






1 概述
1.1 Elasticsearch
ES日志存储具有以下优点:
- 高效性:ES日志存储使用分布式架构,可以高效地处理大量日志数据。它支持实时搜索和分析,并具有强大的聚合和过滤功能,可以快速地找到需要的信息。
- 可扩展性:ES日志存储具有高度的可扩展性,可以根据需要添加或减少节点,以适应不同规模的数据存储需求。
- 可靠性:ES日志存储具有数据备份和恢复功能,可以保证数据的可靠性和完整性。
- 灵活性:ES日志存储支持多种数据源和格式,可以轻松地与不同的应用程序和系统集成。
- 可视化能力:ES日志存储可以与Kibana等可视化工具集成,提供强大的数据可视化能力,可以帮助用户更好地理解和分析日志数据。
1.2 Logstash
Logstash是一个开源的数据收集引擎,具有实时管道能力。它能够动态地将来自不同数据源的数据统一起来,并将数据标准化到你所选择的目的地进行存储。Logstash可以接收和转发日志或任何事件数据,这使其成为一个强大的数据管道,可以将不同的数据源进行整合并将它们发送到不同的目标。
Logstash的架构主要包含三个组件:Collect(数据输入)、Enrich(数据加工)和Transport(数据输出)。输入插件负责从数据源接收数据,数据加工插件负责处理和转换数据,输出插件负责将数据发送到目标位置。通过这三个组件的组合使用,Logstash可以实现复杂的数据处理和传输任务。
Logstash支持各种类型的输入和输出插件,可以轻松地从不同的数据源中捕获事件,例如文件、网络、数据库等。同时,Logstash还提供了丰富的过滤插件,如Grok、Date、Json等,用于解析、转换和丰富数据。通过这些插件的组合使用,Logstash可以轻松地处理各种类型的数据,并将其转换成所需的格式。
Logstash还具有可扩展性强的特点。它可以与其他开源技术配合使用,如Elasticsearch和Kibana,形成一个完整的日志分析系统。通过将Logstash与Elasticsearch结合使用,可以轻松地搜索、分析和可视化日志数据。此外,Logstash还可以与其他消息队列系统集成,如Kafka、RabbitMQ等,用于实现更高效的数据传输和处理。
1.3 Filebeat
Filebeat是一个开源的轻量级日志收集器,它能够收集并解析各种日志数据。Filebeat在系统日志、Web服务器日志、应用程序日志等方面有着广泛的应用。Filebeat具有高可用性、可扩展性、高效性等特点,能够满足大规模的日志收集需求。将filebeta作为日志收集工具的原因是logshtash是一个重量级日志收集工具,他对日志的处理非常消耗内存和cpu,使用filebeta来分担一些压力
1.4 Kibana
Kibana是一个开源的数据可视化平台,可以用于展示和分析日志数据。通过Kibana,用户可以轻松地创建自定义的仪表盘和报告,以展示日志数据的不同方面。
Kibana的工作原理是接收来自Elasticsearch的数据,并将其转换成图形和图表等形式,以便用户更好地理解和分析。Kibana支持多种类型的图表和可视化形式,包括柱状图、饼图、折线图、地理地图等,可以满足用户不同的需求。
使用Kibana展示日志数据需要先在Elasticsearch中存储日志数据,然后通过Kibana界面访问和分析这些数据。在Kibana中,用户可以通过简单的拖放操作来创建自定义的仪表盘和报告,并可以添加过滤器和其他查询条件来进一步限制和筛选数据。
1.5 ELFK和ELK的区别
ELK和ELFK在架构上存在一些区别。总体来说,ELK是一个基于Elasticsearch、Logstash和Kibana的日志分析系统,而ELFK在ELK的基础上增加了filebeat,可以更好地收集资源日志。
- 数据收集方式:ELK和ELFK都支持从各种数据源收集日志,但ELFK加入了filebeat,可以更好地收集到资源日志。Filebeat是一个轻量级的数据收集器,可以用于收集各种类型的数据,如系统日志、应用程序日志、网络流量日志等。它通过读取文件或监听网络端口来收集数据,并支持将数据发送到kafka,Elasticsearch或Logstash进行处理。
- 数据处理方式:ELK和ELFK都支持对收集到的日志进行过滤、分析、丰富、统一格式等操作。ELK中的Logstash担当这个角色,而ELFK中的Logstash和filebeat共同完成这个任务,极大减轻了Logstash的压力。Filebeat将收集到的资源日志发送给kafka,Logstash根据自身处理能力从kafka拉取日志进行处理,然后将这些日志进行过滤、分析、丰富等操作后,存储到用户指定的位置。
- 数据存储方式:ELK和ELFK都支持将处理后的日志存储到Elasticsearch中进行搜索和分析。ELK中的Elasticsearch用于存储和分析日志数据,而ELFK中的Elasticsearch同样也担当这个角色。
- 数据展示方式:ELK和ELFK都支持通过Kibana对存储在Elasticsearch中的日志进行搜索和分析,并以统计图表的方式展示结果。ELK和ELFK在这方面的功能是一致的。
2 网络拓扑

