






Amazon Redshift数据迁移到MaxCompute
Amazon Redshift 中的数据迁移到MaxCompute中经常需要先卸载到S3中,再到阿里云对象存储OSS中,大数据计算服务MaxCompute然后再通过外部表的方式直接读取OSS中的数据。
如下示意图:

前提条件
本文以SQL Workbench/J工具来连接Reshift进行案例演示,其中用了Reshift官方的Query editor发现经常报一些奇怪的错误。建议使用SQL Workbench/J。
- 下载Amazon Redshift JDBC驱动程序,推荐4.2https://s3.amazonaws.com/redshift-downloads/drivers/jdbc/1.2.16.1027/RedshiftJDBC42-1.2.16.1027.jar
- 在SQL Workbench/J中新建Drivers,选择下载的驱动程序jar,并填写Classname为 com.amazon.redshift.jdbc42.Driver。

- 配置新连接,选择新建的Driver,并复制JDBC url地址、数据库用户名和密码并勾选Autocommit。

如果在配置过程中发现一只connection time out,需要在ecs的vpc安全组中配置安全策略。具体详见:https://docs.aws.amazon.com/zh_cn/redshift/latest/gsg/rs-gsg-authorize-cluster-access.html
Amazon Redshift数据预览
方式一:在AWS指定的query editor中进行数据预览,如下所示:

方式二:使用Workbench/J进行数据预览,如下图所示:
具体Workbench/J的下载和配置详见:https://docs.aws.amazon.com/zh_cn/redshift/latest/mgmt/connecting-using-workbench.html
(下图为JDBC驱动下载和JDBC URL查看页面)


卸载数据到Amazon S3
在卸载数据到S3之前一定要确保IAM权足够,否则如果您在运行 COPY、UNLOAD 或 CREATE LIBRARY 命令时收到错误消息 S3ServiceException: Access Denied,则您的集群对于 Amazon S3 没有适当的访问权限。如下:

创建 IAM 角色以允许 Amazon Redshift 集群访问 S3服务
- step1:进入https://console.aws.amazon.com/iam/home#/roles,创建role。

- step2:选择Redshift服务,并选择Redshift-Customizable

- step3:搜索策略S3,找到AmazonS3FullAccess,点击下一步。

- step4:命名角色为redshiftunload。


- step5:打开刚定义的role并复制角色ARN。(unload命令会用到)

- step6:进入Redshift集群,打开管理IAM角色

- step7:选择刚定义的redshiftunload角色并应用更改。

执行unload命令卸载数据
以管道分隔符导出数据
以默认管道符号(|)的方式将数据卸载到对应的S3存储桶中,并以venue_为前缀进行存储,如下:
unload ('select * from venue')
to 's3://aws2oss/venue_'
iam_role '<新建的redshiftunload角色对应的ARN>';
--parallel off; --连续卸载,UNLOAD 将一次写入一个文件,每个文件的大小最多为 6.2 GB
执行效果图如下:

进入Amazon S3对应的存储桶中可以查看到有两份文件,且以venue_为前缀的,可以打开文件查看下数据。

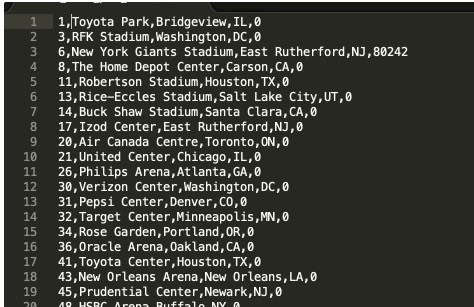
数据如下,以管道字符(|)分隔:

以指标符导出数据
要将相同的结果集卸载到制表符分隔的文件中,请发出下面的命令:
unload ('select * from venue')
to 's3://aws2oss/venue_'
iam_role '<新建的redshiftunload角色对应的ARN>'
delimiter as '\t';

打开文件可以预览到数据文件如下:

----为了MaxCompute更方便的读取数据,我们采用以逗号(,)分隔--```sql
unload ('select * from venue')
to 's3://aws2oss/venue_'
iam_role '<新建的redshiftunload角色对应的ARN>'
delimiter as ','
NULL AS '0';
更多关于unload的命令说明详见:[https://docs.aws.amazon.com/zh_cn/redshift/latest/dg/r_UNLOAD.html](https://docs.aws.amazon.com/zh_cn/redshift/latest/dg/r_UNLOAD.html)
<a name="dbfe35f7"></a>
# Amazon S3无缝切换到OSS
> 在线迁移工具只支持同一个国家的数据源,针对不同国家数据源迁移建议用户采用OSS迁移工具,自己部署迁移服务并且购买专线来完成,详见:[https://help.aliyun.com/document_detail/56990.html](https://help.aliyun.com/document_detail/56990.html?spm=5176.208357.1107607.35.68b6390frmzT6x)
OSS提供了S3 API的兼容性,可以让您的数据从AWS S3无缝迁移到阿里云OSS上。从AWS S3迁移到OSS后,您仍然可以使用S3 API访问OSS。更多可以详见[S3迁移教程](https://help.aliyun.com/document_detail/95127.html?spm=a2c4g.11186623.2.12.65cd6ac6kayaMa#concept-pyw-sjg-qfb)。
<a name="66a56ac6"></a>
## 背景信息
① 执行在线迁移任务过程中,读取Amazon S3数据会产生公网流出流量费,该费用由Amazon方收取。<br />② 在线迁移默认不支持跨境迁移数据,若有跨境数据迁移需求需要提交工单来申请配置任务的权限。
<a name="88210852"></a>
## 准备工作
<a name="ed3070e2"></a>
### Amazon S3前提工作
> 接下来以RAM子账号来演示Amazon S3数据迁移到Aliyun OSS上。
* 预估迁移数据,进入管控台中确认S3中有的存储量与文件数量。
* 创建迁移密钥,进入AWS IAM页面中创建用户并赋予AmazonS3ReadOnlyAccess权限。
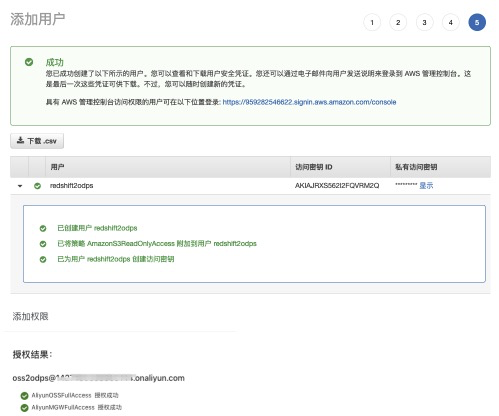
