







目录
1 什么是闭包
闭包的英文对应的是Closure,如果要单纯的讨论这个概念的话就要提到和图灵机起名的大名鼎鼎的lambda演算(lamdba calculus)。尽管lamdba的概念并不是本文的重点,但是闭包概念的目的便是支持lamdba的实现。如果你单独地在百度对进行搜索闭包的话,你会发现大部分都是js相关的内容,主要是js本身就只用闭包的这个概念。但是闭包并不仅限于js,而是一个通用的概念。借用wiki中有点抽象的定义来说的话,闭包就是:
在计算机科学中,闭包(英语:Closure),又称词法闭包(Lexical Closure)或函数闭包(function closures),是引用了自由变量的函数。
简单来说就是当一个方法引用了方法局部变量外的变量时,它就是一个闭包。而如果根据这个定义继续延展的话,就可以得到另外的一种描述方法:
闭包是由函数和与其相关的引用环境(方法外变量)组合而成的实体。
通俗点就是:一个函数返回了一个函数对象,而这个返回的函数对象引用了外部函数的私有变量/局部变量,这样就形成了一个闭包。
1.1 JS中的闭包
涉及到以下JS知识点:
-
函数的执行上下文环境(Execution context of function) -
变量对象(Variable object) -
活动对象(Active object) -
作用域(scope) -
作用域链(scope chain)
那么我们首先来看一段JS代码
//函数定义
function outerTest() {
var num = 0;
function innerTest() {
++num
console.log(num);
}
return innerTest;
}
//调用
var fn1 = outerTest();
fn1();
fn1();
fn1();运行结果
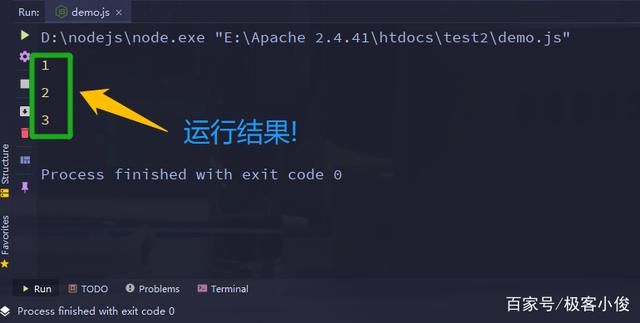
以上就是一个闭包的经典案例, 我们慢慢来分析!
其实你会发现以上这段JS代码有两个特点:
1、innerTest函数嵌套在outerTest函数的内部
2、outerTest函数的返回值就是innerTest函数
那么有人就会说函数嵌套函数就是闭包 其实这样子说是不严谨的!
原理分析
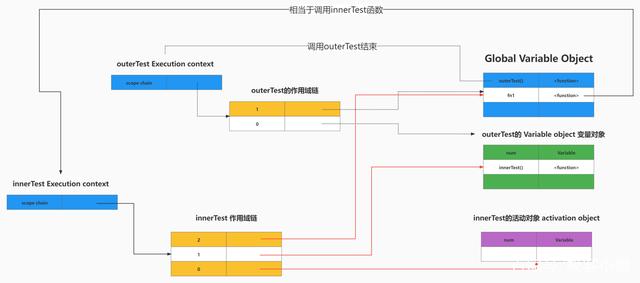
接着之前的那一段JS代码 我们来看一张图

