







一、背景
1.问题
通过顶点坐标公式,求解出抛物线最低点的w坐标,得到了让误差代价最小的w。同样的,也通过算数说明了这种一步到位求解的方式固然是好,但是在输入特征过多、样本数量过大的时候,却非常消耗计算资源。
2.思考
抛物线最低点的寻找过程,其实不必一步到位,大可以采用一点点挪动的方式。
通过在代价函数e与神经元的权重w图像上挪动w过程中发现,在最低点左侧,需要不断将w调大,在最低点右边,需要不断把w调小。
具体实施:斜率
开口向上抛物线,左边斜率为负数,右边斜率为正数,最低点斜率为0。
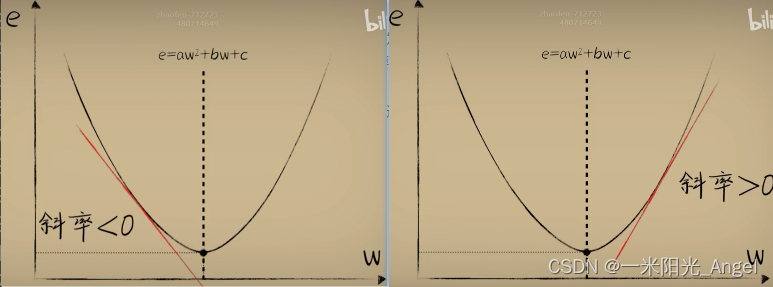
e=a
w
2
w^2
w2+b
w
w
w+c
3.解决
想办法得到代价函数e在当前w取值这个点上的斜率。通过斜率判断当前w的取值是在最低点左边还是右边,然后不断调整w直到到达最低点,这样,就得到一个误差代价最小的权重w
二、问题转化:求一元二次函数的斜率

1. 定义法
在遥远的过去,我们的祖先曾坚定不移地相信“天圆而地方”,但自从麦哲伦完成环球航行,我们开始了解到地球其实是一个球,表面其实是一个曲面,我们之所以觉得大地是平直的,只是因为我们太过渺小,在这个巨大的蓝色星球上,我们的祖先用脚能够丈量的范围,相比于整个地球,实在是微不足道。

同样的道理,当我们看这个曲线的时候,它显而易见是弯的,我们此刻更像是“上帝视角”看见了它的全部,而当我们盯着一个点不断变小,变小,当我们足够小的时候,同样显而易见的是,曲线是直的,这种“直”是宏观的“弯曲”在微观中的一种近似。

而一个直线的斜率就十分好求

作为一个极小的生物,降落在曲线一个点计算出来的斜率

既然作为直线的斜率,那就必须保证两点之间的距离足够小,以保证足够近似一个直线。
问题:这个距离得是多小,才算小?是相对于地球表面,两个脚印之间的距离吗?是分子或者原子之间的距离吗?都不是。其实,这种无限小我们很难找到直观得物理表达。它更是一个数学上的概念:极限。
只有在曲线上一个点附近,取一个距离无线接近的点的时候,用直线的方法计算的斜率,才能称之为这个点的真实斜率。
我们不必取纠结这个无限小到底是多小,它只是数学上的一个概念和手段,当然,这个概念,也是微积分大厦的重要基石。
通过极限的数学表示: 当 △w 足够小的时候,△w会自然湮灭,所以这个点的斜率为 2aw+b

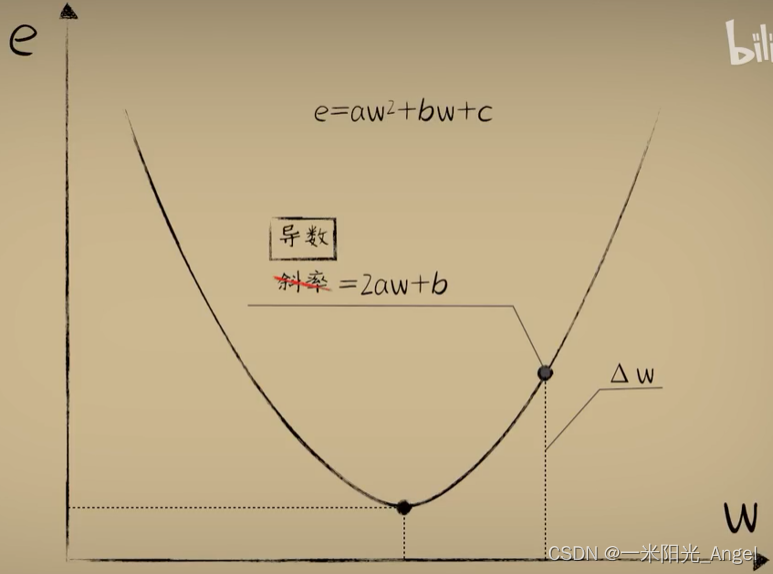
【数学上导数定义】在曲线中,某处的斜率我们一般会把它称为导数。用纵坐标的差值 / 横坐标的差值,并取极限。这种求导的方式,称为 定义法。用定义法,原则上可以求解任意一个函数任意一点的导数(可导的时候)
2. 求导公式和法则
定义法可以得到一个函数的导数,数学中常用的函数也就那么多,全部求出来做成一张表格形成固定的公式,用到的话直接查询。

