






前期准备工作:
1、打开虚拟机,连接xshell
测试是否可以成功连接外网
例如:ping www.baidu.com
2、主机名的配置
使用cat /etc/hostname命令分别查看主机名称:
[root@node01 ~]# cat /etc/hostname
node01[root@node02 ~]# cat /etc/hostname
node02[root@node03 ~]# cat /etc/hostname
node033、检查主机域名
使用cat /etc/hosts命令分别检查三台虚拟机
[root@node02 ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.67.110 node01 node01.hadoop.com
192.168.67.120 node02 node02.hadoop.com
192.168.67.130 node03 node03.hadoop.com对应为IP地址 、主机名称(hostname) 、Hadoop映射地址
注:无论Linux系统还是window系统,主机域名都在此文件中设置
4、使用systemctl status firewalld命令分别查看三台虚拟机的防火墙状态
[root@node01 ~]# systemctl status firewalld
● firewalld.service - firewalld - dynamic firewall daemon
Loaded: loaded (/usr/lib/systemd/system/firewalld.service; disabled; vendor preset: enabled)
Active: inactive (dead)
Docs: man:firewalld(1)
小圆点为灰色并显示dynamic firewall deamon则防火墙为关闭状态
5、检查ssh免密登录
利用ssh命令可以进入任意一个节点上即为成功
[root@node01 ~]# ssh node02
Last login: Thu Sep 15 09:34:35 2022 from 192.168.67.1
[root@node02 ~]# ssh node01
Last login: Thu Sep 15 09:34:34 2022 from 192.168.67.1
[root@node01 ~]# ssh node03
Last login: Thu Sep 15 09:34:38 2022 from 192.168.67.1
[root@node03 ~]# ssh node01
Last login: Thu Sep 15 10:04:11 2022 from node02
[root@node01 ~]# 6、使用 java -version命令分别检查三台虚拟机的Java环境
[root@node01 ~]# java -version
java version "1.8.0_144"