3 Elasticsearch集群和Kibana搭建
4 filebeat部署
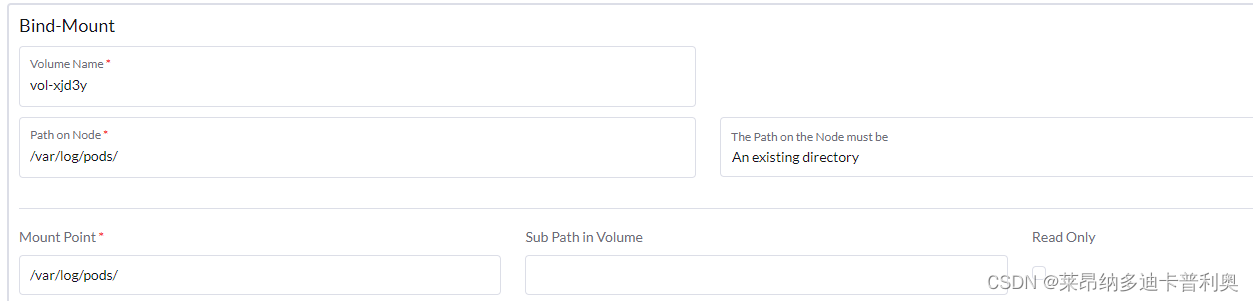
filebeat采集k8s中容器的日志,容器在k8s中的日志会落在宿主机的/var/log/pods/目录下,并在/var/log/containers/目录中创建日志的软连接,因此需要将/var/log/pods/和/var/log/containers/映射到filebeat容器中,filebeat才能采集到容器的日志,且只能采集到filebeat宿主机所在节点的日志,因此需要在k8s中使用DaemonSet方式部署filebeat,使filebeat部署到集群中所有节点。
4.1 docker images
docker.elastic.co/beats/filebeat:7.15.2
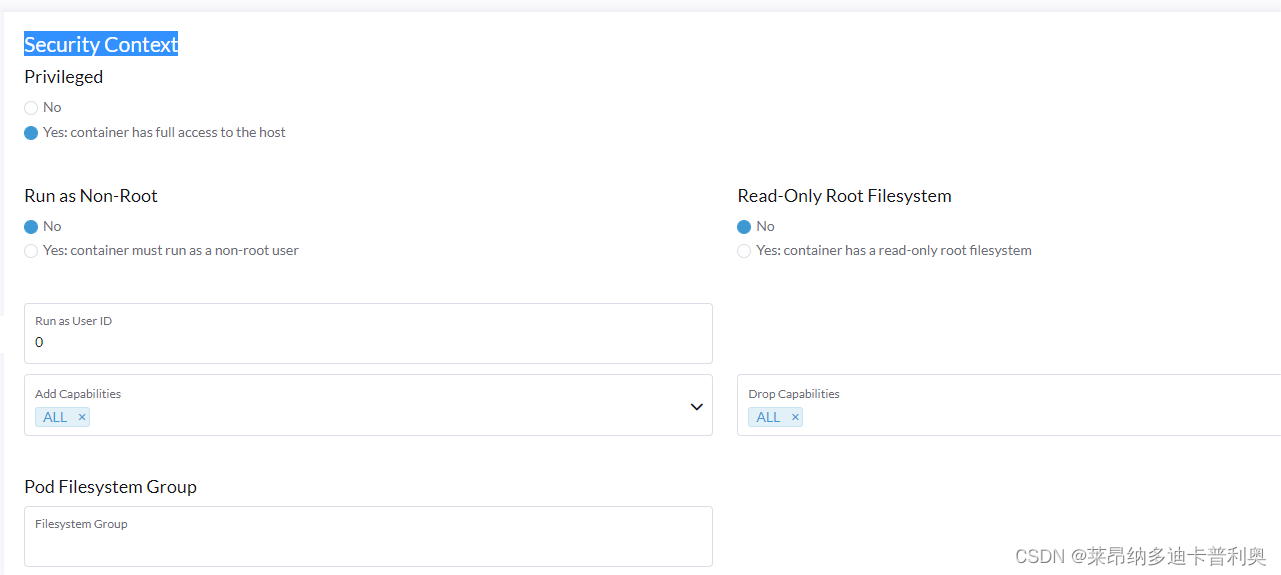
4.2 Security Context
为容器授权,赋予root权限
4.3 Storage
4.3.1 ConfigMap
将filebeat.yml配置文件挂载出来
#####filebeat.yml内容如下
filebeat.config:
modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
processors:
- add_kubernetes_metadata: ~
- drop_fields:
fields: ["host", "ecs", "agent", "input", "stream", "log"]
ignore_missing: false
filebeat.inputs:
##soa input
- type: container
tags: ["日志标签"]
enabled: true
paths:
- "/var/log/containers/*正则匹配内容*.log"
##多行匹配,正则匹配,匹配以 “[英文字母]”开头的行之前的内容都属于上一行
multiline.type: pattern
#multiline.pattern: '^\[[a-zA-Z]\]'
multiline.pattern: '^\[匹配内容\]|^\[\]'
multiline.negate: true
multiline.match: after
##输出到logstash
output.logstash:
enabled: true
hosts: ["10.0.0.1:5044", "10.0.0.2:5044", "10.0.0.3:5044"]
loadbalance: true
index: filebeat
##输出到控制台
#output.console:
#pretty: true
#enable: true4.3.2 将k8s每个节点的/var/log/pods/和/var/log/containers/目录映射到filebeat容器中

