









作者前言:汇总一些实际开发中,经常会使用的技术栈以及需要注意的地方,特此做一下笔记,加深下记忆。大家有兴趣也可以一起讨论下,感谢pig团队,部分文档参考git来源:https://github.com/pig-mesh/excel-spring-boot-starter
一. 数据库锁用法
前言:锁通常应用在多个线程对一个同一个资源进行同时操作,需要有序性和正确性的操作。锁的其实是排队,而数据库的锁,则是在数据库上进行操作的时候进行排队。
乐观锁
1.乐观锁更新是按照顺序执行的,在操作数据库数据的时候,对数据不加锁,而是通过对数据的版本或者时间戳的对比来保证操作。更新前先获取这条记录的版本或者时间戳,在更新数据中,对比记录的版本或者时间戳,如果版本或者时间戳一样,则会继续更新。如果不一致,停止更新数据记录。
2.常用于数据库操作的并发非常少场景,通过版本控制来防止脏数据的产生,更新按照顺序执行的。
其伪代码如下。
int version = executeSql("select version from... where id = $id");
// 取出改当前版本号,再更新校对,校队成功+1
boolean succ = executeSql("update version= version + 1 where id = $id and version = $version");后记:乐观锁某种程度上来说,只会有一个更新请求会成功,而其他的更新请求会失败。所以,乐观锁适用于并发不高的场景,通常是在传统的行业里应用在 ERP 系统,来防止多个账号同时修改同一份数据。
悲观锁
悲观锁在更新数据之前对数据上锁,更新过程中防止任何其他的请求更新数据而产生脏数据,更新完成之后,再释放锁,这里的锁是数据库级别的锁。
后记:悲观锁是在数据库引擎层次实现的,它能够阻止所有的数据库操作。但是为了更新一条数据,需要提前对这条数据上锁,直到这条数据处理完成,其他请求才能更新数据,所以悲观锁的性能比较低下,却保证更新数据的强一致性,因此有些账户、资金处理系统可以使用这种方式。
行级锁
不是所有更新操作都要加锁的,数据库本身有行级别的锁,在更新行数据的时候是有同步和互斥操作的,所以可以利用这个行级锁的特性,来保证高并发的场景下更新数据。
行级锁的粒度非常细,上锁的时间窗口也最少,只有更新数据记录的那一刻,才会对记录上锁,因此,能大大减少数据库操作的冲突,发生锁冲突的概率最低,并发度也最高。
其伪代码如下。
boolean result = executeSql("update ... set amount = amount - 1 where id = $id and amount > 1")后记:通常在扣减库存的场景下使用行级锁,这样可以通过数据库引擎本身对记录加锁的控制,保证数据库更新的安全性,并且通过 where 语句的条件,保证库存不会被减到0以下,也就是能够有效的控制超卖的场景,如下代码。
二. 缓存用法
作者前言:缓存主要基于服务器的内存,在使用缓存时必须先对应用需要注意缓存的数据大小、数据结构、缓存数量、失效时间。
缓存穿透:redis跟数据库都不存在,比如拿一个不存在的用户请求,请求就会打到db上。
解决方式:生成一个有效时间的占位数据来代替。
缓存击穿:redis不存在,数据库存在,一般是redis的某个key突然过期,前端并发请求到db。
解决方式:可以通过redis分布式锁或者同步代码块,只让一个线程可以访问db再更新缓存。
缓存脏数据:延迟双删(不靠谱),先删除redis,再更新,再删除redis。应该先更新db,再删除redis。
[要点1]: 缓存一般是用来加速数据库的读操作的,读的顺序是先缓存,后数据库;写的顺序是先数据库,后缓 存。
