







1、spark 前世今生
Spark SQL
SQL: MySQL、Oracle、DB2、SQLServer
很多小伙伴熟悉SQL语言
数据量越来越大 ==> 大数据(Hive、Spark Core)
直接使用SQL语句来对大数据进行分析:这是大家所追逐的梦想
person.txt ==> 存放在HDFS
1,zhangsan,30
2,lisi,31
3,wangwu,32
hive表:person
id:int name:string age:int
导入数据:load … 统计分析 select … from person
SQL on Hadoop 其实是Sql 作用在Hadoop之上 Hive Shark Impala: Cloudera Presto Drill
Hive: on MapReduce
SQL ==> MapReduce ==> Hadoop Cluster
Shark: on Spark
基于Hive源码进行改造
Spark SQL: on Spark 由自己的执行计划进行解析不依赖Hive
Hive on Spark 是在hive之上添加了个spark引擎
共同点: metastore(元数据进行存储) mysql
Spark SQL不仅仅是SQL这么简单的事情,它还能做更多的事情
Spark SQL is Apache Spark’s module for working with structured data.
译
Spark SQL是Apache Spark用于处理结构化数据的模块。
Seamlessly mix SQL queries with Spark programs.
Spark SQL lets you query structured data inside Spark programs, using either SQL or a familiar DataFrame API. Usable in Java, Scala, Python and R.
译
无缝地将SQL查询与Spark程序混合。
Spark SQL允许您使用SQL或熟悉的DataFrame API在Spark程序中查询结构化数据。可用于Java、Scala、Python和R。
results = spark.sql(
“SELECT * FROM people”)
names = results.map(lambda p: p.name) 将函数应用于SQL查询的结果
Uniform Data Access
Connect to any data source the same way.
DataFrames and SQL provide a common way to access a variety of data sources, including Hive, Avro, Parquet, ORC, JSON, and JDBC. You can even join data across these sources.
译
统一数据访问
以同样的方式连接到任何数据源。
DataFrames和SQL提供了访问各种数据源的通用方法,包括Hive、Avro、Parquet、ORC、JSON和JDBC。您甚至可以跨这些源连接数据。
spark.read.json(“s3n://…”)
.registerTempTable(“json”)
results = spark.sql(
“”“SELECT *
FROM people
JOIN json …”"") 查询并连接不同的数据源
Hive Integration
Run SQL or HiveQL queries on existing warehouses.
Spark SQL supports the HiveQL syntax as well as Hive SerDes and UDFs, allowing you to access existing Hive warehouses.
译
Hive集成
在现有仓库上运行SQL或HiveQL查询。
Spark SQL支持HiveQL语法以及Hive SerDes和udf,允许您访问现有的Hive仓库。

Standard Connectivity
Connect through JDBC or ODBC.
A server mode provides industry standard JDBC and ODBC connectivity for business intelligence tools.
译
标准连接
通过JDBC或ODBC连接。
服务器模式为商业智能工具提供行业标准的JDBC和ODBC连接。

Overview
Spark SQL is a Spark module for structured data processing. Unlike the basic Spark RDD API, the interfaces provided by Spark SQL provide Spark with more information about the structure of both the data and the computation being performed. Internally, Spark SQL uses this extra information to perform extra optimizations. There are several ways to interact with Spark SQL including SQL and the Dataset API. When computing a result the same execution engine is used, independent of which API/language you are using to express the computation. This unification means that developers can easily switch back and forth between different APIs based on which provides the most natural way to express a given transformation.
All of the examples on this page use sample data included in the Spark distribution and can be run in the spark-shell, pyspark shell, or sparkR shell
译
概述
Spark-SQL是一个用于结构化数据处理的Spark模块。与基本的Spark RDD API不同,Spark SQL提供的接口为Spark提供了有关数据结构和正在执行的计算的更多信息。在内部,Spark SQL使用这些额外的信息来执行额外的优化。与Spark SQL交互有几种方法,包括SQL和Dataset API。当计算一个结果时,使用相同的执行引擎,这与您用来表示计算的API/语言无关。这种统一意味着开发人员可以轻松地在不同的api之间来回切换,基于api,可以提供最自然的方式来表示给定的转换。
本页上的所有示例都使用Spark分布中包含的示例数据,可以在Spark shell、pyspark shell或sparkR shell中运行。
SQL
One use of Spark SQL is to execute SQL queries. Spark SQL can also be used to read data from an existing Hive installation. For more on how to configure this feature, please refer to the Hive Tables section. When running SQL from within another programming language the results will be returned as a Dataset/DataFrame. You can also interact with the SQL interface using the command-line or over JDBC/ODBC.
译
SQL语言
Spark SQL的一个用途是执行SQL查询。Spark SQL还可以用于从现有配置单元安装读取数据。有关如何配置此功能的详细信息,请参阅配置单元表部分。在另一种编程语言中运行SQL时,结果将作为Dataset/DataFrame返回。您还可以使用命令行或通过JDBC/ODBC与SQL接口交互。
Datasets and DataFrames
A Dataset is a distributed collection of data. Dataset is a new interface added in Spark 1.6 that provides the benefits of RDDs (strong typing, ability to use powerful lambda functions) with the benefits of Spark SQL’s optimized execution engine. A Dataset can be constructed from JVM objects and then manipulated using functional transformations (map, flatMap, filter, etc.). The Dataset API is available in Scala and Java. Python does not have the support for the Dataset API. But due to Python’s dynamic nature, many of the benefits of the Dataset API are already available (i.e. you can access the field of a row by name naturally row.columnName). The case for R is similar.
A DataFrame is a Dataset organized into named columns. It is conceptually equivalent to a table in a relational database or a data frame in R/Python, but with richer optimizations under the hood. DataFrames can be constructed from a wide array of sources such as: structured data files, tables in Hive, external databases, or existing RDDs. The DataFrame API is available in Scala, Java, Python, and R. In Scala and Java, a DataFrame is represented by a Dataset of Rows. In the Scala API, DataFrame is simply a type alias of Dataset[Row]. While, in Java API, users need to use Dataset to represent a DataFrame.
Throughout this document, we will often refer to Scala/Java Datasets of Rows as DataFrames.