* 添加用户-->访问类型(编程访问,AK信息)-->赋予AmazonS3ReadOnlyAccess权限-->记录AK信息。
step1:进入IAM,选择添加用户。<br />![image.png]
step2:新增用户并勾选创建AK。<br />
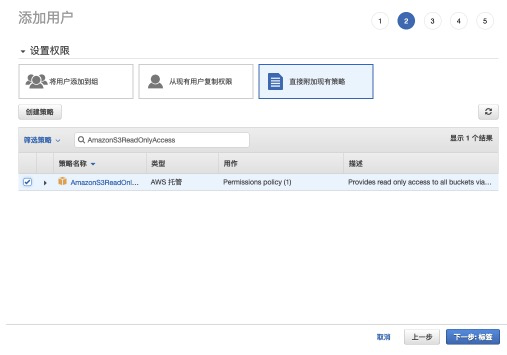
step3:选择直接附加现有策略,并赋予AmazonS3ReadOnlyAccess权限。<br />
step4:记录AK信息,在数据迁移中会用到。<br />
<a name="75e5510f"></a>
### Aliyun OSS前提工作
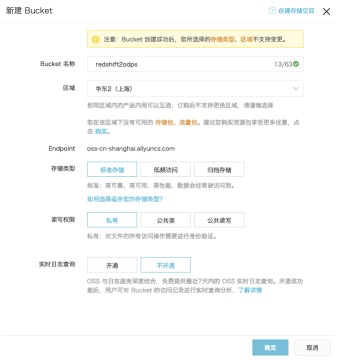
* 阿里云OSS相关操作,新创建bucket:
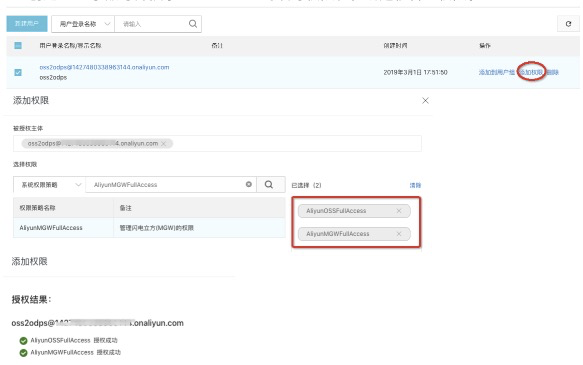
* 创建RAM子账号并授予OSS bucket的读写权限和在线迁移管理权限。
<a name="582bdcd8"></a>
## 迁移实施
> 迁移会占用源端和目的端的网络资源;迁移需要检查源端和目的端文件,如果存在文件名相同且源端的最后更新时间少于目的端,会进行覆盖。
* 进入阿里云数据在线迁移控制台:[https://mgw.console.aliyun.com/?spm=a2c4g.11186623.2.11.10fe1e02iYSAhv#/job?_k=6w2hbo](https://mgw.console.aliyun.com/?spm=a2c4g.11186623.2.11.10fe1e02iYSAhv#/job?_k=6w2hbo),并以《Aliyun OSS前提工作》中新建的子账号登录。
* 进入数据迁移服务-数据地址-数据类型(其他),如下:
**【创建源地址:】**<br />
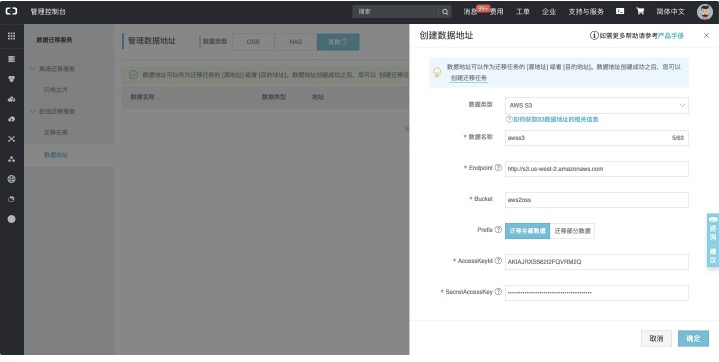
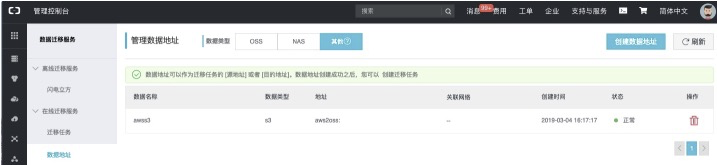
具体配置项说明详见:[https://help.aliyun.com/document_detail/95159.html](https://help.aliyun.com/document_detail/95159.html?spm=a2c4g.11186623.6.561.34e047f6yvZnaw)<br />**【创建目标地址:】**<br />
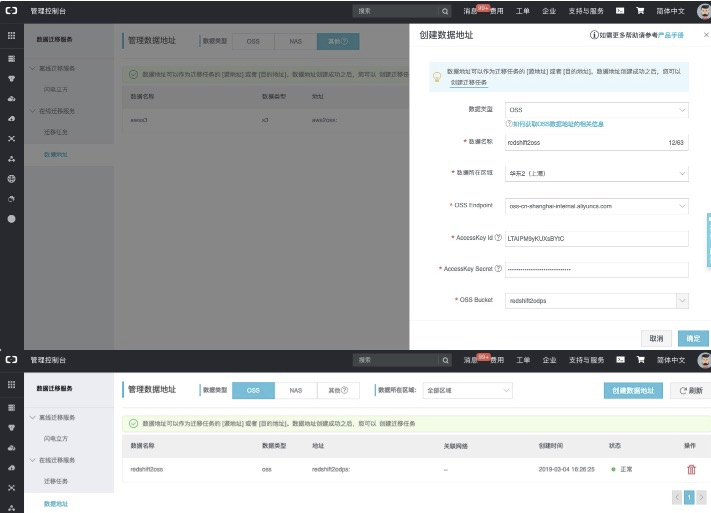
具体配置项说明详见:[https://help.aliyun.com/document_detail/95159.html](https://help.aliyun.com/document_detail/95159.html?spm=a2c4g.11186623.6.561.34e047f6yvZnaw)
