






tensorflow的神经元不断自我适应。
用梯度下降算法自我调适。
可调整参数包括:Activation(激活函数),Learning Rate(学习率),Regularization(正则化)。
(1)
激活函数,谷歌提供了4种。RELU,ReLu(Rectified Linear Units 纠 正线性单位激活函数),tanh (双曲正切函数),sigmoid (在生物学中常见的S型的函数,也称为S型生长曲线),LINEAR(线性)
Sigmoid函数(0~1):
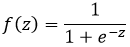
Tanh函数(-1~1):
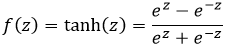
ReLu函数(0~+∞):
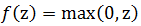
目前,ReLU函数在神经网络模型研究和实际应用中应用的更多,因为使用sigmoid或tanh作为激活函数做无监督学习时,会遇到梯度消失问题(gradient vanishing problem)导致无法收敛,而ReLU可以避免这个问题;另一方面,基于ReLU这种线性激活函数的神经网络的计算开销也是相对较低的。
(2)学习率决定了权值更新的速度,设置得太大会使结果越过最优值,太小会使下降速度过慢。仅靠人为干预调整参数需要不断修改学习率。有三个参数可以调整学习率的自适应性 Weight Decay 权值衰减 Momentum 动量 Learning Rate Decay 学习率衰减)
(3)
正则化方法:防止过拟合,提高泛化能力
在训练数据不够多时,或者overtraining时,常常会导致overfitting(过拟合)。随着训练过程的进行,模型复杂度增加,在training data上的error渐渐减小,但是在验证集上的error却反而渐渐增大。避免过拟合的方法有很多:early stopping、数据集扩增(Data augmentation)、正则化(Regularization)包括L1、L2(L2 regularization也叫weight decay),dropout。















 234
234

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









