







java 核心技术卷I学习记录(一)
java 和c++的主要不同
- 多重继承,在java中用接口来取而代之。
- java 采用的指针模型可以消除重写内存各损坏数据的可能性
- 在java中int 永远都是32bit ,而在c++中int可能是16bit,32bit,也可能是编译器提供商指定的其他大小。c++中对此唯一的限制是int类型的大小不能低于short Int,并且不能高于long int .
- java 中没有没有任何无符号(unsigned)形式的int、long、short或byte类型
java 用于表示溢出和出错的三个特殊的浮点数值
- 正无穷大
- 负无穷大
- NaN(不是个数字)
例如:一个正整数除以0的结果是正无穷大。计算0/0或者负数的平方根结果为NaN
常量Double.POSITIVE_INFINITY、Double.NEGATIVE_INFINITY和Double.NaN分别表示三个特殊的值。不能这样检测一个特定值是否等于Double.NaN:
if(x == Double.NaN)//Is never true所有的“非数值”的值都认为是不相同的。然而可以使用Double.isNaN的方法:
if(Double.isNaN(x))//check whether x is not a numberjava 中的浮点数不适用于无法接受舍入误差的金融计算中。原因在于浮点数值用的是二进制数来表示 的,二进制数无法表示分数。如果涉及到这些计算应使用BigDecimal类
char 类型
Unicode 转义序列会在解析代码之前得到处理,将转义序列翻译成相应的字符
Unicode 和 UTF-8
unicode是ISO 搞得包括了地球上所有文字、所有字母和符号 的编码。 ISO 直接规定必须用两个字节,也就是16位来统一表示所有的字符,对于ASCII里的那些“半角”字符,unicode使其原编码不变,只是将其长度由原来的8位扩展为16位,而其他文化和语言的字符则全部重新统一编码。由于”半角”英文符号只需要用到低8位,所以其高8位永远是0,因此这种大气的方案在保存英文文本时会多浪费一倍的空间。
但是:strlen 函数的结果变化了,一个汉字不再是相当于两个字符了,而是一个字符。是的,从unicode开始,无论是一个半角的英文字母,还是一个全角的汉字,它们都是统一的”一个字符“!同时,也都是统一的”两个字节“,请注意”字符”和”字节”两个术语的不同,“字节”是一个8位的物理存贮单元,而“字符”则是一个文化相关的符号。在unicode中,一个字符就是两个字节。
unicode在很长一段时间内无法推广,直到互联网的出现,为解决unicode如何在网络上传输的问题,于是面向传输的众多 UTF(UCS Transfer Format)标准出现了,顾名思义,UTF-8就是每次8个位传输数据,而UTF-16就是每次16个位。UTF-8就是在互联网上使用最广的一种unicode的实现方式,这是为传输而设计的编码,并使编码无国界,这样就可以显示全世界上所有文化的字符了。UTF-8最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度,当字符在ASCII码的范围时,就用一个字节表示,保留了ASCII字符一个字节的编码做为它的一部分,注意的是unicode一个中文字符占2个字节,而UTF-8一个中文字符占3个字节)。从unicode到utf-8并不是直接的对应,而是要过一些算法和规则来转换。
变量
变量命名必须要以字母开头并由字母或数字构成的序列。虽然$ 是java 的合法字符,但不要在自己的代码中使用这个字符。它只用在java编译器或者其他工具生成的名字中。
java中变量的声明尽可能的靠近变量第一次使用的地方,这是一种良好的编程习惯。
在java中利用关键字final指示常量。该变量只能被赋值一次,一但被赋值之后,就不能现更改。且习惯上常量名用全部大写来表示。类常量常定义在mian方法外部,一旦该常量声明为public,那么其他类的方法也可以使用这个常量。c++中是使用const来声明常量的,但在java虽然是保留的关键字,但并没使用。
运算符
在默认情况下,jvm允许中间计算结果采用扩展的精度(intel处理器80位浮点寄存器)。但是,对于使用strictfp关键字标记的方法必须使用严格的浮点计算来生成可再生的结果。在mian中的所有指令都将使用严格的i浮点计算。如果将一个类标记为strictfp,这个类中的所有方法都要使用严格的浮点计算。
数学函数Math
在n%2中,正常情况下的结果大家都知道。但如果n为负呢,这个表达式则为-1.为什么呢??是因为最早制定该运算的人并不知道余数要大于等于0。而floorMod方法解决了该问题。
strictMath类中的方法在所有平台上都能得到相现的结果,如果得到一个完全可预测的结果比运行速度更重要的话,可选用StrictMath类中的方法
数个类型之前的转换
数值类型之间合法的转换如下图所示(实心箭头表示转换过程无精度的损失;虚箭头表示 在转换过程中有精确度的损失):
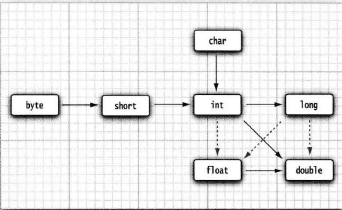
当两个数值进行二元操作时(如n+f,n为整数,f为浮点数),操作数的类型转换为:
- 如果两个操作数中有一个是double类型,另一个操作数就会转换为double类型
- 否则如果其中一个是float类型,另一个操作数就会转换为float类型。
- 否则,如果其中一个操作数是long类型,另一个操作数将会转换为long类型。
- 否则,两个操作数都将被转换为类型
强制类型转换
如果试图将一个数值从一种类型强制转换为另一种类型,而又超出了目标类型的表示 范围,结果就会截断成一个完全不同的值。例如,(byte)300 的实际值是44
自增与自减
由于自增和自减运算符会改变变量的值,所以它们的操作数不能是数值本身(例如,4++是不对的)。
关系和boolean运算符
java中==和equals的区别
java中的数据类型可分为两类:
1. 基本数据类型,也称原始数据类型。byte,short,char,int,long,float,double,boolean。
基本数据类型的比较,应使用==来比较他们的值
2. 数据类型(类):
当这些复合数据类型使用== 来进行比较时,==是比较的他们存放在内存的地址(所以除非是同一个new出来的对象,他们的比较后的结果为true,否则比较后结果为false)。
JAVA当中所有的类都是继承于Object这个基类的,在Object中的基类中定义了一个equals的方法(该equals方法也在定义时也是使用== 来比较的),这个方法的初始行为是比较对象的内存地 址,但在一些类库当中这个方法被重写了,如String,Integer,Date在这些类当中equals有其自身的实现,而不再是比较类在堆内存中的存放地址了
所以说,对于复合数据类型之间进行equals比较,在没有覆写equals方法的情况下,他们之间的比较还是内存中的存放位置的地址值,跟双等号(==)的结果相同;如果被复写,按照复写的要求来。
&&和|| 如果第一个操作数能够确定表达式的值,第二个操作数就不必计算了!
预算符优先级
a&&b || c 等价于 (a&&b)|| c
a+= b += C 等价于 a+= (b+=c)= 、+=、-=、*=、/=、 &=、|=、^=、<<=、>>=、>>>= //结合性是从右向左今日学习到此为止2018/9/16















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