Java(TM) SE Runtime Environment (build 1.8.0_144-b01)
Java HotSpot(TM) 64-Bit Server VM (build 25.144-b01, mixed mode)检查完成后正式进入HDFS完全分布式环境配置
创建安装目录:
进入opt:cd /opt
创建software文件夹:mkdir software
进入software文件夹:cd software/
创建hadoop文件夹:mkdir hadoop
进入hadoop文件夹:cd hadoop/
创建hdfs文件夹:mkdir hdfs
进入hdfs文件夹:cd hdfs/
创建data、name、tmp目录:
mkdir data
mkdir name
mkdir tmp
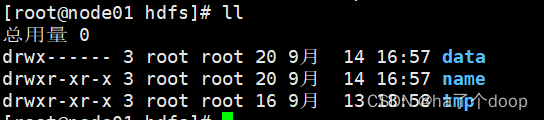
进入/opt/software/hadoop/hdfs路径,在此路径下分别存放data、name、tmp三个路径,分别存放对应内容
创建完成后返回到/opt/software/hadoop路径,上传Hadoop安装包:hadoop-2.9.2.tar.gz,上传成功后,使用ll命令查看上传结果
解压hadoop-2.9.2.tar.gz安装包:tar -zxvf hadoop-2.9.2.tar.gz
解压过后生成一个名为hadoop-2.9.2的目录:

hadoop-2.9.2的目录中为整个Hadoop集群中需要用到的东西
其中etc/hadoop中存放所有要用到的配置文件,我们需要从中挑取一些文件来维持Hadoop集群的配置
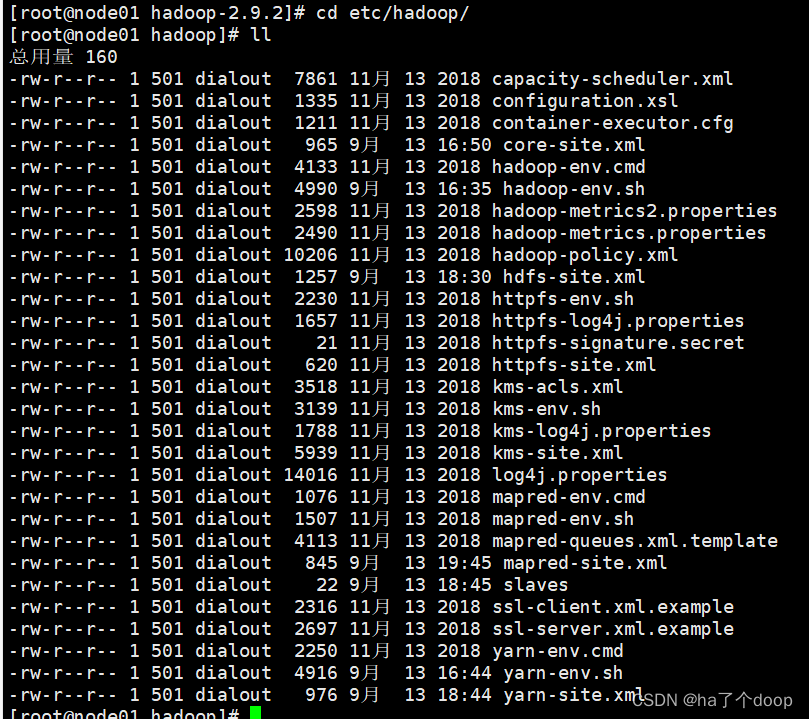
开始配置HADOOP_HOME 的环境变量
1、进入etc/profile文件中进行编辑
2、在文件的最底部添加以下配置值
单击键盘a键进行编辑
export JAVA_HOME=/usr/local/java/jdk1.8
export CLASSPATH=.:${JAVA_HOME}/jre/lib/rt.jar:${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar
export PATH=$PATH:${JAVA_HOME}/bin编辑完成后,Esc键退出编辑模式
输入 :wq 保存并退出
 3、测试Hadoop是否安装成功
3、测试Hadoop是否安装成功
[root@node01 ~]# hadoop version
Hadoop 2.9.2
Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r 826afbeae31ca687bc2f8471dc841b66ed2c6704
Compiled by ajisaka on 2018-11-13T12:42Z
Compiled with protoc 2.5.0
From source with checksum 3a9939967262218aa556c684d107985