问题:虽然常用的函数就那么多,但他们的组合又是无穷无尽。对于“无穷无尽”组合函数,我们不可能用有限的生命投入到无限的事情中,毕竟传统功夫,点到为止。但我们总是能琢磨出一些新的规律;实际上,不论怎样的函数组合都逃不脱3种基本的形式。

减法是加法的另一种形式,除法是乘法的另一种形式。

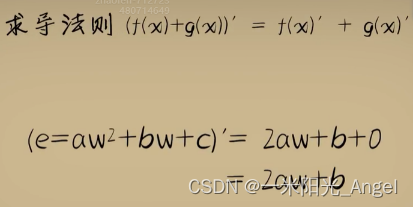
这与定义法得到的结果是一样。

3. 验证
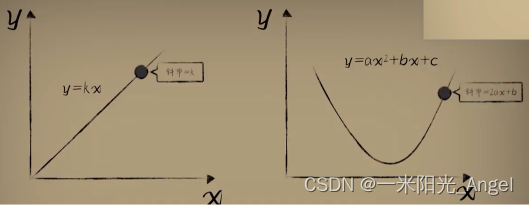
在直线中斜率(导数)是个常数,因为斜率(导数)一直没什么变化
而在抛物线中斜率(导数)和自变量有关
这样,求得了代价函数每一点的斜率
小蓝的神经元终于可以根据代价函数的斜率是否大于0来调整w的行为了
问题:每次调整多少合适?
-
尝试:每次调整0.01 ,会发现调整的过程有点慢,最低点处还反复震荡,无论当前w是多少,调整幅度固定了。
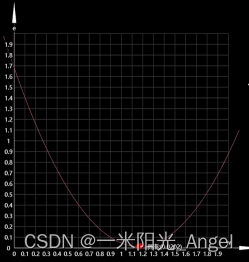
-
聪明:当w距离最低点比较远的时候,希望调整得快些,逐渐接近最低点的时候,希望它慢一点。这样,能加快下降的速度,又能在最低点的时候,稳如老狗。好比给你一张图片,让你把图片中的圆形切割出来,一开始,我们大刀阔斧的切,而越到后来越精雕细琢的切。这样要比每次呆板的切掉固定的大小,效率高精度高。

距离较远时,斜率的绝对值越大;距离越近时,斜率的绝对值越小,当接近最低点的时候,几乎为0,最低点的斜率就是0,是分界点。斜率在左右的符号又正好不同,在左边,斜率为负数,w在右边,斜率为正数
方法:通过斜率的值

当w在左边,斜率为 负数,新的w会增大
当w在右边,斜率为 正数,新的w会变小
同时,也做到了距离最低点比较远的时候,斜率大(绝对值)调整得多,大刀阔斧
距离最低点比较近的时候,斜率小(绝对值),调整得少,精雕细琢
问题:调整的过程,太过震荡
方法:通过学习率alpha

