







一、SAX解析的优缺点
1、优点:SAX解析允许在读取文档的时候,即对文档进行处理,而不必等到整个文档装载完才会对文档进行操作。所以应用于大型xml文档,访问效率低,顺序访问。
二、SAX解析的原理
SAX采用事件处理的方式解析XML文件,利用SAX解析XML文档,涉及两个部分:解析器和事件处理器。
1、 解析器可以使用JAXP的API创建,创建出SAX解析器后,就可以制定解析器去解析某个XML文档。解析器采用SAX方式解析某个XML文档时,他只要解析到XML文档的一个组成部分,都会去调用事件处理器的一个方法,解析器再调用事件处理器的方法时,会把当前解析到的xml文件内容作为方法的参数传递给事件处理器。
2、 事件处理器由程序员编写,程序员通过事件处理器中方法的参数,就可以很轻松的得到sax解析到的数据,从而可以决定如何对数据进行处理。
三、SAX解析的常用方法
阅读ContentHandler API文档,常用方法:startElement、endElement、characters
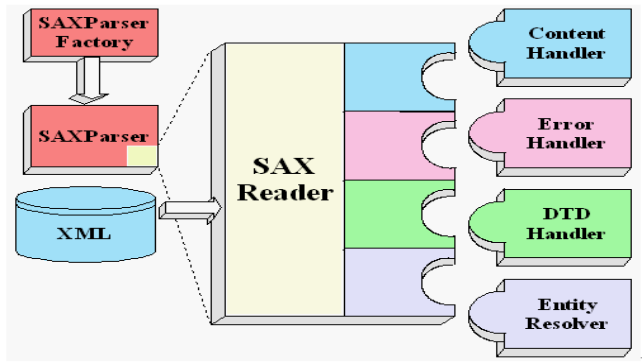
四、SAX方式解析XML文档的步骤
1、使用SAXParserFactory创建SAX解析工厂
SAXParserFactory spf=SAXParserFactory.newInstance();
2、通过SAX解析工厂得到解析器对象
SAXParser sp=spf.newSAXParser();
3、通过解析器对象得到一个XML的读取器
XMLReader xmlReader=sp.getXMLReader();
4、设置读取器的事件处理器
xmlReader.setContentHandler(new BookParserHandler());//BookParserHandler()自己编写的事件处理器
5、 解析xml文件
xmlReader.parse("book.xml");
public class SAXHandler extends DefaultHandler {
Stack tags = null;
@Override
public void startDocument() throws SAXException {
tags=new Stack();
}
@Override
public void endDocument() throws SAXException {
while(!tags.isEmpty()){
System.out.println(tags.peek());
tags.pop();
}
tags=null;
}
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
if("students".equals(qName)){
System.out.println(attributes.getValue("class")+"--人数-"+attributes.getValue("count"));
}
tags.push(qName);//压入栈
}
@Override
public void endElement(String uri, String localName, String qName)
throws SAXException {
tags.pop();//取出栈顶元素
}
@Override
public void characters(char[] ch, int start, int length)
throws SAXException {
String tag=(String) tags.peek();//查看栈顶元素,但不移除
if("name".equals(tag)){
System.out.println("name==="+new String(ch,start,length));
}
if("age".equals(tag)){
System.out.println("age==="+new String(ch,start,length));
}
}
}















 1178
1178











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









