







太长不看版
直接找到引入该依赖的xml文件(本人是spark-core的xml文件),将其中的snappy-java的version改为1.1.8.4。重新加载即可。
<dependency>
<groupId>org.xerial.snappy</groupId>
<artifactId>snappy-java</artifactId>
<version>1.1.8.4</version>
<scope>compile</scope>
</dependency>
详细探索过程
日前新M1 pro芯片的MacBook Pro到手了,迫不及待的试了试。因为该芯片使用的ARM指令集,之前Intel芯片的电脑使用的是X86指令集,故此难免会有一些问题。不过经过一年的适配基本上没有什么大问题了,所以在经过几天的尝试后,果断将该机器用于工作生产中。
本人是大数据开发工程师,必然要安装Java,刚开始使用的是传统的Intel版本jdk(因为主要使用的是jdk1.8,而Oracle只对jdk17做了arm版的适配),开发中感觉会有一些程序执行的没有那么速度(和18款MacBook Pro执行速度差不多),因为毕竟要经过Rosetta2转译。故此在使用几天后,将Intel版本的jdk替换为ARM版本的jdk。详情可以参考该文档https://www.winsonlo.com/it/howto/zulu-jdk8-on-m1/。但是文档中有一个坑,文档中给的直接下载链接,并不是arm版的,我在安装后发现执行的时候一直使用的是intel版java,后来才发现是下载链接错误,需要自己到官网手动下载真正的arm版jdk(该网址打开速度比较慢,如果不能自己下载的话,可以给我私信)。
安装好arm版jdk后,编译速度果然有很大提升,但是在本地执行spark程序时,遇到了这样一个问题,详细日志如下:
Caused by: org.xerial.snappy.SnappyError: [FAILED_TO_LOAD_NATIVE_LIBRARY] no native library is found for os.name=Mac and os.arch=aarch64
at org.xerial.snappy.SnappyLoader.findNativeLibrary(SnappyLoader.java:331)
at org.xerial.snappy.SnappyLoader.loadNativeLibrary(SnappyLoader.java:171)
at org.xerial.snappy.SnappyLoader.load(SnappyLoader.java:152)
at org.xerial.snappy.Snappy.<clinit>(Snappy.java:47)
at org.apache.parquet.hadoop.codec.SnappyDecompressor.decompress(SnappyDecompressor.java:62)
at org.apache.parquet.hadoop.codec.NonBlockedDecompressorStream.read(NonBlockedDecompressorStream.java:51)
at java.io.DataInputStream.readFully(DataInputStream.java:195)
at java.io.DataInputStream.readFully(DataInputStream.java:169)
at org.apache.parquet.bytes.BytesInput$StreamBytesInput.toByteArray(BytesInput.java:205)
at org.apache.parquet.column.values.dictionary.PlainValuesDictionary$PlainBinaryDictionary.<init>(PlainValuesDictionary.java:89)
at org.apache.parquet.column.values.dictionary.PlainValuesDictionary$PlainBinaryDictionary.<init>(PlainValuesDictionary.java:72)
at org.apache.parquet.column.Encoding$1.initDictionary(Encoding.java:90)
at org.apache.parquet.column.Encoding$4.initDictionary(Encoding.java:149)
at org.apache.spark.sql.execution.datasources.parquet.VectorizedColumnReader.<init>(VectorizedColumnReader.java:103)
at org.apache.spark.sql.execution.datasources.parquet.VectorizedParquetRecordReader.checkEndOfRowGroup(VectorizedParquetRecordReader.java:280)
