







1、背景介绍
如今deepseek全球大热,由于其开源免费,各大公司都在部署deepseek,于是我也尝试在公司鲲鹏920服务器上部署deepseek进行验证,由于鲲鹏920服务器没有显卡,只能算是尝试。
2、环境介绍
-
硬件环境:
鲲鹏920处理器 64核,主频2.6G
DDR容量 128G
硬盘容量 64GB
显卡 无
-
软件环境:
操作系统 openEuler 22.03 SP4
3、部署说明
首先下载ollama,网上一般都是直接联网下载并安装,用下面脚本一次搞定
curl -fsSL https://ollama.com/install.sh | sh不过ollama服务器在国外,下载经常不稳定,上述方法可能耗时很长,可以先下载ollma安装包,手动安装
下载地址:https://github.com/ollama/ollama/releases
选择arm64版本的下载
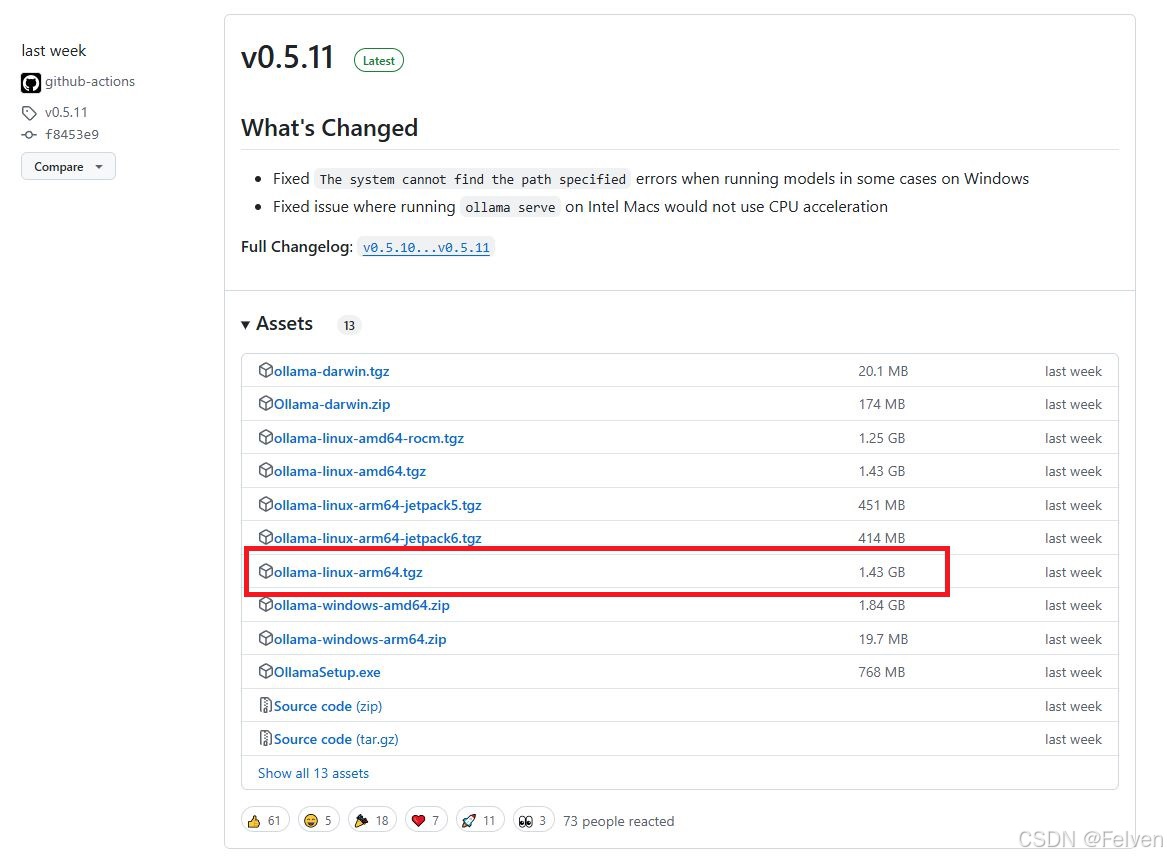
下载到系统后,用下面命令解压
sudo tar -C /usr -xvf ollama-linux-arm64.tgz然后给执行权限
chmod 777 /usr/bin/ollama添加ollama服务
touch /etc/systemd/system/ollama.service因为需要本地运行ollama.service内容如下HOST改为0.0.0.0:
[Unit]
Description=Ollama Service
After=networ-online.target
[Service]
ExecStart=/usr/bin/ollama serve
User=ollama
Group=ollama
Restart=ollama
Restart=always
RestartSec=3
Environment="OLLAMA_HOST=0.0.0.0:11434"
Environment="CUDA_VISIBLE_DEVICES=3,2"
Environment="OLLAMA_MODELS=/data/ollama/model"
[Install]
WantedBy=default.target
启动ollama服务
systemctl daemon-reload
systemctl enable ollama
systemctl start ollama再输入ollama serve启动,会打印以下内容
[root@localhost ollama]# ollama serve
2021/01/01 08:08:33 routes.go:1186: INFO server config env="map[CUDA_VISIBLE_DEVICES: GPU_DEVICE_ORDINAL: HIP_VISIBLE_DEVICES: HSA_OVERRIDE_GFX_VERSION: HTTPS_PROXY: HTTP_PROXY: NO_PROXY: OLLAMA_DEBUG:false OLLAMA_FLASH_ATTENTION:false OLLAMA_GPU_OVERHEAD:0 OLLAMA_HOST:http://127.0.0.1:11434 OLLAMA_INTEL_GPU:false OLLAMA_KEEP_ALIVE:5m0s OLLAMA_KV_CACHE_TYPE: OLLAMA_LLM_LIBRARY: OLLAMA_LOAD_TIMEOUT:5m0s OLLAMA_MAX_LOADED_MODELS:0 OLLAMA_MAX_QUEUE:512 OLLAMA_MODELS:/root/.ollama/models OLLAMA_MULTIUSER_CACHE:false OLLAMA_NOHISTORY:false OLLAMA_NOPRUNE:false OLLAMA_NUM_PARALLEL:0 OLLAMA_ORIGINS:[http://localhost https://localhost http://localhost:* https://localhost:* http://127.0.0.1 https://127.0.0.1 http://127.0.0.1:* https://127.0.0.1:* http://0.0.0.0 https://0.0.0.0 http://0.0.0.0:* https://0.0.0.0:* app://* file://* tauri://* vscode-webview://*] OLLAMA_SCHED_SPREAD:false ROCR_VISIBLE_DEVICES: http_proxy: https_proxy: no_proxy:]"