译
Datasets and DataFrames
Datasets是数据的分布式集合。Dataset是Spark 1.6中添加的一个新接口,它提供了rdd(强类型、使用强大lambda函数的能力)的优点和Spark SQL优化的执行引擎的优点。可以从JVM对象构造数据集,然后使用函数转换(map、flatMap、filter等)进行操作。数据集API在Scala和Java中可用。Python不支持Dataset API。但由于Python的动态特性,Dataset API的许多优点已经可用(即,您可以按名称自然地访问行的字段row.columnName)。R的情况类似。
DataFrame是组织成命名列的数据集。它在概念上等同于关系数据库中的表或R/Python中的数据集,但在幕后有更丰富的优化。数据帧可以从广泛的源数组中构造,例如:结构化数据文件、配置单元中的表、外部数据库或现有的RDD。DataFrame API在Scala、Java、Python和R中可用。在Scala和Java中,DataFrame由行的数据集表示。在Scala API中,DataFrame只是Dataset[行]的类型别名。而在Java API中,用户需要使用Dataset来表示数据帧。
在本文中,我们经常将行的Scala/Java数据集称为数据帧。
一个用于处理结构化数据的Spark组件,强调的是“结构化数据”,而非“SQL”
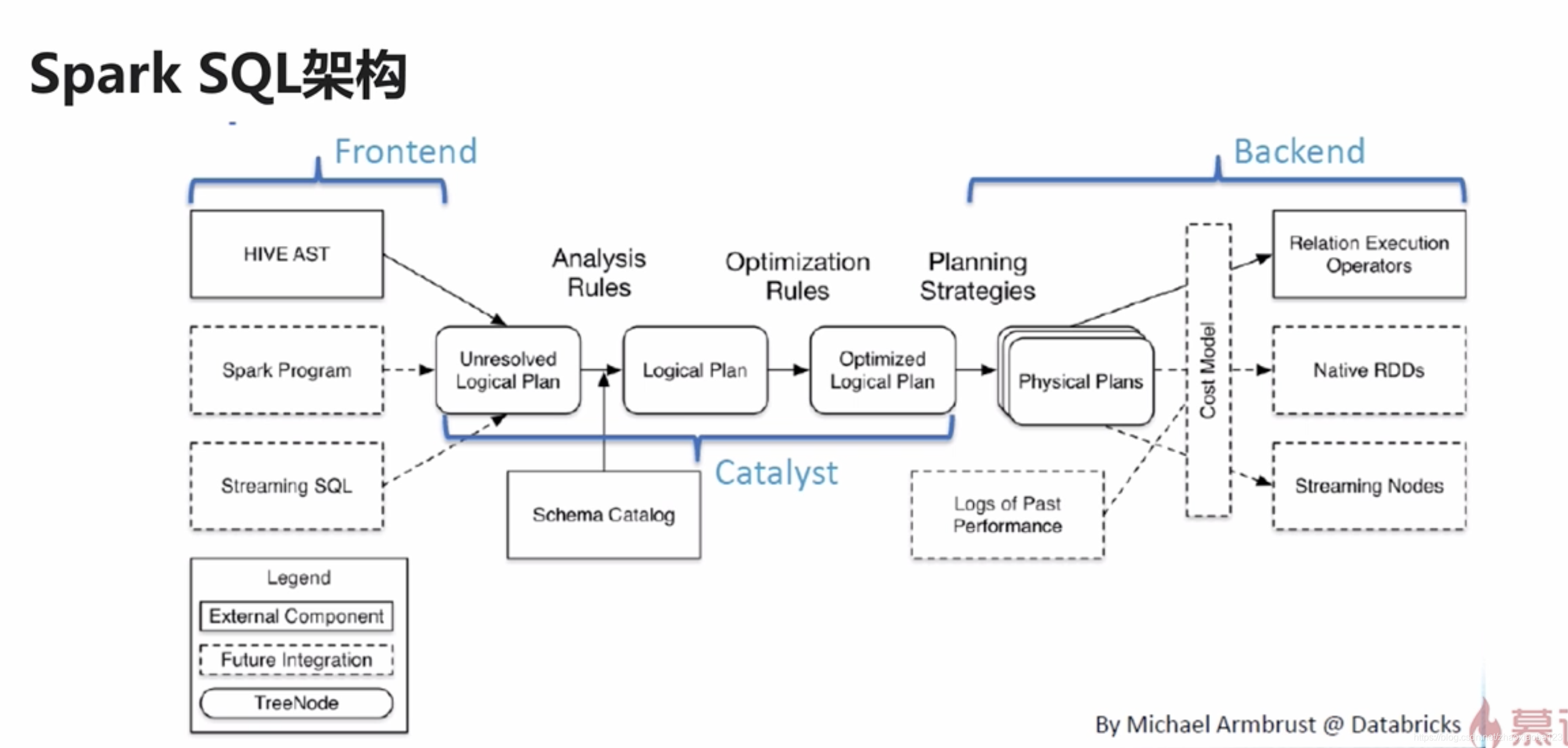
Spark中所有功能的入口点是SparkSession类。要创建基本SparkSession,只需使用SparkSession.builder:
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName(“代码文件名”) .config(“spark.some.config.option”, “some-value”) .getOrCreate()
#spark是一个现有的SparkSession
df = spark.read.json(“file:///Users/zhaoxinbo/Documents/python-xiangmu/Spark-huanjing/spark-2.3.0-bin-2.6.0-cdh5.7.0/examples/src/main/resources/people.json”)
df.show()#向stdo显示DataFrame的内容
df.printSchema()#打印出树形结构
df.select(“name”).show()#指定列名显示出来
df.select(df.name, (df.age + 10).alias(‘age’)).show()#按字段名取,并且计算和添加别名,显示出来
df.filter(df.age > 21).show() #按字段过滤显示出来
df.groupBy(df.age).count().show()#分组统计显示出来
#以编程方式运行SQL查询 . 临时表
df.createOrReplaceTempView(“people”) #首先先注册一张临时表
sqlDF = spark.sql(“SELECT * FROM people”)#然后以sql语句的方式查询
sqlDF.show()#显示出来
全局临时视图
Spark SQL中的临时视图是有会话范围的,如果创建它的会话终止,临时视图将消失。如果希望有一个在所有会话之间共享的临时视图,并在Spark应用程序终止之前保持活动状态,则可以创建一个全局临时视图。全局临时视图绑定到系统保留的数据库Global_temp,我们必须使用限定名来引用它,例如从Global_temp.view1中选择*。
df.createGlobalTempView(“people”)
spark.sql(“SELECT * FROM global_temp.people”).show() #全局临时视图绑定到系统保留的数据库’Global-temp
spark.newSession().sql(“SELECT * FROM global_temp.people”).show()#跨会话的临时视图
spark.stop()#停止spark
RDD和DataFrame的互操作
与RDD互操作
Spark SQL支持两种将现有RDD转换为数据集的方法。 第一种方法使用反射来推断包含特定对象类型的RDD的架构。 这种基于反射的方法可以使代码更简洁,并且当您在编写Spark应用程序时已经了解架构时,可以很好地工作。
创建数据集的第二种方法是通过编程界面,该界面允许您构造模式,然后将其应用于现有的RDD。 尽管此方法较为冗长,但可以让您在运行时才知道列及其类型的情况下构造数据集。
第一种:使用反射推断架构
Spark SQL可以将Row对象的RDD转换为DataFrame,从而推断数据类型。 通过将键/值对的列表作为kwargs传递给Row类来构造行。 此列表的键定义表的列名,并且通过对整个数据集进行采样来推断类型,类似于对JSON文件执行的推断。
def schema_inference_example(spark):
sc = spark.sparkContext
# Load a text file and convert each line to a Row. 加载文本文件并将每一行转换为一行
lines = sc.textFile("file:///Users/zhaoxinbo/Documents/python-xiangmu/Spark-huanjing/spark-2.3.0-bin-2.6.0-cdh5.7.0/examples/src/main/resources/people.txt")
parts = lines.map(lambda l: l.split(",")) #分割
people = parts.map(lambda p: Row(name=p[0], age=int(p[1]))) #取字段
# Infer the schema, and register the DataFrame as a table. 推断模式,然后将DataFrame注册为表。
schemaPeople = spark.createDataFrame(people)
schemaPeople.createOrReplaceTempView("people")
# SQL can be run over DataFrames that have been registered as a table. SQL可以在已注册为表的DataFrame上运行。
teenagers = spark.sql("SELECT name FROM people WHERE age >= 13 AND age <= 19")
# The results of SQL queries are Dataframe objects. SQL查询的结果是Dataframe对象。
# rdd returns the content as an :class:`pyspark.RDD` of :class:`Row`. rdd以以下内容返回内容:类:`pyspark.RDD` 类:Row
teenNames = teenagers.rdd.map(lambda p: "Name: " + p.name).collect()
for name in teenNames:
print(name)
# Name: Justin
第二种:以编程方式指定架构
如果无法提前定义kwarg的字典(例如,记录的结构编码为字符串,或者将解析文本数据集,并且为不同的用户对字段进行不同的投影),则可以使用以下方式以编程方式创建DataFrame: 三个步骤。
从原始RDD创建元组或列表的RDD;
在第1步中创建的RDD中,创建一个由StructType表示的模式来匹配元组或列表的结构。
通过SparkSession提供的createDataFrame方法将架构应用于RDD。
def programmatic_schema_example(spark):
sc = spark.sparkContext
# Load a text file and convert each line to a Row. 加载文本文件并将每一行转换为一行。
lines = sc.textFile("file:///Users/zhaoxinbo/Documents/python-xiangmu/Spark-huanjing/spark-2.3.0-bin-2.6.0-cdh5.7.0/examples/src/main/resources/people.txt")
parts = lines.map(lambda l: l.split(","))
# Each line is converted to a tuple. 每行都转换为一个元组。
people = parts.map(lambda p: (p[0], p[1].strip()))
# The schema is encoded in a string. 模式被编码为字符串。
schemaString = "name age"
fields = [StructField(field_name, StringType(), True) for field_name in schemaString.split()]
schema = StructType(fields)
# Apply the schema to the RDD. 将架构应用于RDD。
schemaPeople = spark.createDataFrame(people, schema)
# Creates a temporary view using the DataFrame 使用DataFrame创建一个临时视图
schemaPeople.createOrReplaceTempView("people")
# SQL can be run over DataFrames that have been registered as a table. SQL可以在已注册为表的DataFrame上运行。
results = spark.sql("SELECT name FROM people")
results.show()
print(results.rdd.collect()) #DataFrame 转 RDD
1、数据源加载 Generic Load/Save Functions
Data Sources
Spark SQL supports operating on a variety of data sources through the DataFrame interface. A DataFrame can be operated on using relational transformations and can also be used to create a temporary view. Registering a DataFrame as a temporary view allows you to run SQL queries over its data. This section describes the general methods for loading and saving data using the Spark Data Sources and then goes into specific options that are available for the built-in data sources.