<a name="b4361e56"></a>
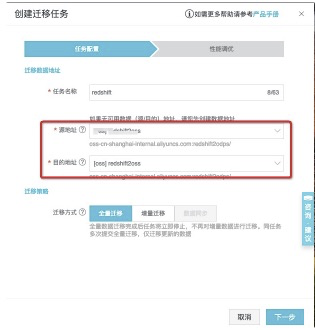
## 创建迁移任务
从左侧tab页面中找到迁移任务,并进入页面,点击创建迁移任务。<br />![image.png]
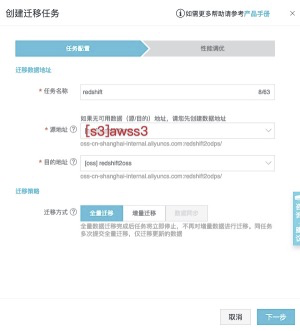
---->OSS中的数据如下:<br />
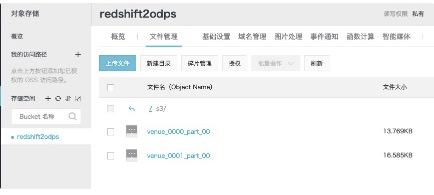
<a name="ebdc286b"></a>
# MaxCompute直接加载OSS数据
<a name="98a315c0"></a>
## 授权
在查询OSS上数据之前,需要对将OSS的数据相关权限赋给MaxCompute的访问账号,授权详见[授权文档](https://help.aliyun.com/document_detail/45389.html?spm=a2c4g.11186623.6.702.62552a95jceToT)。<br />MaxCompute需要直接访问OSS的数据,前提需要将OSS的数据相关权限赋给MaxCompute的访问账号,您可通过以下方式授予权限:
1. 当MaxCompute和OSS的owner是同一个账号时,可以直接登录阿里云账号后,[点击此处完成一键授权](https://ram.console.aliyun.com/?spm=a2c4g.11186623.2.16.4f761cdfaNk5XH#/role/authorize?request=%7B%22Requests%22:%20%7B%22request1%22:%20%7B%22RoleName%22:%20%22AliyunODPSDefaultRole%22,%20%22TemplateId%22:%20%22DefaultRole%22%7D%7D,%20%22ReturnUrl%22:%20%22https:%2F%2Fram.console.aliyun.com%2F%22,%20%22Service%22:%20%22ODPS%22%7D)。
1. 若MaxCompute和OSS不是同一个账号,此处需由OSS账号登录进行授权,详见[文档](https://help.aliyun.com/document_detail/45389.html?spm=a2c4g.11186623.6.702.62552a95jceToT)。
<a name="a6dbe7f5"></a>