这种根据曲线不同处“斜率”不断调整权重w的方式,也就是所谓的梯度下降
问题:为什么称之为 “梯度下降”而不是“斜率下降”?
回答:“梯度”是一个比“斜率”更为广泛的概念
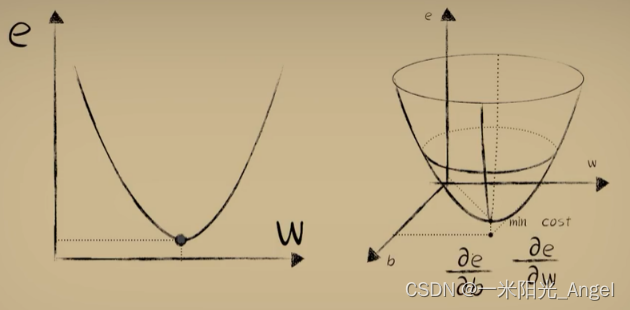
当代价函数为二维的时候,可以称“斜率”
当扩展到三维空间的时候,斜率不太合适了
而当我们多次梯度下降的过程后,w收敛到最低点附近,停止梯度下降的过程,将此时的w作为预测模型中w的值。此时,便能相当准确完成预测了。
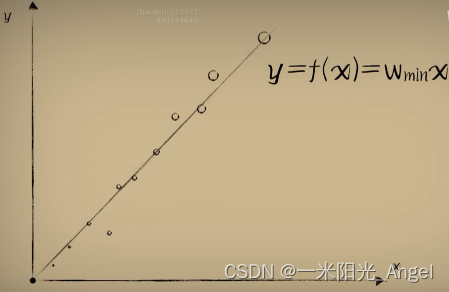
解释前面的问题:为什么Rosenblatt感知器的参数调整方式好用?
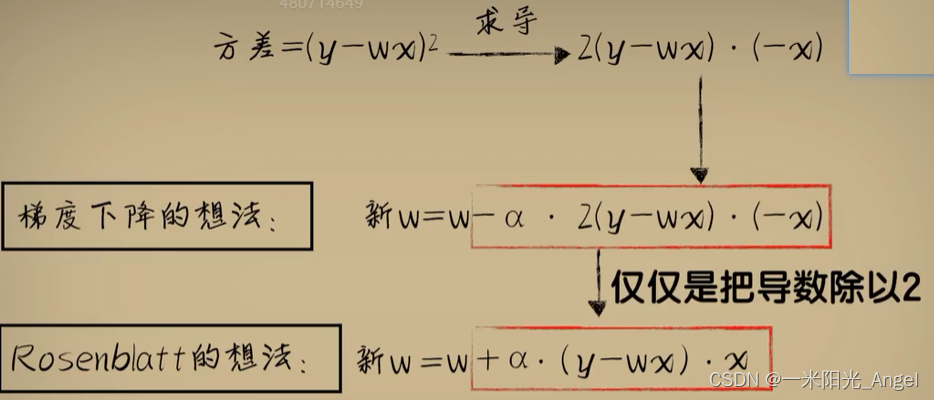
梯度下降 比 “一步求解”的正规方程 的优势何在?
首先,单个样本情况,它的代价函数是一个开口向上的抛物线
接着,多个样本情况,所有样本合在一起时,代价函数仍然是一个开口向上的抛物线

合成代价函数的最低点,是整个样本的全局最优点
下降的过程是一个明确且顺滑的轨迹,这也就是标准的梯度下降,也称为“批量梯度下降”
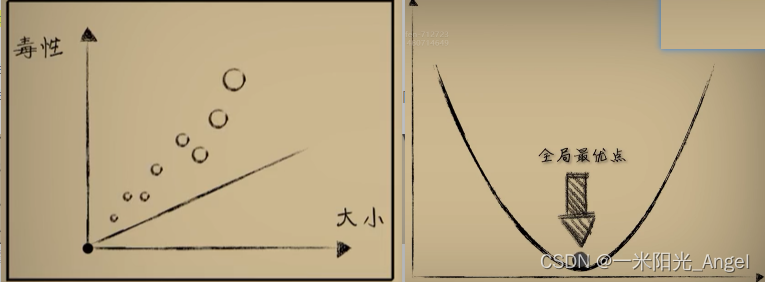
如果每次只使用一个样本,这个样本的最低点不一定就是全局最优
如果不断的依次在这些单样本代价函数上进行梯度下降
虽然会有震动和波动,但多次以后,它们的整体趋势仍然会向全局最优点挪动
最后,也可成功,而不像“正规方程”中那样,一次性代入全部的样本进行计算
如果有海量的数据,你的机器,必然GG

每次取一个样本进行梯度下降,因为其收敛的过程是一个随机震荡的轨迹,所以,也称之为“随机梯度下降”,实际上,最后在最低点附近,这个震荡的轨迹是一个经典的“布朗运动”
批量的好处是可以并行计算,可以更容易向最优点收敛;但其缺点明显,100万个数据要同时算出来,和“正规方程”没啥区别了
随机的好处是海量的数据照样可以慢慢来,每次都更新参数,参数的更新过程变得更快;缺点是无法并行,且不容易向全局最优点收敛
所以,综合二者优缺点,我们向来喜欢“折中”的。人们往往采用调和的方法 mini bath (mini 批量梯度下降)
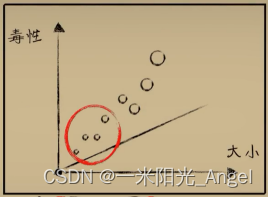
每次选择一小批进行梯度下降,“折中调和”真是经久不衰的智慧















 551
551











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