译:
数据源
Spark SQL支持通过DataFrame接口对各种数据源进行操作。 DataFrame可以使用关系转换进行操作,也可以用于创建临时视图。 将DataFrame注册为临时视图使您可以对其数据运行SQL查询。 本节介绍了使用Spark数据源加载和保存数据的一般方法,然后介绍了可用于内置数据源的特定选项。
Generic Load/Save Functions 通用加载/保存功能
In the simplest form, the default data source (parquet unless otherwise configured by spark.sql.sources.default) will be used for all operations
译:
以最简单的形式,所有操作都将使用默认数据源(镶木地板,除非由spark.sql.sources.default另行配置)。
例子:
df = spark.read.load(“examples/src/main/resources/users.parquet”)#加载本地数据源
df.select(“name”, “favorite_color”).write.save(“namesAndFavColors.parquet”)#查询出后保存
Manually Specifying Options
You can also manually specify the data source that will be used along with any extra options that you would like to pass to the data source. Data sources are specified by their fully qualified name (i.e., org.apache.spark.sql.parquet), but for built-in sources you can also use their short names (json, parquet, jdbc, orc, libsvm, csv, text). DataFrames loaded from any data source type can be converted into other types using this syntax.
To load a JSON file you can use:
手动指定选项
您还可以手动指定将要使用的数据源以及要传递给数据源的任何其他选项。 数据源由它们的完全限定名称(即org.apache.spark.sql.parquet)指定,但是对于内置源,您还可以使用其短名称(json,parquet,jdbc,orc,libsvm,csv,文本 )。 从任何数据源类型加载的DataFrame都可以使用此语法转换为其他类型。
要加载JSON文件,您可以使用:
#加载本地数据源,手动指定选项
df = spark.read.load("/Users/zhaoxinbo/Documents/python-xiangmu/Spark-huanjing/spark-2.3.0-bin-2.6.0-cdh5.7.0/examples/src/main/resources/people.json", format=“json”)
df.select(“name”, “age”).write.save("/Users/zhaoxinbo/Documents/python-xiangmu/Spark-project/88/data-storage/namesAndAgesjosn.parquet", format=“parquet”)
To load a CSV file you can use: 要加载CSV文件,您可以使用:
#要加载CSV文件,您可以使用
df = spark.read.load("/Users/zhaoxinbo/Documents/python-xiangmu/Spark-huanjing/spark-2.3.0-bin-2.6.0-cdh5.7.0/examples/src/main/resources/people.csv", format=“csv”, sep=";", inferSchema=“true”, header=“true”)
df.select(df.name).write.save("/Users/zhaoxinbo/Documents/python-xiangmu/Spark-project/88/data-storage/namepeople.json", format=“json”)
The extra options are also used during write operation. For example, you can control bloom filters and dictionary encodings for ORC data sources. The following ORC example will create bloom filter on favorite_color and use dictionary encoding for name and favorite_color. For Parquet, there exists parquet.enable.dictionary, too. To find more detailed information about the extra ORC/Parquet options, visit the official Apache ORC/Parquet websites.
在写操作期间还会使用额外的选项。 例如,您可以控制ORC数据源的Bloom过滤器和字典编码。 以下ORC示例将在favourite_color上创建bloom过滤器,并对名称和favourite_color使用字典编码。 对于Parquet,也存在parquet.enable.dictionary。 要查找有关其他ORC / Parquet选项的更多详细信息,请访问Apache ORC / Parquet官方网站。
#加入过滤等条件
df = spark.read.orc(“examples/src/main/resources/users.orc”)
(df.write.format(“orc”).option(“orc.bloom.filter.columns”, “favorite_color”).option(“orc.dictionary.key.threshold”, “1.0”).save(“users_with_options.orc”))
Run SQL on files directly
Instead of using read API to load a file into DataFrame and query it, you can also query that file directly with SQL.
直接在文件上运行SQL
除了使用读取API将文件加载到DataFrame中并进行查询之外,您还可以直接使用SQL查询该文件。
#直接读取文件
df = spark.sql(“SELECT * FROM parquet./Users/zhaoxinbo/Documents/python-xiangmu/Spark-huanjing/spark-2.3.0-bin-2.6.0-cdh5.7.0/examples/src/main/resources/users.parquet”)
df.show()
Saving to Persistent Tables 保存到永久表
DataFrames can also be saved as persistent tables into Hive metastore using the saveAsTable command. Notice that an existing Hive deployment is not necessary to use this feature. Spark will create a default local Hive metastore (using Derby) for you. Unlike the createOrReplaceTempView command, saveAsTable will materialize the contents of the DataFrame and create a pointer to the data in the Hive metastore. Persistent tables will still exist even after your Spark program has restarted, as long as you maintain your connection to the same metastore. A DataFrame for a persistent table can be created by calling the table method on a SparkSession with the name of the table.
For file-based data source, e.g. text, parquet, json, etc. you can specify a custom table path via the path option, e.g. df.write.option(“path”, “/some/path”).saveAsTable(“t”). When the table is dropped, the custom table path will not be removed and the table data is still there. If no custom table path is specified, Spark will write data to a default table path under the warehouse directory. When the table is dropped, the default table path will be removed too.
Starting from Spark 2.1, persistent datasource tables have per-partition metadata stored in the Hive metastore. This brings several benefits:
Since the metastore can return only necessary partitions for a query, discovering all the partitions on the first query to the table is no longer needed.
Hive DDLs such as ALTER TABLE PARTITION … SET LOCATION are now available for tables created with the Datasource API.
Note that partition information is not gathered by default when creating external datasource tables (those with a path option). To sync the partition information in the metastore, you can invoke MSCK REPAIR TABLE.
也可以使用saveAsTable命令将DataFrames作为持久性表保存到Hive Metastore中。请注意,使用此功能不需要现有的Hive部署。 Spark将为您创建一个默认的本地Hive Metastore(使用Derby)。与createOrReplaceTempView命令不同,saveAsTable将具体化DataFrame的内容并在Hive元存储中创建一个指向数据的指针。即使您重新启动Spark程序,持久表仍将存在,只要您保持与同一metastore的连接即可。可以通过使用表名称在SparkSession上调用table方法来创建持久表的DataFrame。
对于基于文件的数据源,例如文本,镶木地板,json等),您可以通过path选项指定自定义表格路径,例如df.write.option(“ path”,“ /some/path").saveAsTable("t”)。删除表后,自定义表路径将不会删除,并且表数据仍然存在。如果未指定自定义表路径,Spark会将数据写入仓库目录下的默认表路径。删除表时,默认表路径也将被删除。
从Spark 2.1开始,持久数据源表在Hive元存储中存储了按分区的元数据。这带来了几个好处:
由于元存储只能返回查询的必要分区,因此不再需要在第一个查询中将所有分区发现到表中。
Hive DDL,例如ALTER TABLE PARTITION … SET LOCATION现在可用于使用Datasource API创建的表。
请注意,在创建外部数据源表(带有路径选项的表)时,默认情况下不会收集分区信息。若要同步元存储中的分区信息,可以调用MSCK REPAIR TABLE。
Bucketing, Sorting and Partitioning
分组,排序和分区
For file-based data source, it is also possible to bucket and sort or partition the output. Bucketing and sorting are applicable only to persistent tables:
对于基于文件的数据源,也可以对输出进行存储和分类或分区。 存储桶和排序仅适用于持久表:
df = spark.read.load("/Users/zhaoxinbo/Documents/python-xiangmu/Spark-huanjing/spark-2.3.0-bin-2.6.0-cdh5.7.0/examples/src/main/resources/people.json", format=“json”)
df.write.bucketBy(42, “name”).sortBy(“age”).saveAsTable(“people_bucketed”)
while partitioning can be used with both save and saveAsTable when using the Dataset APIs.
使用Dataset API时,分区可以与save和saveAsTable一起使用。
df = spark.read.load("/Users/zhaoxinbo/Documents/python-xiangmu/Spark-huanjing/spark-2.3.0-bin-2.6.0-cdh5.7.0/examples/src/main/resources/people.json", format=“json”)
df.write.partitionBy(“age”).format(“json”).save("/Users/zhaoxinbo/Documents/python-xiangmu/Spark-project/88/data-storage/namesPartByColorpeople.json")
It is possible to use both partitioning and bucketing for a single table:
可以对单个表使用分区和存储桶:
df = spark.read.load("/Users/zhaoxinbo/Documents/python-xiangmu/Spark-huanjing/spark-2.3.0-bin-2.6.0-cdh5.7.0/examples/src/main/resources/people.json", format=“json”)
df = spark.read.parquet(“examples/src/main/resources/users.parquet”)
(df.write.partitionBy(“favorite_color”).bucketBy(42, “name”).saveAsTable(“people_partitioned_bucketed”))
Parquet Files
Parquet is a columnar format that is supported by many other data processing systems. Spark SQL provides support for both reading and writing Parquet files that automatically preserves the schema of the original data. When writing Parquet files, all columns are automatically converted to be nullable for compatibility reasons.