at org.apache.spark.sql.execution.datasources.parquet.VectorizedParquetRecordReader.nextBatch(VectorizedParquetRecordReader.java:225)
at org.apache.spark.sql.execution.datasources.parquet.VectorizedParquetRecordReader.nextKeyValue(VectorizedParquetRecordReader.java:137)
at org.apache.spark.sql.execution.datasources.RecordReaderIterator.hasNext(RecordReaderIterator.scala:39)
at org.apache.spark.sql.execution.datasources.FileScanRDD$$anon$1.hasNext(FileScanRDD.scala:105)
at org.apache.spark.sql.execution.datasources.FileScanRDD$$anon$1.nextIterator(FileScanRDD.scala:177)
at org.apache.spark.sql.execution.datasources.FileScanRDD$$anon$1.hasNext(FileScanRDD.scala:105)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIterator.scan_nextBatch$(Unknown Source)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIterator.processNext(Unknown Source)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anonfun$8$$anon$1.hasNext(WholeStageCodegenExec.scala:395)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIterator.agg_doAggregateWithKeys$(Unknown Source)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIterator.processNext(Unknown Source)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anonfun$8$$anon$1.hasNext(WholeStageCodegenExec.scala:395)
at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:408)
at org.apache.spark.shuffle.sort.BypassMergeSortShuffleWriter.write(BypassMergeSortShuffleWriter.java:125)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:96)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:53)
at org.apache.spark.scheduler.Task.run(Task.scala:108)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:335)
... 3 more
org.xerial.snappy为一个压缩/解压库,我使用的是spark版本是2.2.0,该版本依赖的snappy是1.1.2.6。该版本内容如下:
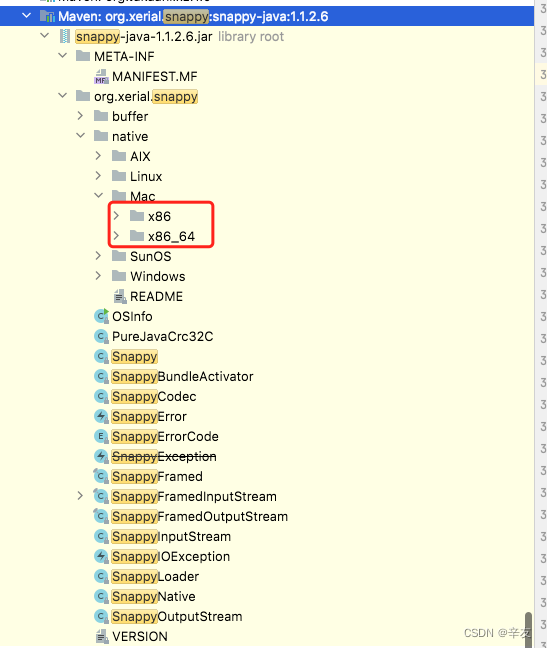
可以看到,该版本的snappy只支持Mac系统的x86和x86_64,并不支持arm64版本。因为该库是开源库,故此我试着在github中搜索了一下该项目,果然找到了该项目的源码源码地址我试着看了一下master分支的代码,发现已经做了对arm版的mac系统的支持了。这样一来问题就简单了,只要找到引入snappy-java的依赖,直接将其版本升级到最新版即可。
通过IDEA的依赖图,搜索到是spark-core导入的该库,我的spark-core版本是2.2.0,引入的snappy-java是1.1.2.6。如图所示:
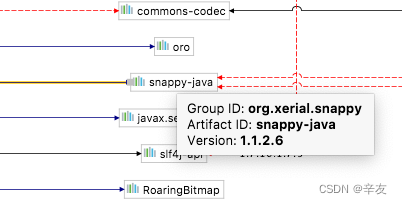
在mvnrepository中查询最新版的snappy-java的版本是1.1.8.4,故此直接在spark-core的xml文件中替换掉原来的版本,如图
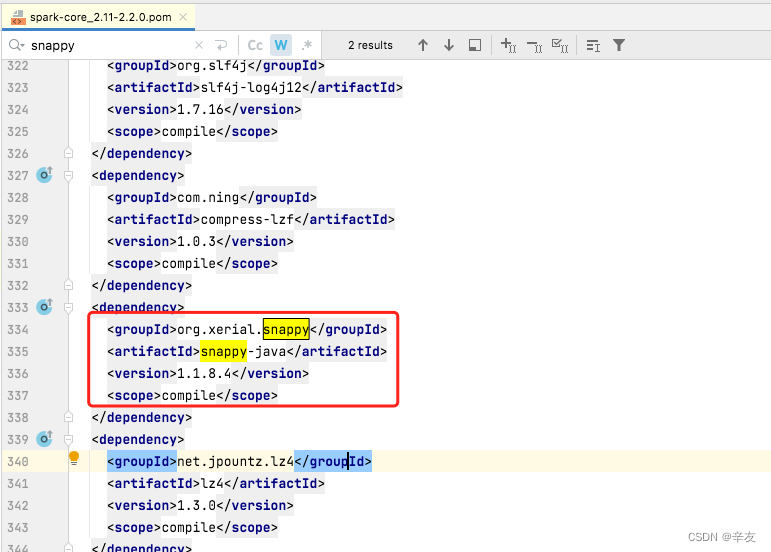
重新加载依赖再次执行,代码执行顺利,问题搞定。














 381
381











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