This command was run using /opt/software/hadoop/hadoop-2.9.2/share/hadoop/common/hadoop-common-2.9.2.jar查看/opt/software/hadoop/hadoop-2.9.2/etc/hadoop路径中的文件
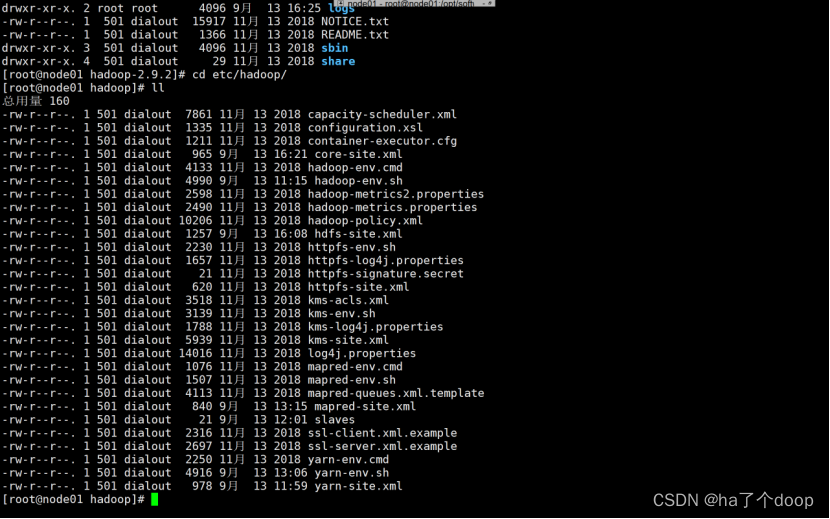
4、使用vi hadoop-env.sh命令配置hadoop-env.sh文件
[root@node01 hadoop]# vi hadoop-env.sh 修改JAVA_HOME和HADOOP配置文件的路径
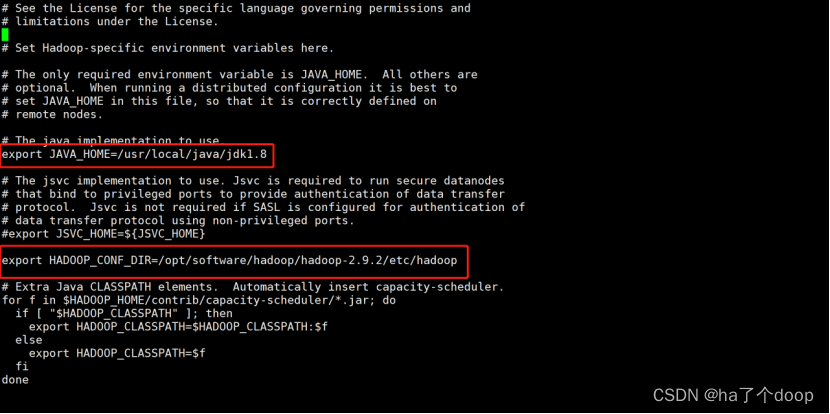
配置值为:
export JAVA_HOME=/usr/local/java/jdk1.8
export HADOOP_CONF_DIR=/opt/software/hadoop/hadoop-2.9.2/etc/hadoop
5、在/opt/software/hadoop/hadoop-2.9.2/etc/hadoop/路径下配置yarn-env.sh文件
[root@node01 hadoop]# cd /opt/software/hadoop/hadoop-2.9.2/etc/hadoop/
[root@node01 hadoop]# vi hadoop-env.sh删除#号键,并添加JAVA_HOME环境变量
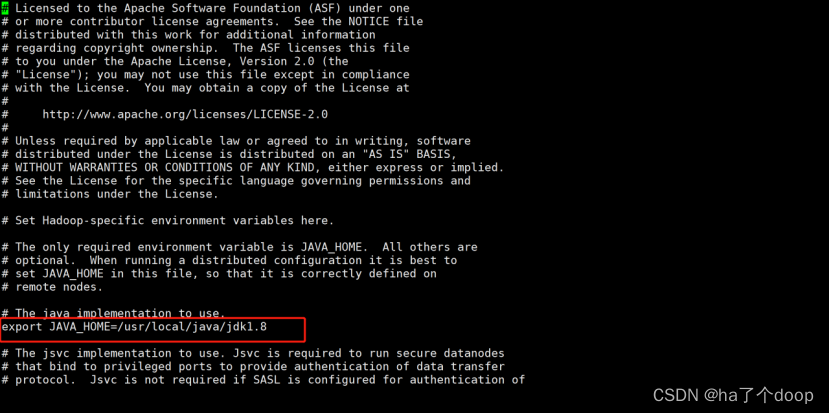
配置值为:
export JAVA_HOME=/usr/local/java/jdk1.8
6、配置core-site.xml
配置namenode ,把文件系统点改成node01
这里有两个配置:
fs.defaultFS是将指定集群的文件系统类型写成分布式文件系统(HDFS)
hadoop.tmp.dir是hadoop的一个临时文件目录
[root@node01 hadoop]# vi core-site.xml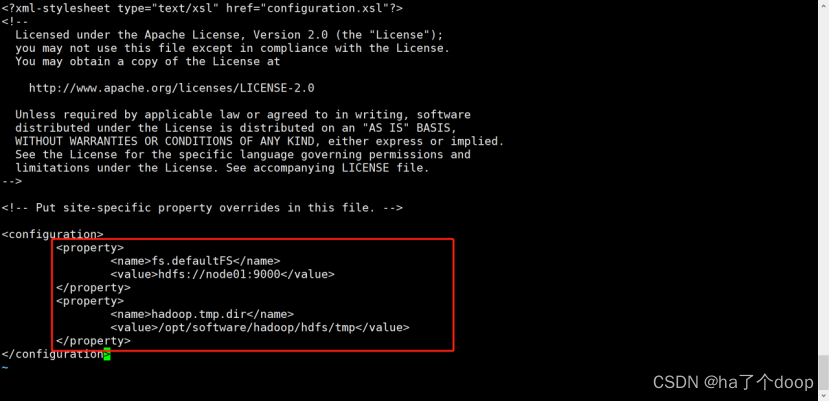
配置值为:
<property>
<name>fs.defaultFS</name>
<value>hdfs://node01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/software/hadoop/hdfs/tmp</value>
</property>
7、配置hdfs-site.xml
要实行三副本策略,表示副本数是3,原始dfs.replication是1,改为3
开启缓存
不开启文件权限
因为这个缓存是跟机器的位数是有关系的,所以我们先用ulimit -l命令来查看一下机器位数。
不过我们的虚拟机一般都是64位的系统所以大部分都会显示64。
所以我们需要配置的缓存大小就是64×1024也就是65536;如果是32位的系统,那么配置的缓存就是32×1
[root@node01 hadoop]# ulimit -l
64