Parquet是许多其他数据处理系统支持的列格式。 Spark SQL提供对读写Parquet文件的支持,该文件会自动保留原始数据的架构。 编写Parquet文件时,出于兼容性原因,所有列都将自动转换为可为空。
Loading Data Programmatically 以编程方式加载数据
Using the data from the above example: 使用上面示例中的数据
peopleDF = spark.read.json(“examples/src/main/resources/people.json”)
DataFrames can be saved as Parquet files, maintaining the schema information.
#可以将DataFrame保存为Parquet文件,以保持架构信息。
peopleDF.write.parquet(“people.parquet”)
Read in the Parquet file created above.
Parquet files are self-describing so the schema is preserved.
The result of loading a parquet file is also a DataFrame.
#读取上面创建的Parquet文件。
#Parquet文件是自描述的,因此保留了架构。
#加载实木复合地板文件的结果也是一个DataFrame。
parquetFile = spark.read.parquet(“people.parquet”)
Parquet files can also be used to create a temporary view and then used in SQL statements.
#Parquet文件也可以用于创建临时视图,然后在SQL语句中使用。
parquetFile.createOrReplaceTempView(“parquetFile”)
teenagers = spark.sql(“SELECT name FROM parquetFile WHERE age >= 13 AND age <= 19”)
teenagers.show()
±-----+
| name|
±-----+
|Justin|
±-----+
Partition Discovery
Table partitioning is a common optimization approach used in systems like Hive. In a partitioned table, data are usually stored in different directories, with partitioning column values encoded in the path of each partition directory. All built-in file sources (including Text/CSV/JSON/ORC/Parquet) are able to discover and infer partitioning information automatically. For example, we can store all our previously used population data into a partitioned table using the following directory structure, with two extra columns, gender and country as partitioning columns:
表分区是Hive等系统中常用的优化方法。 在分区表中,数据通常存储在不同的目录中,分区列值编码在每个分区目录的路径中。 所有内置文件源(包括Text / CSV / JSON / ORC / Parquet)都可以自动发现和推断分区信息。 例如,我们可以使用以下目录结构将以前使用的所有人口数据存储到一个分区表中,并带有两个额外的列,即性别和国家作为分区列:

By passing path/to/table to either SparkSession.read.parquet or SparkSession.read.load, Spark SQL will automatically extract the partitioning information from the paths. Now the schema of the returned DataFrame becomes:
通过将path / to / table传递到SparkSession.read.parquet或SparkSession.read.load,Spark SQL将自动从路径中提取分区信息。 现在,返回的DataFrame的架构变为:

Notice that the data types of the partitioning columns are automatically inferred. Currently, numeric data types, date, timestamp and string type are supported. Sometimes users may not want to automatically infer the data types of the partitioning columns. For these use cases, the automatic type inference can be configured by spark.sql.sources.partitionColumnTypeInference.enabled, which is default to true. When type inference is disabled, string type will be used for the partitioning columns.
Starting from Spark 1.6.0, partition discovery only finds partitions under the given paths by default. For the above example, if users pass path/to/table/gender=male to either SparkSession.read.parquet or SparkSession.read.load, gender will not be considered as a partitioning column. If users need to specify the base path that partition discovery should start with, they can set basePath in the data source options. For example, when path/to/table/gender=male is the path of the data and users set basePath to path/to/table/, gender will be a partitioning column.
请注意,分区列的数据类型是自动推断的。当前,支持数字数据类型,日期,时间戳和字符串类型。有时用户可能不希望自动推断分区列的数据类型。对于这些用例,可以通过spark.sql.sources.partitionColumnTypeInference.enabled配置自动类型推断,默认情况下为true。禁用类型推断时,字符串类型将用于分区列。
从Spark 1.6.0开始,默认情况下,分区发现仅在给定路径下查找分区。对于上面的示例,如果用户将path / to / table / gender = male传递给SparkSession.read.parquet或SparkSession.read.load,则性别不会被视为分区列。如果用户需要指定分区发现应开始的基本路径,则可以在数据源选项中设置basePath。例如,当path / to / table / gender = male是数据的路径,并且用户将basePath设置为path / to / table / gender时,性别将是一个分区列。
Schema Merging
Like Protocol Buffer, Avro, and Thrift, Parquet also supports schema evolution. Users can start with a simple schema, and gradually add more columns to the schema as needed. In this way, users may end up with multiple Parquet files with different but mutually compatible schemas. The Parquet data source is now able to automatically detect this case and merge schemas of all these files.
Since schema merging is a relatively expensive operation, and is not a necessity in most cases, we turned it off by default starting from 1.5.0. You may enable it by
setting data source option mergeSchema to true when reading Parquet files (as shown in the examples below), or
setting the global SQL option spark.sql.parquet.mergeSchema to true.
模式合并
与协议缓冲区,Avro和Thrift一样,Parquet也支持架构演变。 用户可以从一个简单的架构开始,然后根据需要逐渐向架构中添加更多列。 这样,用户可能最终得到具有不同但相互兼容的架构的多个Parquet文件。 现在,Parquet数据源能够自动检测到这种情况并合并所有这些文件的模式。
由于架构合并是一项相对昂贵的操作,并且在大多数情况下不是必需的,因此默认情况下,我们从1.5.0开始将其关闭。 您可以通过以下方式启用它
读取Parquet文件时,将数据源选项mergeSchema设置为true(如下例所示),或者
将全局SQL选项spark.sql.parquet.mergeSchema设置为true。
from pyspark.sql import Row
spark is from the previous example. spark来自上一个示例。
Create a simple DataFrame, stored into a partition directory . 创建一个简单的DataFrame,存储到分区目录中
sc = spark.sparkContext
squaresDF = spark.createDataFrame(sc.parallelize(range(1, 6))
.map(lambda i: Row(single=i, double=i ** 2)))
squaresDF.write.parquet(“data/test_table/key=1”)
Create another DataFrame in a new partition directory, 在新的分区目录中创建另一个DataFrame,
adding a new column and dropping an existing column 添加新列并删除现有列
cubesDF = spark.createDataFrame(sc.parallelize(range(6, 11))
.map(lambda i: Row(single=i, triple=i ** 3)))
cubesDF.write.parquet(“data/test_table/key=2”)
Read the partitioned table 读取分区表
mergedDF = spark.read.option(“mergeSchema”, “true”).parquet(“data/test_table”)
mergedDF.printSchema()
The final schema consists of all 3 columns in the Parquet files together .
最终模式由Parquet文件中的所有3列组成
with the partitioning column appeared in the partition directory paths.
带有分区列的分区出现在分区目录路径中。
root
|-- double: long (nullable = true)
|-- single: long (nullable = true)
|-- triple: long (nullable = true)
|-- key: integer (nullable = true)
Hive metastore Parquet table conversion
When reading from and writing to Hive metastore Parquet tables, Spark SQL will try to use its own Parquet support instead of Hive SerDe for better performance. This behavior is controlled by the spark.sql.hive.convertMetastoreParquet configuration, and is turned on by default.
Hive Metastore Parquet表转换
在读取和写入Hive metastore Parquet表时,Spark SQL将尝试使用其自己的Parquet支持而不是Hive SerDe以获得更好的性能。 此行为由spark.sql.hive.convertMetastoreParquet配置控制,并且默认情况下处于启用状态。
Hive/Parquet Schema Reconciliation
There are two key differences between Hive and Parquet from the perspective of table schema processing.
Hive is case insensitive, while Parquet is not
Hive considers all columns nullable, while nullability in Parquet is significant
Due to this reason, we must reconcile Hive metastore schema with Parquet schema when converting a Hive metastore Parquet table to a Spark SQL Parquet table. The reconciliation rules are:
Fields that have the same name in both schema must have the same data type regardless of nullability. The reconciled field should have the data type of the Parquet side, so that nullability is respected.
The reconciled schema contains exactly those fields defined in Hive metastore schema.
Any fields that only appear in the Parquet schema are dropped in the reconciled schema.
Any fields that only appear in the Hive metastore schema are added as nullable field in the reconciled schema.
蜂巢/实木复合地板架构协调
从表模式处理的角度来看,Hive和Parquet之间有两个关键区别。
Hive不区分大小写,而Parquet则不区分大小写
Hive认为所有列都可为空,而Parquet中的可为空性很重要
由于这个原因,在将Hive Metastore Parquet表转换为Spark SQL Parquet表时,我们必须使Hive Metastore模式与Parquet模式协调一致。 对帐规则为:
在两个模式中具有相同名称的字段必须具有相同的数据类型,而不考虑可为空性。 协调字段应具有Parquet端的数据类型,以便遵守可空性。
协调的架构完全包含在Hive Metastore架构中定义的那些字段。
仅出现在Parquet模式中的所有字段都将被放入对帐模式中。
仅在Hive Metastore模式中出现的所有字段都将添加为已对帐模式中的可为空字段。
Metadata Refreshing
Spark SQL caches Parquet metadata for better performance. When Hive metastore Parquet table conversion is enabled, metadata of those converted tables are also cached. If these tables are updated by Hive or other external tools, you need to refresh them manually to ensure consistent metadata.