time=2021-01-01T08:08:33.076+08:00 level=INFO source=images.go:432 msg="total blobs: 7"
time=2021-01-01T08:08:33.076+08:00 level=INFO source=images.go:439 msg="total unused blobs removed: 0"
time=2021-01-01T08:08:33.076+08:00 level=INFO source=routes.go:1237 msg="Listening on 127.0.0.1:11434 (version 0.5.11)"
time=2021-01-01T08:08:33.076+08:00 level=INFO source=gpu.go:217 msg="looking for compatible GPUs"
time=2021-01-01T08:08:33.090+08:00 level=INFO source=gpu.go:377 msg="no compatible GPUs were discovered"
time=2021-01-01T08:08:33.090+08:00 level=INFO source=types.go:130 msg="inference compute" id=0 library=cpu variant="" compute="" driver=0.0 name="" total="124.4 GiB" available="121.9 GiB"下载deepseek大模型,由于deepseek模型服务器就在国内,下载速度还是挺快的
ollama run deepseek-r1:1.5b可以下载多个,只要硬盘容量够的话
ollama run deepseek-r1:7b下载完毕后能够通过ollama list查看本地模型
[root@localhost ollama]# ollama list
NAME ID SIZE MODIFIED
qwen2.5:7b 845dbda0ea48 4.7 GB 4 years from now
qwen2.5:1.5b 65ec06548149 986 MB 4 years from now 运行模型进行测试,实测发现没有显卡的情况下只能运行1.5B的
[root@localhost ollama]# ollama run qwen2.5:1.5b
>>> write a hello world code
Sure! Below is an example of a simple "Hello World" program in several
programming languages:
1. **Python**:
```python
print("Hello World")
```
2. **JavaScript** (using `console.log`):
```javascript
console.log("Hello World");
```
3. **Java**:
```java
public class HelloWorld {
public static void main(String[] args) {
System.out.println("Hello World");
}
}
```
4. **C++**:
```cpp
#include <iostream>
int main() {
std::cout << "Hello World";
return 0;
}
```
5. **C#** (using `Console.WriteLine`):
```csharp
using System;
class Program {
static void Main(string[] args) {
Console.WriteLine("Hello World");
}
}
```
6. **Ruby**:
```ruby
puts "Hello World"
```
7. **Swift** (using `print`):
```swift
print("Hello, World!")
