







Scrapy教程——自动多网页抓取
首先创建一个project
scrapy startproject teamworkitems.py的编写
# -*- coding: utf-8 -*-
import scrapy
class teamworkItem(scrapy.Item):
article_name = scrapy.Field()
article_url = scrapy.Field()
在items.py文件中定义你要抓取的字段:article_name(文章名称)和article_url(文章网址)
pipelines.py的编写
# -*- coding: utf-8 -*-
import json
import codecs
class teamworkPipeline(object):
def __init__(self):
self.file = codecs.open('teamwork_data.json', mode = 'wb', encoding = 'utf-8')
def process_item(self, item, spider):
line = json.dumps(dict(item)) + '\n'
self.file.write(line.decode("unicode_escape"))
return item其中,构造函数中以可写方式创建并打开存储文件。在process_item中实现对item处理,包含将得到的item写入到json形式的输出文件中。
settings.py的编写
BOT_NAME = 'teamwork'
SPIDER_MODULES = ['teamwork.spiders']
NEWSPIDER_MODULE = 'teamwork.spiders'
COOKIES_ENABLED = True
DOWNLOAD_DELAY=1
ITEM_PIPELINES = {
'teamwork.pipelines.teamworkPipeline': 300
}对于setting文件,他作为配置文件,主要是至执行对spider的配置。一些容易被改变的配置参数可以放在spider类的编写中,而几乎在爬虫运行过程中不改变的参数在settings.py中进行配置。
这里将COOKIES_ENABLED参数置为True,使根据cookies判断访问的站点不能发现爬虫轨迹,防止被ban。
爬虫teamwork_spider.py的编写
# -*- coding: utf-8 -*-
from scrapy.spider import Spider
from scrapy.selector import Selector
from teamwork.items import teamworkItem
from scrapy.http import Request
class teamworkSpider(Spider):
name = "teamwork"
#减慢爬取速度 为1s
download_delay = 1
allowed_domains = ["datartisan.com"]
#第一篇文章地址
start_urls = ['http://datartisan.com/article/detail/1.html']
def parse(self, response):
sel = Selector(response)
#获得文章url和标题
item = teamworkItem()
article_url = str(response.url)
article_name = sel.xpath('//div/div/h1/text()').extract()
name_list = [n.strip() for n in article_name]
item['article_name'] = ''.join(name_list)
item['article_url'] = article_url
print item['article_name']
yield item
#获得下一篇文章的url,当遇到最后一篇文章的时候停止爬取
urls = sel.xpath('//li[@class="next"]/a/@href').extract()
for url in urls:
if url != '#':
print url
yield Request(url, callback=self.parse)strip()方法为去除字符串中的空格,join将字符串连接起来。
download_delay参数设置为1,将下载器下载下一个页面前的等待时间设置为1s,也是防止被ban的策略之一。主要是减轻服务器端负载。
从response中抽取文章链接与文章题目,编码为utf-8。注意yield的使用。
通过yield Request(url, callback=self.parse)抽取下一篇的url,也就是将新获取的request返回给引擎,实现继续循环。也就实现了“自动下一网页的爬取”。
执行爬虫
在shell中输入scrapy crawl teamwork执行爬虫,爬取的数据存在teamwork_data.json文件中:
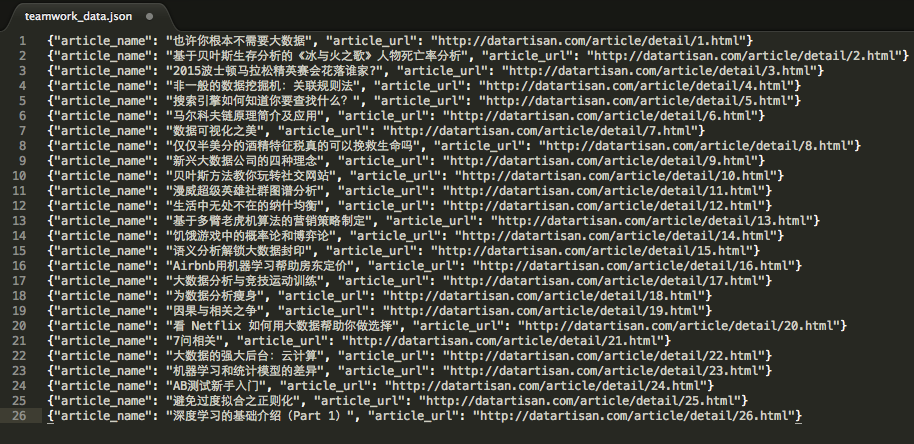
The end!
本文参考Scrapy精华教程(五)——自动多网页爬取(抓取某人博客所有文章)如有侵权,联系删除。















 1936
1936

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