元数据刷新
Spark SQL缓存Parquet元数据以获得更好的性能。 启用Hive metastore Parquet表转换后,这些转换表的元数据也会被缓存。 如果这些表是通过Hive或其他外部工具更新的,则需要手动刷新它们以确保元数据一致。
spark is an existing SparkSession
spark.catalog.refreshTable(“my_table”)
spark.sql.parquet.binaryAsString
false
Some other Parquet-producing systems, in particular Impala, Hive, and older versions of Spark SQL, do not differentiate between binary data and strings when writing out the Parquet schema. This flag tells Spark SQL to interpret binary data as a string to provide compatibility with these systems.
spark.sql.parquet.int96AsTimestamp
true
Some Parquet-producing systems, in particular Impala and Hive, store Timestamp into INT96. This flag tells Spark SQL to interpret INT96 data as a timestamp to provide compatibility with these systems.
spark.sql.parquet.compression.codec
snappy
Sets the compression codec used when writing Parquet files. If either compression or parquet.compression is specified in the table-specific options/properties, the precedence would be compression, parquet.compression, spark.sql.parquet.compression.codec. Acceptable values include: none, uncompressed, snappy, gzip, lzo, brotli, lz4, zstd. Note that zstd requires ZStandardCodec to be installed before Hadoop 2.9.0, brotli requires BrotliCodec to be installed.
spark.sql.parquet.filterPushdown
true
Enables Parquet filter push-down optimization when set to true.
spark.sql.hive.convertMetastoreParquet true When set to false, Spark SQL will use the Hive SerDe for parquet tables instead of the built in support.
spark.sql.parquet.mergeSchema
false
When true, the Parquet data source merges schemas collected from all data files, otherwise the schema is picked from the summary file or a random data file if no summary file is available.
spark.sql.parquet.writeLegacyFormat
false
If true, data will be written in a way of Spark 1.4 and earlier. For example, decimal values will be written in Apache Parquet’s fixed-length byte array format, which other systems such as Apache Hive and Apache Impala use. If false, the newer format in Parquet will be used. For example, decimals will be written in int-based format. If Parquet output is intended for use with systems that do not support this newer format, set to true.
spark.sql.parquet.binaryAsString
假
编写Parquet模式时,其他一些Parquet产生系统,尤其是Impala,Hive和旧版本的Spark SQL,不会区分二进制数据和字符串。该标志告诉Spark SQL将二进制数据解释为字符串,以提供与这些系统的兼容性。
spark.sql.parquet.int96AsTimestamp
真正
一些镶木地板生产系统,尤其是Impala和Hive,将时间戳存储到INT96中。此标志告诉Spark SQL将INT96数据解释为时间戳,以提供与这些系统的兼容性。
spark.sql.parquet.compression.codec
活泼的
设置编写Parquet文件时使用的压缩编解码器。如果在特定于表的选项/属性中指定了“压缩”或“ parquet.compression”,则优先级为“压缩”,“ parquet.compression”,“ spark.sql.parquet.compression.codec”。可接受的值包括:none,未压缩,snappy,gzip,lzo,brotli,lz4,zstd。请注意,zstd要求在Hadoop 2.9.0之前先安装’ZStandardCodec’,‘brotli’则需要安装’BrotliCodec’。
spark.sql.parquet.filterPushdown
真正
设置为true时启用Parquet过滤器下推优化。
spark.sql.hive.convertMetastoreParquet true设置为false时,Spark SQL将使用Hive SerDe用于镶木表,而不是内置支持。
spark.sql.parquet.mergeSchema
假
如果为true,则Parquet数据源将合并从所有数据文件收集的架构,否则从摘要文件或随机数据文件(如果没有摘要文件可用)中选取该架构。
spark.sql.parquet.writeLegacyFormat
假
如果为true,将以Spark 1.4及更早版本的方式写入数据。例如,十进制值将以Apache Parquet的固定长度字节数组格式编写,其他系统(例如Apache Hive和Apache Impala)将使用该格式。如果为false,将使用Parquet中较新的格式。例如,小数将以基于int的格式编写。如果Parquet输出打算用于不支持这种较新格式的系统,请设置为true。
2、ORC Files
Since Spark 2.3, Spark supports a vectorized ORC reader with a new ORC file format for ORC files. To do that, the following configurations are newly added. The vectorized reader is used for the native ORC tables (e.g., the ones created using the clause USING ORC) when spark.sql.orc.impl is set to native and spark.sql.orc.enableVectorizedReader is set to true. For the Hive ORC serde tables (e.g., the ones created using the clause USING HIVE OPTIONS (fileFormat ‘ORC’)), the vectorized reader is used when spark.sql.hive.convertMetastoreOrc is also set to true.
从Spark 2.3开始,Spark支持矢量化ORC读取器,该读取器具有针对ORC文件的新ORC文件格式。 为此,新添加了以下配置。 当spark.sql.orc.impl设置为native并且spark.sql.orc.enableVectorizedReader设置为true时,矢量化读取器用于本机ORC表(例如,使用子句USING ORC创建的表)。 对于Hive ORC Serde表(例如,使用子句USING HIVE OPTIONS(fileFormat’ORC’)创建的表),当spark.sql.hive.convertMetastoreOrc也设置为true时,将使用矢量化读取器。
spark.sql.orc.impl
native
The name of ORC implementation. It can be one of native and hive. native means the native ORC support that is built on Apache ORC 1.4. hive means the ORC library in Hive 1.2.1.
spark.sql.orc.enableVectorizedReader
true
Enables vectorized orc decoding in native implementation. If false, a new non-vectorized ORC reader is used in native implementation. For hive implementation, this is ignored.
spark.sql.orc.impl
本机
ORC实现的名称。 它可以是本地的,也可以是蜂巢的。 native表示基于Apache ORC 1.4构建的本机ORC支持。 “ hive”是指Hive 1.2.1中的ORC库。
spark.sql.orc.enableVectorizedReader
真正
在本机实现中启用向量化orc解码。 如果为false,则在本机实现中使用新的非矢量化ORC读取器。 对于蜂巢的实现,这将被忽略。
3、JSON Files
Spark SQL can automatically infer the schema of a JSON dataset and load it as a DataFrame. This conversion can be done using SparkSession.read.json on a JSON file.
Note that the file that is offered as a json file is not a typical JSON file. Each line must contain a separate, self-contained valid JSON object. For more information, please see JSON Lines text format, also called newline-delimited JSON.
For a regular multi-line JSON file, set the multiLine parameter to True.
Spark SQL可以自动推断JSON数据集的架构并将其作为DataFrame加载。 可以使用JSON文件上的SparkSession.read.json完成此转换。
请注意,以json文件形式提供的文件不是典型的JSON文件。 每行必须包含一个单独的,自包含的有效JSON对象。 有关更多信息,请参见JSON行文本格式,也称为换行符分隔的JSON。
对于常规的多行JSON文件,请将multiLine参数设置为True。
spark is from the previous example.
sc = spark.sparkContext
A JSON dataset is pointed to by path.
The path can be either a single text file or a directory storing text files
path = “examples/src/main/resources/people.json”
peopleDF = spark.read.json(path)
The inferred schema can be visualized using the printSchema() method
peopleDF.printSchema()
root
|-- age: long (nullable = true)
|-- name: string (nullable = true)
Creates a temporary view using the DataFrame
peopleDF.createOrReplaceTempView(“people”)
SQL statements can be run by using the sql methods provided by spark
teenagerNamesDF = spark.sql(“SELECT name FROM people WHERE age BETWEEN 13 AND 19”)
teenagerNamesDF.show()
±-----+
| name|
±-----+
|Justin|
±-----+
Alternatively, a DataFrame can be created for a JSON dataset represented by
an RDD[String] storing one JSON object per string
jsonStrings = [’{“name”:“Yin”,“address”:{“city”:“Columbus”,“state”:“Ohio”}}’]
otherPeopleRDD = sc.parallelize(jsonStrings)
otherPeople = spark.read.json(otherPeopleRDD)
otherPeople.show()
±--------------±—+
| address|name|
±--------------±—+
|[Columbus,Ohio]| Yin|
±--------------±—+
4、Hive Tables
Spark SQL also supports reading and writing data stored in Apache Hive. However, since Hive has a large number of dependencies, these dependencies are not included in the default Spark distribution. If Hive dependencies can be found on the classpath, Spark will load them automatically. Note that these Hive dependencies must also be present on all of the worker nodes, as they will need access to the Hive serialization and deserialization libraries (SerDes) in order to access data stored in Hive.