4.4 启动filebeat
5 logstash部署
5.1 下载logstash
wget https://artifacts.elastic.co/downloads/logstash/logstash-7.15.2-linux-x86_64.tar.gz --no-check-certificate5.2 开启防火墙端口
sudo ufw allow 5044
sudo ufw status5.3 配置logstash.yml
# ------------ Node identity ------------
#
# Use a descriptive name for the node:
#
node.name: logstash1
#
# If omitted the node name will default to the machine's host name
#
# ------------ Data path ------------------
#
# Which directory should be used by logstash and its plugins
# for any persistent needs. Defaults to LOGSTASH_HOME/data
#
path.data: /home/service/data/logstash/data
#
pipeline.batch.size: 1250
http.host: 10.0.0.1
# ------------ Debugging Settings --------------
#
# Options for log.level:
# * fatal
# * error
# * warn
# * info (default)
# * debug
# * trace
#
# log.level: info
path.logs: /home/service/data/logstash/log
5.4 创建filebeat.conf
input {
beats {
port => "5044"
}
}
filter {
mutate{
add_field => {
"logMessage" => "%{[message]}"
}
}
mutate{
split => ["message"," - "]
add_field => {
"subSystemId" => "%{[message][0]}"
}
add_field => {
"appName" => "%{[message][1]}"
}
add_field => {
"errorCode" => "%{[message][2]}"
}
add_field => {
"time" => "%{[message][3]}"
}
add_field => {
"traceId" => "%{[message][4]}"
}
add_field => {
"thread" => "%{[message][5]}"
}
add_field => {
"level" => "%{[message][6]}"
}
add_field => {
"logName" => "%{[message][7]}"
}
}
mutate {
gsub => [
"subSystemId", "[\[\]]", ""
]
gsub => [
"appName", "[\[\]]", ""
]
gsub => [
"errorCode", "[\[\]]", ""
]
gsub => [
"traceId", "[\[\]]", ""
]
gsub => [
"thread", "[\[\]]", ""
]
}
mutate{
remove_field => ["message"]
}
if "beats_input_codec_plain_applied" in [tags] {
mutate {
remove_tag => ["beats_input_codec_plain_applied"]
}
}
}
output {
elasticsearch {
hosts => ["10.0.0.1:9200", "10.0.0.2:9200", "10.0.0.3:9200", "10.0.0.4:9200", "10.0.0.5:9200", "10.0.0.6:9200"]
index => "%{[tags]}-%{[appName]}-%{+YYYY.MM.dd}"
user => ""
password => ""
}
stdout {
codec => json
}
}
5.5 启动
##关闭日志启动
nohup ./bin/logstash --log.level error -f config/filebeat.conf --config.reload.automatic >/dev/null 2>&1 &
##开启日志启动
nohup ./bin/logstash --log.level error -f config/filebeat.conf --config.reload.automatic >/data/es/data/logstash/log/logstash.log &6 kibana日志中心设置
6.1 创建工作空间
6.2 创建索引模板
设置索引模式
6.3 创建索引模板生命周期
策略设置:热阶段过后进入删除阶段,不设置温阶段和冷阶段,预生产和测试环境建议日志保存15天,生产环境建议保留1年。
















 885
885











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