## 创建外部表
在DataWorks中创建外部表,如下图所示:<br />
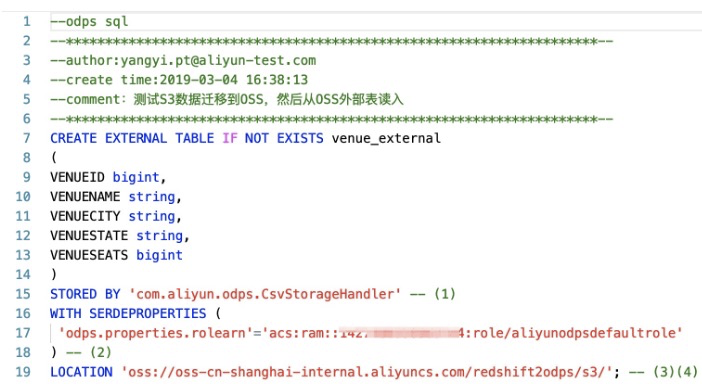
创建MaxCompute外部表DDL语句:CREATE EXTERNAL TABLE IF NOT EXISTS venue_external
(
VENUEID bigint,
VENUENAME string,
VENUECITY string,
VENUESTATE string,
VENUESEATS bigint
)
STORED BY 'com.aliyun.odps.CsvStorageHandler' -- (1)
WITH SERDEPROPERTIES (
'odps.properties.rolearn'='acs:ram::*****:role/aliyunodpsdefaultrole'
) -- (2)
LOCATION 'oss://oss-cn-shanghai-internal.aliyuncs.com/redshift2odps/s3/'; -- (3)(4)
* com.aliyun.odps.CsvStorageHandler是内置的处理CSV格式文件的StorageHandler,它定义了如何读写CSV文件。您只需指明这个名字,相关逻辑已经由系统实现。如果用户在数据卸载到S3时候自定义了其他分隔符那么,MaxCompute也支持自定义分隔符的Handler,详见:[https://help.aliyun.com/document_detail/45389.html](https://help.aliyun.com/document_detail/45389.html)
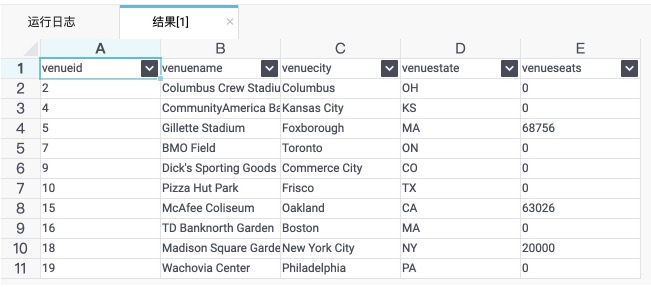
可以直接查询返回结果:<br />select * from venue_external limit 10;
DataWorks上执行的结果如下图所示:<br />
<a name="189c0f78"></a>
## 创建内部表固化数据
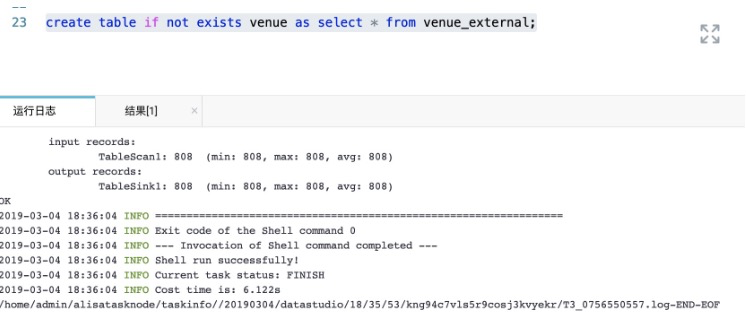
如果后续还需要做复杂的查询且数据量特别大的情况下,建议将外部表转换为内部表,具体示意如下:<br />create table if not exists venue as select * from venue_external;<br />
本文作者:祎休
本文为云栖社区原创内容,未经允许不得转载。















 319
319

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