[root@node01 hadoop]# vi hdfs-site.xml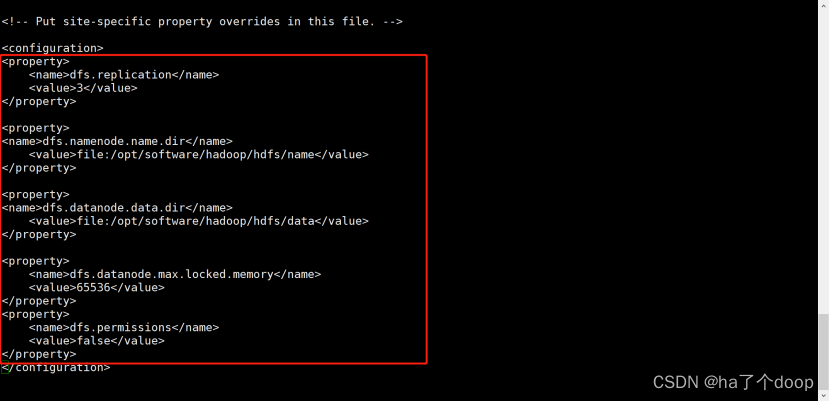
配置值为:
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/software/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/software/hadoop/hdfs/data</value>
</property>
<property>
<name>dfs.datanode.max.locked.memory</name>
<value>65536</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
8、配置mapred-site.xml
此时,我们会发现没有mapred-site.xml文件,只有一个mapred-site.xml.template临时文件。
所以我们把文件重命名或者复制文件就可以了。
重命名:
[root@node01 hadoop]# mv mapred-site.xml.template mapred-site.xml复制:
[root@node01 hadoop]# cp mapred-site.xml.template mapred-site.xml接着配置mapred-site.xml
[root@node01 ~]# cd /opt/software/hadoop/hadoop-2.9.2/etc/hadoop/
[root@node01 hadoop]# vi mapred-site.xml编辑的内容是为了说明mapereduce整个的一个资源分配是使用yarn这样的一个组件
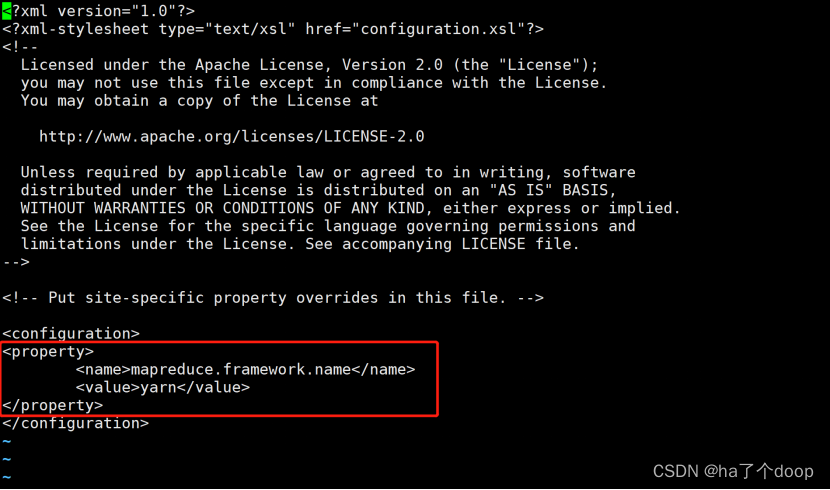
配置值:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
9、配置yarn-site.xml
在这里要加入三条配置
一个是yarn相关资源服务器的主机名称,也就是resourcemanager,配置为node01。
一个是nodemanager.aux-services,是和MapReduce计算相关的。把这个值赋成mapreduce_shuffle。
还有一个nodemanager.vmem-check-enabled是去关闭虚拟内存检查的,把这个值设成false把它关闭掉。
[root@node01 hadoop]# vi yarn-site.xml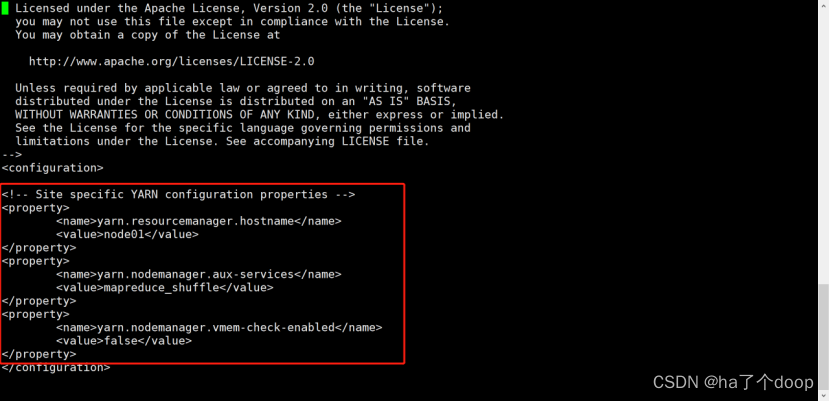
配置值:
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
10、配置slaves文件
去配置datanode需要的一个节点,在文件里写入三个节点主机名称就可以了
[root@node01 hadoop]# vi slaves
以上所有的配置信息就配置完成了。
同步配置信息
