






yarn
1.配置yarn
1.1 配置mapred-site.xml文件
vim etc/hadoop/mapred-site.xml
添加以下内容
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
1.2 配置yarn-site.xml文件
vim etc/hadoop/yarn-site.xml
添加以下内容
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
配置shuffle 反洗牌 主要作用为将混乱的数据合并在一起
1.3 启动
sbin/start-yarn.sh
已知pid查看端口号使用netstart -nlp |grep <进程号>
1.4 修改yarn端口
原因:8088端口容易被挖矿
top查看系统占用资源判断是否被挖矿
通过配置yarn-site.xml修改端口
vim etc/hadoop/yarn-site.xml
添加
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>${yarn.resourcemanager.hostname}:9527</value>
</property>
将端口切换到9527
重启yarn查看端口
stop-all.sh关闭全部
start-all.sh打开全部
1.5 其他
- jps来源
通过which jps查看jps所在文件

- tmp目录下其他文件
主要为pid文件

- 修改配置将pid文件存入/home/zhangyujie/tmp
vim etc/hadoop/hadoop-env.sh
进入文件添加以下内容
export HADOOP_PID_DIR=/home/zhangyujie/tmp
export HADOOP_SECURE_PID_DIR=/home/zhangyujie/tmp
- namenode和secondarynamenode内文件
fsimage 镜像文件
edits 编辑日志文件 - block size
linux块大小128m
假设1亿个小文件,每个文件1kb,集群3副本机制,NameNode记录3亿个元数据
如果维护一个元数据也需要1kb,那么需要3亿kb=30万M=3000G
如果1亿个小文件,合并为100M一个小文件,假如变为1w个大文件,集群3副本只要维护3w个元数据,3wkb
2.run a MapReduce job
- 在自己用户的data下创建一个wordcount.txt写入内容
- 创建wordcount文件夹
hdfs dfs -mkdir -p /wordcount/input
- 将wordcount.txt放入hadoop的input内
hdfs dfs -put wordcount.txt /wordcount/input
- 用官网例子运行wrodcount
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /wordcount/input /wordcount/output
发现报错:配置文件内缺少东西
Please check whether your etc/hadoop/mapred-site.xml contains the below configuration:
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
将提示的配置文件加入到提示的文件内再次运行
通过9527端口(原8088端口)查看运行状态
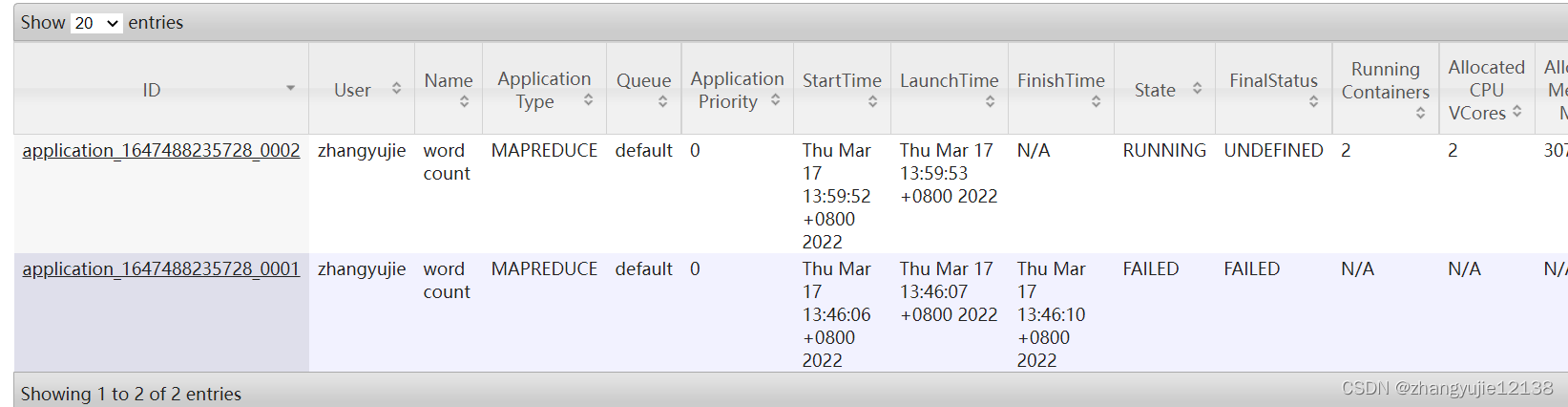
查看结果
出现output文件夹

通过 cat 命令查看结果
hdfs dfs -cat /wordcount/output/*
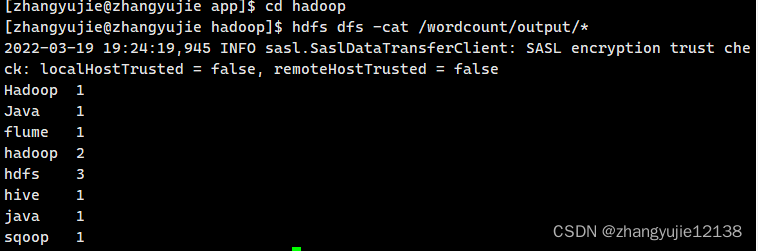
5. 运行 完成后查看yran页面内容
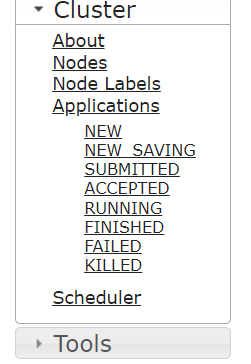
含有有关配置文件信息
6. 查看hdfs命令
hdfs dfs -help
常用hdfs命令
hdfs dfs=hadoop fs
-ls
-put
-mkdir
-rm -r
-cat
-help














 4371
4371











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