Configuration of Hive is done by placing your hive-site.xml, core-site.xml (for security configuration), and hdfs-site.xml (for HDFS configuration) file in conf/.
When working with Hive, one must instantiate SparkSession with Hive support, including connectivity to a persistent Hive metastore, support for Hive serdes, and Hive user-defined functions. Users who do not have an existing Hive deployment can still enable Hive support. When not configured by the hive-site.xml, the context automatically creates metastore_db in the current directory and creates a directory configured by spark.sql.warehouse.dir, which defaults to the directory spark-warehouse in the current directory that the Spark application is started. Note that the hive.metastore.warehouse.dir property in hive-site.xml is deprecated since Spark 2.0.0. Instead, use spark.sql.warehouse.dir to specify the default location of database in warehouse. You may need to grant write privilege to the user who starts the Spark application.
Spark SQL还支持读写存储在Apache Hive中的数据。但是,由于Hive具有大量依赖关系,因此默认的Spark分发中不包含这些依赖关系。如果可以在类路径上找到Hive依赖项,Spark将自动加载它们。请注意,这些Hive依赖项也必须存在于所有工作节点上,因为它们将需要访问Hive序列化和反序列化库(SerDes)才能访问存储在Hive中的数据。
通过将您的hive-site.xml,core-site.xml(用于安全配置)和hdfs-site.xml(用于HDFS配置)文件放置在conf /中,可以完成Hive的配置。
使用Hive时,必须使用Hive支持实例化SparkSession,包括与持久性Hive元存储库的连接,对Hive Serdes的支持以及Hive用户定义的功能。没有现有Hive部署的用户仍可以启用Hive支持。如果未由hive-site.xml配置,则上下文会自动在当前目录中创建metastore_db并创建一个由spark.sql.warehouse.dir配置的目录,该目录默认为Spark应用程序在当前目录中的目录spark-househouse开始。请注意,自Spark 2.0.0起,hive-site.xml中的hive.metastore.warehouse.dir属性已被弃用。而是使用spark.sql.warehouse.dir指定数据库在仓库中的默认位置。您可能需要向启动Spark应用程序的用户授予写权限。
from os.path import expanduser, join, abspath
from pyspark.sql import SparkSession
from pyspark.sql import Row
warehouse_location points to the default location for managed databases and tables
warehouse_location = abspath(‘spark-warehouse’)
spark = SparkSession
.builder
.appName(“Python Spark SQL Hive integration example”)
.config(“spark.sql.warehouse.dir”, warehouse_location)
.enableHiveSupport()
.getOrCreate()
spark is an existing SparkSession
spark.sql(“CREATE TABLE IF NOT EXISTS src (key INT, value STRING) USING hive”)
spark.sql(“LOAD DATA LOCAL INPATH ‘examples/src/main/resources/kv1.txt’ INTO TABLE src”)
Queries are expressed in HiveQL
spark.sql(“SELECT * FROM src”).show()
±–±------+
|key| value|
±–±------+
|238|val_238|
| 86| val_86|
|311|val_311|
…
Aggregation queries are also supported.
spark.sql(“SELECT COUNT(*) FROM src”).show()
±-------+
|count(1)|
±-------+
| 500 |
±-------+
The results of SQL queries are themselves DataFrames and support all normal functions.
sqlDF = spark.sql(“SELECT key, value FROM src WHERE key < 10 ORDER BY key”)
The items in DataFrames are of type Row, which allows you to access each column by ordinal.
stringsDS = sqlDF.rdd.map(lambda row: “Key: %d, Value: %s” % (row.key, row.value))
for record in stringsDS.collect():
print(record)
Key: 0, Value: val_0
Key: 0, Value: val_0
Key: 0, Value: val_0
…
You can also use DataFrames to create temporary views within a SparkSession.
Record = Row(“key”, “value”)
recordsDF = spark.createDataFrame([Record(i, “val_” + str(i)) for i in range(1, 101)])
recordsDF.createOrReplaceTempView(“records”)
Queries can then join DataFrame data with data stored in Hive.
spark.sql(“SELECT * FROM records r JOIN src s ON r.key = s.key”).show()
±–±-----±–±-----+
|key| value|key| value|
±–±-----±–±-----+
| 2| val_2| 2| val_2|
| 4| val_4| 4| val_4|
| 5| val_5| 5| val_5|
…
Specifying storage format for Hive tables
When you create a Hive table, you need to define how this table should read/write data from/to file system, i.e. the “input format” and “output format”. You also need to define how this table should deserialize the data to rows, or serialize rows to data, i.e. the “serde”. The following options can be used to specify the storage format(“serde”, “input format”, “output format”), e.g. CREATE TABLE src(id int) USING hive OPTIONS(fileFormat ‘parquet’). By default, we will read the table files as plain text. Note that, Hive storage handler is not supported yet when creating table, you can create a table using storage handler at Hive side, and use Spark SQL to read it.
指定Hive表的存储格式
创建Hive表时,需要定义该表应如何从文件系统读取/写入数据,即“输入格式”和“输出格式”。 您还需要定义该表应如何将数据反序列化为行,或将行序列化为数据,即“ serde”。 以下选项可用于指定存储格式(“ serde”,“ input format”,“ output format”),例如 使用配置单元选项(fileFormat’parquet’)创建表src(id int)。 默认情况下,我们将以纯文本形式读取表文件。 请注意,创建表时尚不支持Hive存储处理程序,您可以在Hive端使用存储处理程序创建表,并使用Spark SQL读取表。
fileFormat
A fileFormat is kind of a package of storage format specifications, including “serde”, “input format” and “output format”. Currently we support 6 fileFormats: ‘sequencefile’, ‘rcfile’, ‘orc’, ‘parquet’, ‘textfile’ and ‘avro’.
inputFormat, outputFormat
These 2 options specify the name of a corresponding InputFormat and OutputFormat class as a string literal, e.g. org.apache.hadoop.hive.ql.io.orc.OrcInputFormat. These 2 options must be appeared in pair, and you can not specify them if you already specified the fileFormat option.
serde
This option specifies the name of a serde class. When the fileFormat option is specified, do not specify this option if the given fileFormat already include the information of serde. Currently “sequencefile”, “textfile” and “rcfile” don’t include the serde information and you can use this option with these 3 fileFormats.
fieldDelim, escapeDelim, collectionDelim, mapkeyDelim, lineDelim
These options can only be used with “textfile” fileFormat. They define how to read delimited files into rows.
文件格式
fileFormat是一种存储格式规范的软件包,其中包括“ serde”,“ input format”和“ output format”。目前,我们支持6种文件格式:“ sequencefile”,“ rcfile”,“ orc”,“ parquet”,“ textfile”和“ avro”。
inputFormat,outputFormat
这2个选项将对应的InputFormat和OutputFormat类的名称指定为字符串文字,例如org.apache.hadoop.hive.ql.io.orc.OrcInputFormat。这两个选项必须成对出现,如果已经指定fileFormat`选项,则不能指定它们。
Serde
此选项指定Serde类的名称。当指定fileFormat选项时,如果给定的fileFormat已经包含serde信息,则不要指定此选项。当前,“ sequencefile”,“ textfile”和“ rcfile”不包含Serde信息,您可以将此选项与这3种fileFormats一起使用。
fieldDelim,escapeDelim,collectionDelim,mapkeyDelim,lineDelim
这些选项只能与“文本文件” fileFormat一起使用。它们定义了如何将定界文件读取为行。
Interacting with Different Versions of Hive Metastore
One of the most important pieces of Spark SQL’s Hive support is interaction with Hive metastore, which enables Spark SQL to access metadata of Hive tables. Starting from Spark 1.4.0, a single binary build of Spark SQL can be used to query different versions of Hive metastores, using the configuration described below. Note that independent of the version of Hive that is being used to talk to the metastore, internally Spark SQL will compile against Hive 1.2.1 and use those classes for internal execution (serdes, UDFs, UDAFs, etc).
The following options can be used to configure the version of Hive that is used to retrieve metadata:
与Hive Metastore的不同版本进行交互
与Hive metastore的交互是Spark SQL对Hive的最重要支持之一,它使Spark SQL可以访问Hive表的元数据。 从Spark 1.4.0开始,使用以下描述的配置,可以使用Spark SQL的单个二进制版本来查询Hive元存储的不同版本。 请注意,与用于与Metastore进行通信的Hive版本无关,Spark SQL在内部将针对Hive 1.2.1进行编译,并将这些类用于内部执行(serdes,UDF,UDAF等)。
以下选项可用于配置用于检索元数据的Hive版本:
spark.sql.hive.metastore.version
1.2.1
Version of the Hive metastore. Available options are 0.12.0 through 2.3.3.
spark.sql.hive.metastore.jars
builtin
Location of the jars that should be used to instantiate the HiveMetastoreClient. This property can be one of three options:
builtin
Use Hive 1.2.1, which is bundled with the Spark assembly when -Phive is enabled. When this option is chosen, spark.sql.hive.metastore.version must be either 1.2.1 or not defined.
maven
Use Hive jars of specified version downloaded from Maven repositories. This configuration is not generally recommended for production deployments.
