






微信开了自动下载文件总是会下载大量重复的文件,所以写了个脚本希望能协助大家整理微信文件,当前还在尝试实现命名不明确文件的重命名,大家有什么意见可以提一下
PS:这里需要插入你的指定文件存放路径(工程还小还没写前端)
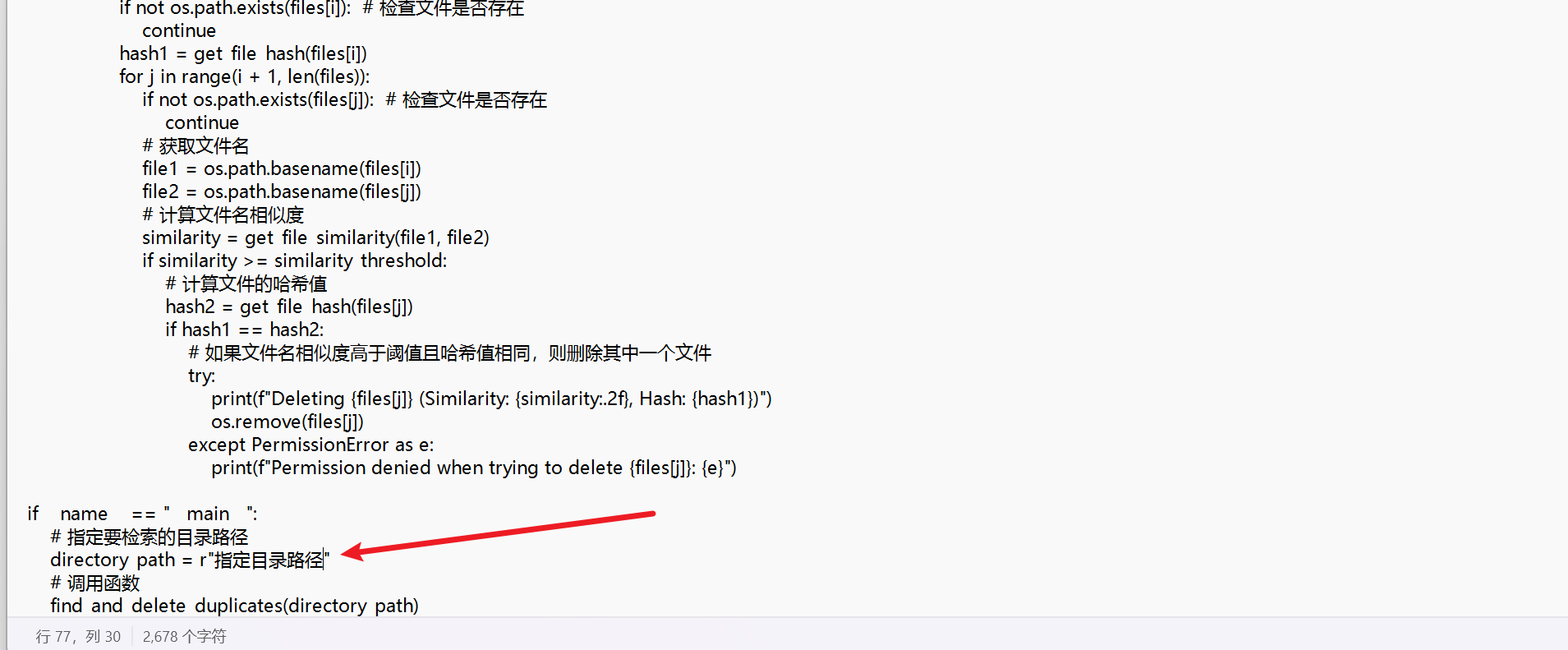
import os
import difflib
import hashlib
from collections import defaultdict
# 定义函数:计算文件的哈希值
def get_file_hash(file_path):
"""
计算文件的 MD5 哈希值。
:param file_path: 文件路径
:return: 文件的 MD5 哈希值
"""
hash_md5 = hashlib.md5()
with open(file_path, "rb") as f:
for chunk in iter(lambda: f.read(4096), b""):
hash_md5.update(chunk)
return hash_md5.hexdigest()
# 定义函数:计算两个文件名的相似度
def get_file_similarity(file1, file2):
"""
使用 difflib.SequenceMatcher 计算两个文件名的相似度。
:param file1: 第一个文件名
:param file2: 第二个文件名
:return: 相似度(0 到 1 之间的浮点数)
"""
return difflib.SequenceMatcher(None, file1, file2).ratio()
# 定义函数:查找并删除相似度高且内容相同的文件
def find_and_delete_duplicates(directory, similarity_threshold=0.8):
"""
检索指定目录下的文件,删除相似度高且内容相同的文件。
:param directory: 指定的目录路径
:param similarity_threshold: 文件名相似度阈值(0-1之间)
"""
# 用于存储文件大小和对应文件路径的字典
files_info = defaultdict(list)
# 遍历指定目录及其子目录中的所有文件
for root, dirs, files in os.walk(directory):
for file in files:
# 获取文件的完整路径
file_path = os.path.join(root, file)
# 获取文件的大小
file_size = os.path.getsize(file_path)
# 将文件路径按大小分类存储
files_info[file_size].append(file_path)
# 检查相同大小的文件并比较文件名相似度和哈希值
for size, files in files_info.items():
if len(files) > 1: # 如果有多个文件大小相同
for i in range(len(files)):
if not os.path.exists(files[i]): # 检查文件是否存在
continue
hash1 = get_file_hash(files[i])
for j in range(i + 1, len(files)):
if not os.path.exists(files[j]): # 检查文件是否存在
continue
# 获取文件名
file1 = os.path.basename(files[i])
file2 = os.path.basename(files[j])
# 计算文件名相似度
similarity = get_file_similarity(file1, file2)
if similarity >= similarity_threshold:
# 计算文件的哈希值
hash2 = get_file_hash(files[j])
if hash1 == hash2:
# 如果文件名相似度高于阈值且哈希值相同,则删除其中一个文件
try:
print(f"Deleting {files[j]} (Similarity: {similarity:.2f}, Hash: {hash1})")
os.remove(files[j])
except PermissionError as e:
print(f"Permission denied when trying to delete {files[j]}: {e}")
if __name__ == "__main__":
# 指定要检索的目录路径
directory_path = r"指定目录路径"
# 调用函数
find_and_delete_duplicates(directory_path)

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









