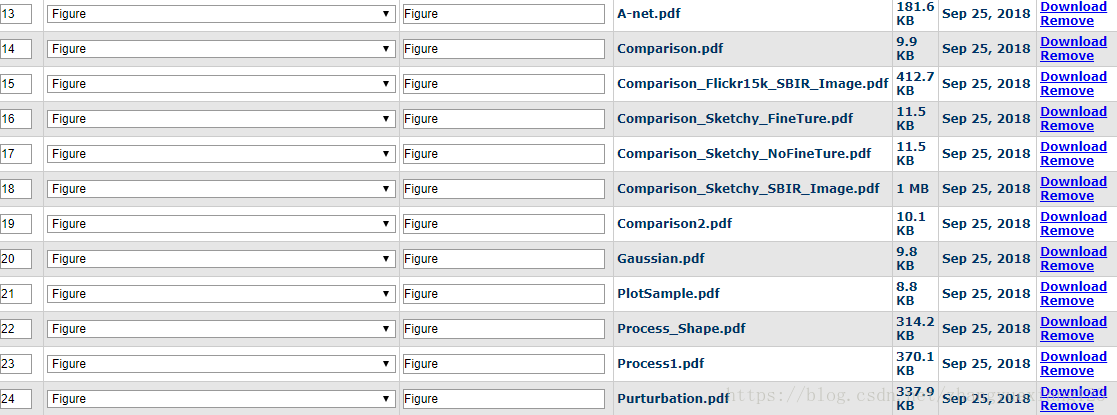
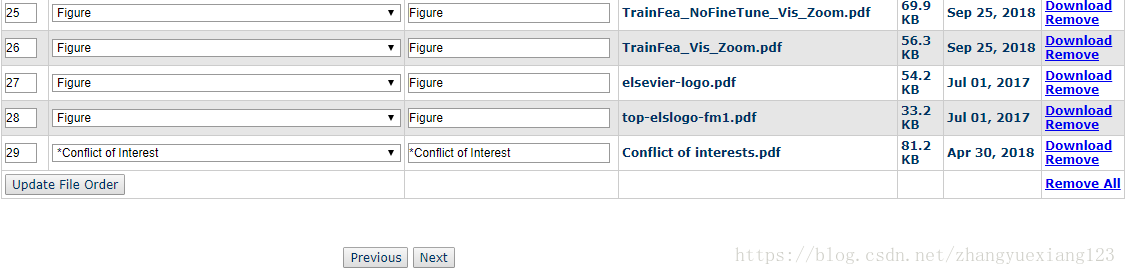
4.图片(命名最好不好重复,PDF或.eps都可以),选择类型Figure。
注意:上传顺序无所谓,所有的都上传成功以后,点击下面的按钮“Update File Order”,网页自动调整顺序。等调整顺序完毕后,再点击Next。
我上传过程中出现的其他问题:
1.\include{graphic}后面用[scale=0.2]而不是[height=4cm]。
上传文件类型选择的截图如下:

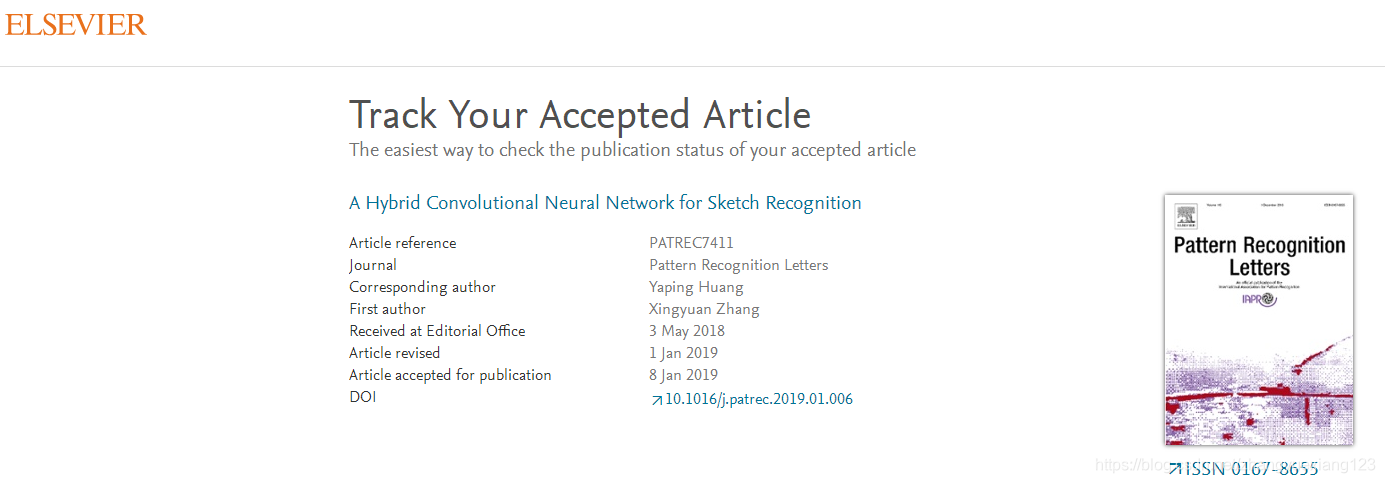
投稿到录用时间如下:
投稿时间:2018年4月30日
一审结果:2018年8月28日
一审意见:
GAE: Both reviewers have recognized the contributions of this paper. However, they still have some concerns. The authors are encouraged to revise the paper carefully and submit back within 45 days.
Reviewer #1: In this paper, a hybrid CNN architecture is proposed by using A-Net and S-Net for Sketch Recognition. The paper is well organized. However, the novelty of this idea is limited to some extent. Some comments are listed as follows
1. It is necessary to demonstrate the experimental results by using A-Net or S-Net.
2. It is better to compare the proposed model with the methods published in 2017 and 2018. That is exact comparison with the state-of-the-arts.
3. The authors should discuss some very related references in the revision. For example, "The Many Shades of Negativity". If the authors sample some negative data points for training, what will the performance be like?
Reviewer #2: This paper proposes a hybrid convolutional neural network for sketch recognition. It develops a point-set based deep neural network, S-Net, to extract shape features of a sketch.
1) As a hybrid method, I think it is important to evaluate the effects of each component on the final performance.
2) In experiments, only simple basic neural networks are compared. The compared baselines are weak. Could the author compare their methods with more advanced or state-of-the-art approaches?
3) The figures are too small. They should be enlarged for more clear presentation.
4) The proposed method is comprised several parameters. Please perform experiments to evaluate the performance variations with the parameters.
5) The presentation of the paper still should be improved further, as current version still includes grammar mistakes, typos and unprofessional presentations.
Please revised carefully revise the paper according to the above comments. I think the paper can be accepted if my above concerns are well solved.
一审提交时间:2018年9月28日
二审结果:2018年12月21日
二审意见:
The Editorial Office has received the decision on your article.
The Reviewers' comments are as follows:
***********************************************************
GAE: One reviewer still has some concerns about this paper. I would like the authors carefully revise these comments. Authors are kindly requested to upload the revised paper in at most 30 days.
Reviewer #2: There are still minor problems should be addressed. 1) The title of the subsection 4.5.5 should be Robustness Test. There should be a space between word and '['] or '9'. For example Table 6 and 7 have the problem. 2) To illustrate the third contribution, I think it is better to present the performance improvement instead of the concrete MAPs. 3) Several references about recent visual analysis are missing. For example, Exploring auxiliary context: discrete semantic transfer hashing for scalable image retrieval doi={10.1109/TNNLS.2018.2797248 and Beyond Trace Ratio: Weighted Harmonic Mean of Trace Ratios for Multiclass Discriminant Analysis;Semantic Pooling for Complex Event Analysis in Untrimmed Videos 4} I suggest the author to conduct a careful proof-reading again, as I still find several presentation problems. For example, there should be a reference for BOW and DCNNs. There should be a space between shapes. and Based on this.
Please carefully revise the paper according to the above concerns.
二审提交时间:2019年1月1日

















 6111
6111

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