[要点2]: 缓存的数据不易过大,尤其是 Redis,因为 Redis 使用的是单线程模型,单个缓存 key 的数据过大时,会阻塞其他请求的处理。
[要点3]: 任何缓存的 key 都必须设定缓存失效时间,且失效时间不能集中在某一点,可采取随机算法处理过期时间,否则会导致缓存占满内存或者缓存穿透。
[要点3]: 业务上应避免批量删除缓存处理,如redis的自带的deleteByPrefix,特殊情况下会阻塞Redis。如果必须如此,可采用以下重写方式:
其伪代码如下。
/**
* 按照前缀删除key
* SCAN方式
*
* @param prefix
*/
public void deleteByPrefix(String prefix) {
ScanOptions options = ScanOptions.scanOptions()
// 匹配值
.match(prefix + "*")
// 步进值
.count(1000)
.build();
Cursor<String> cursor = (Cursor<String>) redisTemplate.executeWithStickyConnection(
redisConnection -> new ConvertingCursor<>(redisConnection.scan(options),
redisTemplate.getKeySerializer()::deserialize));
// 执行删除
cursor.forEachRemaining(key -> {
redisTemplate.delete(key);
});
// 释放链接
try {
cursor.close();
} catch (IOException e) {
log.error("释放Redis连接异常!", e);
}
}三. 数据库事务
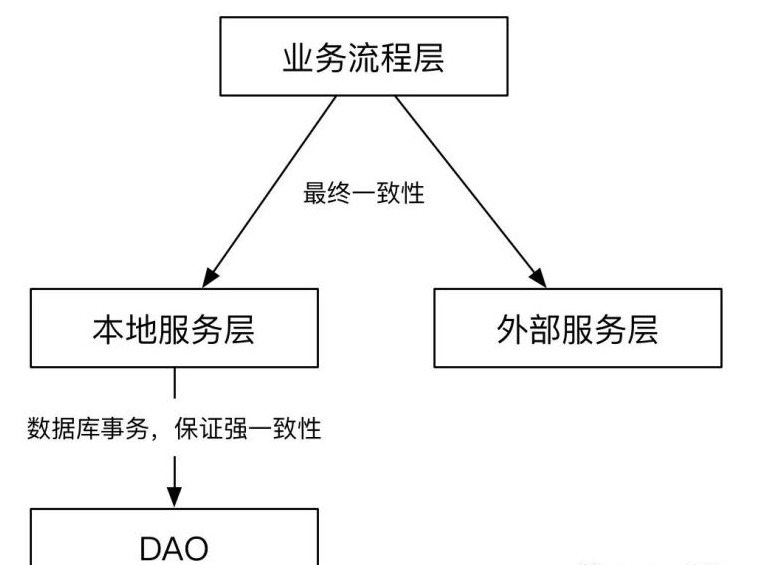
前言:微服务中经常会出现在数据库事务中调用远程服务,由于远程服务超时而拉长事务,导致数据库瘫痪的情况,因此,在事务处理过程中,禁止执行可能产生线程阻塞的调用,例如:锁等待、远程调用等。
另外,事务要尽可能保持短事务,一个事务中不要有太多的操作,或者做太多的事情,长时间操作事务会影响或堵塞其他的请求,最终造成数据库故障,同一事务中大量的数据操作会引起锁的范围和影响扩大,易造成数据库的其他操作阻塞而导致短暂的不可用。
因此,如果业务允许,要尽可能用短事务来代替长事务,降低事务执行时间,减少锁的时长,使用最终一致性来保证数据的一致性原则。
对此我采用以下结构图来表述:
四. 幂等和防重
前言:幂等是一个特性,一个操作执行多次,产生的结果是一样的,就成为幂等。 防重是实现幂等的一种方法,防重有多种方法。
方法如下:
- 使用数据库表的唯一键进行滤重,拒绝重复的请求,这通常用在增加记录上,只要记录有唯一的主键,这种方法失踪奏效。
- 使用缓存机制进行处理,设置一个唯一ID,过期3秒,来此避免重复处理。
五. 索引使用
前言:一般数据来校验索引是否生效,可以通过explain函数来验证。
- 函数介绍
key: 如果为NULL,则没有使用索引;
key_len:使用的索引的长度,长度越短越好;
ref:显示索引的哪一列被使用了;
rows:返回请求数据的行数;
- 常导致造成索引生效的场景
第一种:where 子句中使用 != 或 <> 操作符,否则会全表扫描。
第二种:where 子句中使用 or 来连接条件,否则会全表扫描。
第三种:列类型是字符串,数据使用引号'',否则索引失效。
第四种:like的模糊查询以 % 开头,否则索引失效。















 826
826











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