A classpath in the standard format for the JVM. This classpath must include all of Hive and its dependencies, including the correct version of Hadoop. These jars only need to be present on the driver, but if you are running in yarn cluster mode then you must ensure they are packaged with your application.
spark.sql.hive.metastore.sharedPrefixes
com.mysql.jdbc,
org.postgresql,
com.microsoft.sqlserver,
oracle.jdbc
A comma-separated list of class prefixes that should be loaded using the classloader that is shared between Spark SQL and a specific version of Hive. An example of classes that should be shared is JDBC drivers that are needed to talk to the metastore. Other classes that need to be shared are those that interact with classes that are already shared. For example, custom appenders that are used by log4j.
spark.sql.hive.metastore.barrierPrefixes (empty)
A comma separated list of class prefixes that should explicitly be reloaded for each version of Hive that Spark SQL is communicating with. For example, Hive UDFs that are declared in a prefix that typically would be shared (i.e. org.apache.spark.*).
spark.sql.hive.metastore.version
1.2.1
Hive Metastore的版本。可用的选项是0.12.0到2.3.3。
spark.sql.hive.metastore.jars
内建的
用于实例化HiveMetastoreClient的jar的位置。此属性可以是以下三个选项之一:
内建的
使用启用-Phive时与Spark程序集捆绑在一起的Hive 1.2.1。选择此选项时,spark.sql.hive.metastore.version必须为1.2.1或未定义。
专家
使用从Maven存储库下载的指定版本的Hive jar。通常不建议将此配置用于生产部署。
JVM的标准格式的类路径。该类路径必须包括所有Hive及其依赖项,包括正确的Hadoop版本。这些罐子只需要存在于驱动程序中,但是如果您以纱线簇模式运行,则必须确保将它们与您的应用程序打包在一起。
spark.sql.hive.metastore.sharedPrefixes
com.mysql.jdbc,
org.postgresql,
com.microsoft.sqlserver,
甲骨文
以逗号分隔的类前缀列表,应使用在Spark SQL和特定版本的Hive之间共享的类加载器加载。应该共享的类的一个示例是与元存储区进行对话所需的JDBC驱动程序。其他需要共享的类是与已经共享的类进行交互的类。例如,log4j使用的自定义追加程序。
spark.sql.hive.metastore.barrierPrefixes(空)
以逗号分隔的类前缀列表,应为Spark SQL与之通信的每个Hive版本显式重新加载。例如,在通常会被共享的前缀中声明的Hive UDF(即org.apache.spark。*)。
JDBC To Other Databases
Spark SQL also includes a data source that can read data from other databases using JDBC. This functionality should be preferred over using JdbcRDD. This is because the results are returned as a DataFrame and they can easily be processed in Spark SQL or joined with other data sources. The JDBC data source is also easier to use from Java or Python as it does not require the user to provide a ClassTag. (Note that this is different than the Spark SQL JDBC server, which allows other applications to run queries using Spark SQL).
To get started you will need to include the JDBC driver for your particular database on the spark classpath. For example, to connect to postgres from the Spark Shell you would run the following command:
JDBC到其他数据库
Spark SQL还包括一个数据源,该数据源可以使用JDBC从其他数据库读取数据。 与使用JdbcRDD相比,应优先使用此功能。 这是因为结果以DataFrame的形式返回,并且可以轻松地在Spark SQL中进行处理或与其他数据源合并。 JDBC数据源也更易于从Java或Python使用,因为它不需要用户提供ClassTag。 (请注意,这与Spark SQL JDBC服务器不同,后者允许其他应用程序使用Spark SQL运行查询)。
首先,您需要在spark类路径上包含特定数据库的JDBC驱动程序。 例如,要从Spark Shell连接到postgres,您可以运行以下命令:

Tables from the remote database can be loaded as a DataFrame or Spark SQL temporary view using the Data Sources API. Users can specify the JDBC connection properties in the data source options. user and password are normally provided as connection properties for logging into the data sources. In addition to the connection properties, Spark also supports the following case-insensitive options:
可以使用Data Sources API将远程数据库中的表作为DataFrame或Spark SQL临时视图加载。 用户可以在数据源选项中指定JDBC连接属性。 用户和密码通常作为连接属性提供,用于登录到数据源。 除了连接属性,Spark还支持以下不区分大小写的选项:
url
The JDBC URL to connect to. The source-specific connection properties may be specified in the URL. e.g.jdbc:postgresql://localhost/test?user=fred&password=secret
dbtable
The JDBC table that should be read from or written into. Note that when using it in the read path anything that is valid in a FROM clause of a SQL query can be used. For example, instead of a full table you could also use a subquery in parentheses. It is not allowed to specify dbtable and query options at the same time.
query
A query that will be used to read data into Spark. The specified query will be parenthesized and used as a subquery in the FROM clause. Spark will also assign an alias to the subquery clause. As an example, spark will issue a query of the following form to the JDBC Source.
SELECT FROM (<user_specified_query>) spark_gen_alias
Below are couple of restrictions while using this option.
It is not allowed to specify dbtable and query options at the same time.
It is not allowed to specify query and partitionColumn options at the same time. When specifying partitionColumn option is required, the subquery can be specified using dbtable option instead and partition columns can be qualified using the subquery alias provided as part of dbtable.
Example:
spark.read.format(“jdbc”)
.option(“url”, jdbcUrl)
.option(“query”, “select c1, c2 from t1”)
.load()
driver
The class name of the JDBC driver to use to connect to this URL.
partitionColumn, lowerBound, upperBound
These options must all be specified if any of them is specified. In addition, numPartitions must be specified. They describe how to partition the table when reading in parallel from multiple workers. partitionColumn must be a numeric, date, or timestamp column from the table in question. Notice that lowerBound and upperBound are just used to decide the partition stride, not for filtering the rows in table. So all rows in the table will be partitioned and returned. This option applies only to reading.
numPartitions
The maximum number of partitions that can be used for parallelism in table reading and writing. This also determines the maximum number of concurrent JDBC connections. If the number of partitions to write exceeds this limit, we decrease it to this limit by calling coalesce(numPartitions) before writing.
queryTimeout
The number of seconds the driver will wait for a Statement object to execute to the given number of seconds. Zero means there is no limit. In the write path, this option depends on how JDBC drivers implement the API setQueryTimeout, e.g., the h2 JDBC driver checks the timeout of each query instead of an entire JDBC batch. It defaults to 0.
fetchsize The JDBC fetch size, which determines how many rows to fetch per round trip. This can help performance on JDBC drivers which default to low fetch size (eg. Oracle with 10 rows). This option applies only to reading.
batchsize
The JDBC batch size, which determines how many rows to insert per round trip. This can help performance on JDBC drivers. This option applies only to writing. It defaults to 1000.
isolationLevel
The transaction isolation level, which applies to current connection. It can be one of NONE, READ_COMMITTED, READ_UNCOMMITTED, REPEATABLE_READ, or SERIALIZABLE, corresponding to standard transaction isolation levels defined by JDBC’s Connection object, with default of READ_UNCOMMITTED. This option applies only to writing. Please refer the documentation in java.sql.Connection.
sessionInitStatement
After each database session is opened to the remote DB and before starting to read data, this option executes a custom SQL statement (or a PL/SQL block). Use this to implement session initialization code. Example: option(“sessionInitStatement”, “”“BEGIN execute immediate ‘alter session set “_serial_direct_read”=true’; END;”"")
truncate
This is a JDBC writer related option. When SaveMode.Overwrite is enabled, this option causes Spark to truncate an existing table instead of dropping and recreating it. This can be more efficient, and prevents the table metadata (e.g., indices) from being removed. However, it will not work in some cases, such as when the new data has a different schema. It defaults to false. This option applies only to writing.
cascadeTruncate
This is a JDBC writer related option. If enabled and supported by the JDBC database (PostgreSQL and Oracle at the moment), this options allows execution of a TRUNCATE TABLE t CASCADE (in the case of PostgreSQL a TRUNCATE TABLE ONLY t CASCADE is executed to prevent inadvertently truncating descendant tables). This will affect other tables, and thus should be used with care. This option applies only to writing. It defaults to the default cascading truncate behaviour of the JDBC database in question, specified in the isCascadeTruncate in each JDBCDialect.
customSchema
The custom schema to use for reading data from JDBC connectors. For example, “id DECIMAL(38, 0), name STRING”. You can also specify partial fields, and the others use the default type mapping. For example, “id DECIMAL(38, 0)”. The column names should be identical to the corresponding column names of JDBC table. Users can specify the corresponding data types of Spark SQL instead of using the defaults. This option applies only to reading.
pushDownPredicate
The option to enable or disable predicate push-down into the JDBC data source. The default value is true, in which case Spark will push down filters to the JDBC data source as much as possible. Otherwise, if set to false, no filter will be pushed down to the JDBC data source and thus all filters will be handled by Spark. Predicate push-down is usually turned off when the predicate filtering is performed faster by Spark than by the JDBC data source.