代码分析
当在执行完var fn1 = outerTest();之后,变量fn1实际上是指向了函数innerTest,
那么接下来如果再执行fn1()就会改变num变量的值, 当然这个过程通常懂一点程序执行流程也可以分析出来!
关键不同的是之后继续执行fn1()输出的却是num变量累加之后的结果! 你肯定想知道为什么会累加!对吧!
首先因为函数innerTest引用了函数outerTest内部的变量或者数据,再然后重点来了:
当一个局部函数或匿名函数被定义的时候,那么它的作用域链也会被初始化,并且虽然有的时候局部函数即便是没有被调用,但是它会执行一个动作: 就是复制一份父函数的作用域链, 并且再将此作用域链的第0位插入该未调用函数的变量对象,等到该函数被调用了就激活为活动对象
如果实在你还无法理解这里的【作用域链】,那么你可以理解为是一种描述路径的术语, 沿着该路径可以找到需要的变量值!
再次回到闭包的概念上来, 也就是当一个子函数引用了父级函数的某个变量或数据,那么 闭包其实就产生了
并且这个变量或数据的生命周期始终能保持使用,就能间接保持原构父级函数 在内存中的变量对象不会消失
所以尽管outerTest()函数已经调用结束, 但是子函数却始终能引用到该父级函数中的变量的值,并且该变量值只能通这种方法来访问!
即使再次调用相同的outerTest()函数,但只会生成相对应的变量对象,新的变量对象只是对应新的值, 和上次那次调用的是各自独立的!
如图
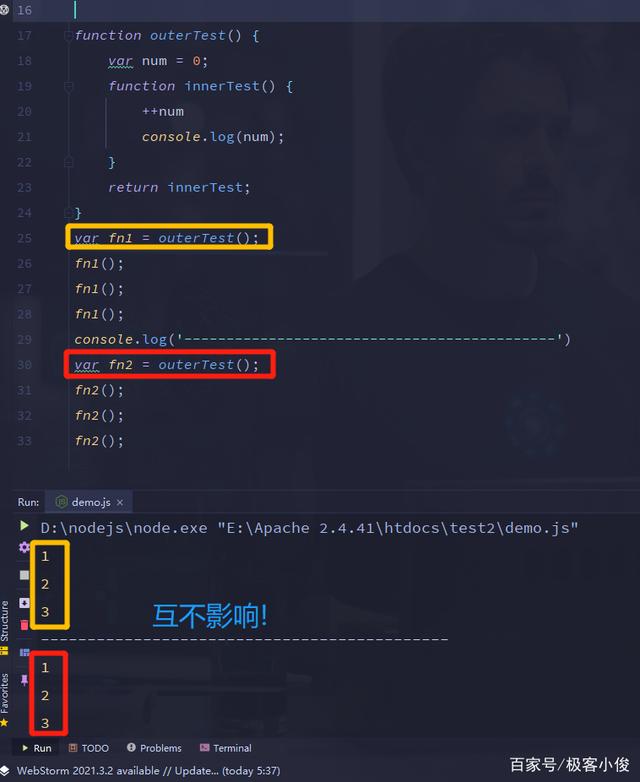
简而言之 在嵌套在父级函数内部的子函数被定义时,并且也引用了父级函数的数据时就产生了闭包
需要重点注意的是: 一个闭包内对变量的修改,不会影响到另外一个闭包中的变量
以上案例就是在outerTest函数执行完并返回后,闭包使得JS中的的垃圾回收机制GC(Garbage collection)不会收回outerTest函数所占用的资源,这里指的资源是它的变量对象, 因为outerTest函数的内部函数innerTest的执行一直需要依赖outerTest函数中的变量或者其他数据。这就是对闭包产生和特性最直白通俗的描述!
那么现在回过头来再次理解为什么每次调用fn1()函数 变量num会累加? 看下面这张图!
如图
因为由于闭包的存在使得函数outerTest返回后,函数outerTest中的num变量其实始终存在与内存中,这样每次执行fn1(),都会找到内存中与之对应outerTest函数的变量对象的num变量进行累加1后,输出num的值
1.2 JAVA中的闭包
对于Java来说,可以理解为主要是两种的闭包方式:
-
内部类
-
lambda表达式
其中内部类除了本身的内部类还有局部内部类、匿名内部类。我们以最简洁的匿名内部类来举例:

此时say方法中便捕获了length属性,而如果你使用的是足够版本的IDE的话,获取还会提示你:
Anonymous new ISay() can be replaced with lambda
替换后:

那么这时候你就会发现,此时return的对象就是一个通过匿名后直接描述的函数,而这个函数同时还关联了上下文之外的环境信息。
而在java8中lambda的中我们可以通过函数式编程接口直接接收这种闭包,这些接口常用的为:
-
Supplier<T>
-
Predicate<T>
-
Function<T, R>
关于函数式接口本文就不展开了,但是利用函数式接口,我们就可以这样传递一个闭包:

此时say返回的就不是String的结果了,而是直接将闭包本身返回了。而这个闭包在创建的时候就已经绑定了所需要的环境属性。所以我们可以在需要的时候再调用闭包,并且不用再关心它到底依赖了其他哪些变量:

1.3 c++中的闭包
对于c++来说,可以理解为主要是返回函数对象(重构了operator()的类的对象),包括:
-
以值传递的方式构造的std::function函数对象
-
以[=]值传递的方式引入外围变量的lambda表达式
其实,lambda表达式在编译时:
1、编译器先为其自动生成一个类,这个类重构了operator()操作符,对应lambda表达式引入的外围变量分别有一个成员变量与之对应。
2、生成一个1中的类的对象(其实就是一个函数对象),用lambda表达式引入的外围变量初始化给这个类的成员变量。
如:
std::function<int()()> A::get_countor() {
int count = 0;
return [=](){
count++;
};
}2 闭包的应用场景
2.1 应用场景1 代码模块化
闭包的应用场景主要是用于模块化
闭包可以一定程度上保护函数内的变量安全。
还是刚才的JS案例举例!
outerTest函数中的num变量只有innerTest函数才能访问,而无法通过其他途径访问到,因此保护了num变量的安全性, 所以闭包模块化基本可以解决函数污染或变量随意被修改问题!
比如说Java、php等语言中有支持将方法声明为私有,它们只能被同一个类中的其它方法所调用。
而 js是没有这种原生支持的,但我们可以使用闭包来模拟私有方法。
私有方法不仅仅有利于限制对代码的访问权限, 还提供了管理全局命名空间的强大能力,避免非核心的方法弄乱了代码的公共接口部分。
2.2 应用场景2 在内存中保持变量数据一直不丢失!
还是以最开始的例子, 由于闭包的影响,函数outerTest中num变量会一直存在于内存中,因此每次执行外部的fn1()时,都会给num变量进行累加!
所以每累加一次也就是每调用一次fn1() 就会去内存中一层层寻找outerTest函数的变量对象里面的num进行累加!
现在完全明白了闭包了吧!
3 最后
闭包本身是一种面向抽象编程,屏蔽细节的设计原则。在良好的设计下,可以通过闭包来屏蔽对于环境信息的感知,从而简化外部对于系统理解的成本,提高系统的易用性。
参考:

















 846
846

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