整个配置写完之后就把所有的配置信息在node02,node03上同时分发一份;需要在node02和node03上分别创建一个目录/路径
[root@node02 ~]# cd /opt/
[root@node02 opt]# mkdir software然后我们将Hadoop01上面整个关于Hadoop的文件都发到02和03上面
也就是把01上的配置同步到02,03上面
[root@node01 ~]# cd /opt/software/
[root@node01 software]# scp -r hadoop/ node02:$PWD
[root@node01 software]# scp -r hadoop/ node03:$PWD传完之后可以检查一下node02和node03
 可以看到,文件已经传到node02和node03当中
可以看到,文件已经传到node02和node03当中
在02和03里去配置Hadoop相关的环境变量
[root@node02 hadoop]# vi /etc/profile[root@node03 hadoop]# vi /etc/profile在文件最下放添加配置,配置值为:
export HADOOP_HOME=/opt/software/hadoop/hadoop-2.9.2
export PATH=${PATH}:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin
配置完成后要加载配置文件,使得配置文件生效。简单来说就是刷新一下
[root@node02 hadoop]# source /etc/profile[root@node03 hadoop]# source /etc/profile最后检查Hadoop
[root@node02 hadoop]# hadoop version
Hadoop 2.9.2
Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r 826afbeae31ca687bc2f8471dc841b66ed2c6704
Compiled by ajisaka on 2018-11-13T12:42Z
Compiled with protoc 2.5.0
From source with checksum 3a9939967262218aa556c684d107985
This command was run using /opt/software/hadoop/hadoop-2.9.2/share/hadoop/common/hadoop-common-2.9.2.jar
[root@node02 hadoop]#
[root@node03 hadoop]# hadoop versionnode02和node03整个的配置已经完成,至此整个前期HDFS完全分布式的配置就已经完成了。














 341
341











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