网址
要连接的JDBC URL。特定于源的连接属性可以在URL中指定。例如jdbc:postgresql:// localhost / test?user = fred&password = secret
数据库表
应该从中读取或写入的JDBC表。请注意,在读取路径中使用它时,可以使用在SQL查询的FROM子句中有效的任何东西。例如,除了完整表之外,您还可以在括号中使用子查询。不允许同时指定dbtable和query选项。
询问
用于将数据读入Spark的查询。指定的查询将加括号并在FROM子句中用作子查询。 Spark还将为子查询子句分配一个别名。例如,spark将向JDBC源发出以下形式的查询。
选择<列>从(<用户指定的查询>)spark_gen_alias
以下是使用此选项时的一些限制。
不允许同时指定dbtable和query选项。
不允许同时指定query和partitionColumn选项。当需要指定partitionColumn选项时,可以使用dbtable选项来指定子查询,而分区列可以使用dbtable中提供的子查询别名来限定。
例:
spark.read.format(“ jdbc”)
.option(“ url”,jdbcUrl)
.option(“查询”,“从t1选择c1,c2”)
。加载()
司机
用于连接到该URL的JDBC驱动程序的类名。
partitionColumn,lowerBound,upperBound
如果指定了这些选项,则必须全部指定。另外,必须指定numPartitions。他们描述了从多个工作程序并行读取时如何对表进行分区。 partitionColumn必须是有关表中的数字,日期或时间戳记列。请注意,lowerBound和upperBound仅用于确定分区步幅,而不是用于过滤表中的行。因此,表中的所有行都将被分区并返回。此选项仅适用于阅读。
numPartitions
表读写中可用于并行处理的最大分区数。这也确定了并发JDBC连接的最大数量。如果要写入的分区数超过了此限制,我们可以通过在写入之前调用Coalesce(numPartitions)来将其降至此限制。
queryTimeout
驱动程序将等待Statement对象执行到给定秒数的秒数。零表示没有限制。在写入路径中,此选项取决于JDBC驱动程序如何实现API setQueryTimeout,例如,h2 JDBC驱动程序将检查每个查询的超时,而不是整个JDBC批处理的超时。默认为0。
fetchsize JDBC的获取大小,它确定每次往返要获取多少行。这可以帮助提高JDBC驱动程序的性能,该驱动程序默认为低获取大小(例如,具有10行的Oracle)。此选项仅适用于阅读。
批量大小
JDBC批处理大小,它决定每次往返插入多少行。这可以帮助提高JDBC驱动程序的性能。此选项仅适用于写作。默认值为1000。
隔离级别
事务隔离级别,适用于当前连接。它可以是NONE,READ_COMMITTED,READ_UNCOMMITTED,REPEATABLE_READ或SERIALIZABLE之一,与JDBC的Connection对象定义的标准事务隔离级别相对应,默认值为READ_UNCOMMITTED。此选项仅适用于写作。请参考java.sql.Connection中的文档。
sessionInitStatement
在向远程数据库打开每个数据库会话之后并开始读取数据之前,此选项将执行自定义SQL语句(或PL / SQL块)。使用它来实现会话初始化代码。示例:option(“ sessionInitStatement”,“”“ BEGIN立即执行“更改会话集” _serial_direct_read“ = true”; END;“”“)
截短
这是与JDBC编写器相关的选项。启用SaveMode.Overwrite时,此选项使Spark截断现有表,而不是删除并重新创建它。这样可以更有效,并防止删除表元数据(例如索引)。但是,在某些情况下(例如,新数据具有不同的架构时),它将不起作用。默认为false。此选项仅适用于写作。
级联截断
这是与JDBC编写器相关的选项。如果由JDBC数据库(当前为PostgreSQL和Oracle)启用并支持,则此选项允许执行TRUNCATE TABLE t CASCADE(在PostgreSQL的情况下,仅执行TRUNCATE TABLE t CASCADE可以防止无意中截断后代表)。这将影响其他表,因此应谨慎使用。此选项仅适用于写作。它默认为所讨论的JDBC数据库的默认级联截断行为,该行为在每个JDBCDialect的isCascadeTruncate中指定。
customSchema
用于从JDBC连接器读取数据的自定义架构。 例如,“ id DECIMAL(38,0),名称STRING”。 您还可以指定部分字段,其他使用默认类型映射。 例如,“ id DECIMAL(38,0)”。 列名应与JDBC表的相应列名相同。 用户可以指定Spark SQL的相应数据类型,而不必使用默认值。 此选项仅适用于阅读。
pushDownPredicate
用于启用或禁用谓词下推到JDBC数据源的选项。 默认值为true,在这种情况下,Spark将尽可能将过滤器下推到JDBC数据源。 否则,如果设置为false,则不会将任何过滤器下推到JDBC数据源,因此所有过滤器将由Spark处理。 当Spark进行谓词筛选的速度比JDBC数据源执行谓词筛选的速度快时,通常会关闭谓词下推。
Note: JDBC loading and saving can be achieved via either the load/save or jdbc methods
Loading data from a JDBC source
jdbcDF = spark.read
.format(“jdbc”)
.option(“url”, “jdbc:postgresql:dbserver”)
.option(“dbtable”, “schema.tablename”)
.option(“user”, “username”)
.option(“password”, “password”)
.load()
jdbcDF2 = spark.read
.jdbc(“jdbc:postgresql:dbserver”, “schema.tablename”,
properties={“user”: “username”, “password”: “password”})
Specifying dataframe column data types on read
jdbcDF3 = spark.read
.format(“jdbc”)
.option(“url”, “jdbc:postgresql:dbserver”)
.option(“dbtable”, “schema.tablename”)
.option(“user”, “username”)
.option(“password”, “password”)
.option(“customSchema”, “id DECIMAL(38, 0), name STRING”)
.load()
Saving data to a JDBC source
jdbcDF.write
.format(“jdbc”)
.option(“url”, “jdbc:postgresql:dbserver”)
.option(“dbtable”, “schema.tablename”)
.option(“user”, “username”)
.option(“password”, “password”)
.save()
jdbcDF2.write
.jdbc(“jdbc:postgresql:dbserver”, “schema.tablename”,
properties={“user”: “username”, “password”: “password”})
Specifying create table column data types on write
jdbcDF.write
.option(“createTableColumnTypes”, “name CHAR(64), comments VARCHAR(1024)”)
.jdbc(“jdbc:postgresql:dbserver”, “schema.tablename”,
properties={“user”: “username”, “password”: “password”})
Apache Avro数据源指南
Deploying
The spark-avro module is external and not included in spark-submit or spark-shell by default.
As with any Spark applications, spark-submit is used to launch your application. spark-avro_2.12 and its dependencies can be directly added to spark-submit using --packages, such as,
部署中
spark-avro模块是外部模块,替代情况下不包含在spark-submit或spark-shell中。
spark-avro_2.12及其依赖项可以使用–packages直接添加到spark-submit中,例如,与任何Spark应用程序一样,spark-submit用于启动您的应用程序。
./bin/spark-submit --packages org.apache.spark:spark-avro_2.12:2.4.5 …
For experimenting on spark-shell, you can also use --packages to add org.apache.spark:spark-avro_2.12 and its dependencies directly,
为了试验spark-shell,您还可以使用–packages直接添加org.apache.spark:spark-avro_2.12及其依赖项,
./bin/spark-shell --packages org.apache.spark:spark-avro_2.12:2.4.5 …
See Application Submission Guide for more details about submitting applications with external dependencies.
Load and Save Functions
Since spark-avro module is external, there is no .avro API in DataFrameReader or DataFrameWriter.
To load/save data in Avro format, you need to specify the data source option format as avro(or org.apache.spark.sql.avro).
有关提交具有外部依赖关系的应用程序的更多详细信息,请参见《应用程序提交指南》。
加载和保存功能
由于spark-avro模块位于外部,因此DataFrameReader或DataFrameWriter中没有.avro API。
要以Avro格式加载/保存数据,您需要将数据源选项格式指定为avro(或org.apache.spark.sql.avro)。
df = spark.read.format(“avro”).load(“examples/src/main/resources/users.avro”)
df.select(“name”, “favorite_color”).write.format(“avro”).save(“namesAndFavColors.avro”)















 1702
1702

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