```
Each of these examples prints the text "Hello World" to the console or standard output, which
is a common way to demonstrate basic syntax and structure in different programming languages.
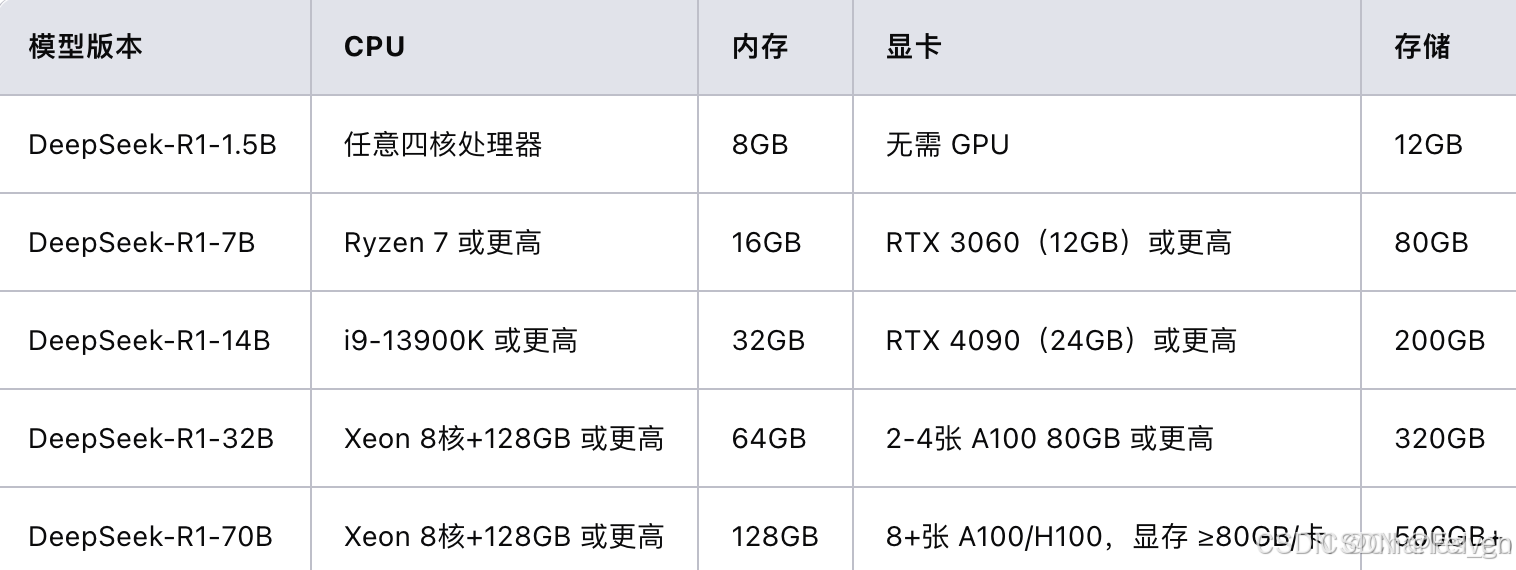
>>> 各个模型与需要的配置如下,看来处理器强没有显卡也没用。


















 404
404

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









