







这里正式进入 javase 面向对象语言部分
正如 JavaSE 拾遗(0)——JavaSE 主线 中讲到的第三条主线,我打算在总结 javase 面向对象语言部分的第一层结构用这条主线——javase 程序的组成元素。选择这条主线,是为了契合面向对象分层表达的思想(继承就是分层表述的体现,其实分层表达是自然的思考方式,现实中为了方便对事物的表达和记忆,产生了简化对事物的描述的方式,比如用父类代表子类的描述,这种方式其实就是分层表达法,并且分层表达和对比表达通常结合使用的,和组合式表述比较分层表述增加了父类子类的耦合性),但这个不是从具体到抽象的分层表达,而是组合的表述中的分层表述。
站在静态角度看,javase 程序的组成元素主要包括4个层次的内容,包、类、函数、字段、变量。最上层的组成元素是 javase 应用程序系统的话,javase 应用程序系统直接下一层组成元素是包,一个 java 应用程序系统由1个或者多个包构成。包是由一个或者多个类构成,在源码是各个 java 类,在字节码是各个 *.class 文件(ps:接口、枚举、注解我也算在类里面),在jvm中就是各个 Class 类的实例;类的组成元素有 字段(ps:包含 final 修饰的变量)、函数、类(成员类);函数的组成元素有 局部变量、类(局部类)、语句;变量不能在分(ps:变量是最小的数据单元,函数是最小的行为单元),类是最小的封闭单元。
站在动态角度看,在程序执行的时候变量分为引用和基本类型变量,而类的作用要实例化为对象才能体现出来,所以要多一个基本组成元素——对象。
如果从 OOD 设计来看,基本类型变量和引用类型变量都可以当做同样的元素来使用,就是其存储数据的作用,在实现的时候必须有基本类型变量形式的存在,否则“引用类型变量——指向引用”会无限递归下去“;在写代码操作变量的时候,这两种变量也会有区别,基本类型变量提供了对数据的直接描述和操作,引用类型变量还提供了对封装的数据操作的方法(通过 dot 运算符实现,引用类型的直接操作只支持赋值和获取引用),设计的时候我把基本类型变量看做引用类型变量的子集(ps:所以我认为是不是未来的高级程序设计语言会没有基本类型变量,直接把这个封装起来嘛,一个东西干嘛搞两套内容,有木有!)。
从JVM 角度上看 jvm 支持8种基本数据类型,和 reference 类型。
从 JVM 角度来看,一个应用程序主要由三部分和JVM配合完成功能,一个是 stack 中的局部变量和操作数,一个是 heap 中的对象,再有一个就是 方法区中的 Class 字节码实例。在做 OOD 的时候,javase 已有的类库也可以算作组成元素,设计的时候一般先从抽象出发,所以这些具体的内容可以先不考虑,先抽象后具体(先接口后实现),先整体后局部(先上层后底层)。
下面具体讲解 javase 面向对象语法规则,先从最底层元素"变量"说起,这样才符合我们的组合思维方式。
与变量相关的部分:
- 关键字
- 标识符
- 数据类型
- 常数
- 常量、变量
关键字
特点:java 语言中所有的关键字都是小写
标识符
java 中标识符命名规范:
包名都小写 xxxxyyyy
类名和接口名首字母都大写 XxxxYyyy
变量名和函数名首个单词首字母小写,其他单词首字母大写 xxxxYyyy
常量(这里是指 final 修饰的变量)名字母都大写,每个单词用下划线连接 XXXX_YYYY
数据类型
8种基本数据类型
又根据数据在实际生活中的意义的不同,把8种基本数据类型分为3类
布尔型 boolean
(能做什么)布尔型数据用来表达现实中的逻辑结果真、假,常常在程序里有程序执行的条件的地方使用(是什么)true、false
字符型 char
(能做什么) 字符型数据具有语言意义上的意义,可以用来表示我们语言和生活中的字符,用来交流
(是什么)字符型数据用单引号括起来 char c = 'a'; 在编译完成后的 class 文件中字符数据使用 Unicode 字符集,所以 java 字符数据是 16 bits,Unicode 代码点机制,而在 java 源码中,myeclipse 一般默认设置的是 utf-8 编码,我们的操作系统一般是 gbk 编码。数值型 Number
(能做什么)数值型数据用来表达数值的,数值和数学上的数一个意思,一个数值除了是一个符号外,还有数学意义上的可度量的意义
整数
类型
- byte 1字节有符号
- short 2字节有符号
- int 4字节有符号
- long 8字节有符号
表示方式 3种,10进制、8进制零开头、16进制零x开头默认整型常数是 int 类型long 类型常量后面加 l 或者 L, long number = 50L
浮点
- float 4字节
- double 8字节
默认 浮点 型常数是 double 类型因为相同浮点数可能有不同精度的,浮点数只要经过运算都有可能改变其精度,所以程序中一般不能用“==”来做比较,一般用大于小于来比较(关于 java 中浮点数精度 问题)。
从我们生活意义上看,整数是浮点数的子集;从计算机底层上来看,但是整数和浮点数在内存从的保存形式区别很大,他们的操作方法差别也很大,这就是为什么整数可以进行逻辑运算,而浮点数不行,这块参照计算机原理部分,保留这个区别我想是为了方便 c 程序猿。其实 JVM 很多运算指令把 boolean char byte short 类型的运算都转为 int 类型的运算。
引用数据类型
- null、类、对象
- 接口
- 数组
- String
(为什么) 引用数据类型和基本数据类型数据,最大区别就是在存储形式上,是否有引用数据的保存,基本数据类型,只有数据内容的保存,引用数据类型,还保存有数据内容的引用我们把计算机表示的数据分为两部分,一个是数据本身,一个就是数据类型,某种数据可以属于多种数据类型(向上转型),数据类型涉及到数据在计算机中的存储方式和使用方式,引用数据类型和基本数据类型就是从这个角度来分的。但是计算机中所有东西都是数据,数据类型也是数据,所有又专门搞了一种数据类型来描述数据类型这种数据这就是 Type 接口。在 java 里面数据类型这种数据主要可以分为 class interface enum @interface 数组 基本数据类型 6大种,它们都以 Class 这种数据类型存储和使用,class enum @interface 数组 它们都有实例,其实例都是 Ojbect 类型,interface 没有自己类型的实例,但有 class 类型的实例,基本数据类型直接保存数据。String 类型比较特殊,因为 JVM 中一般是用 c、c++ 写的,它们自身就支持 String 类型数据,而 jvm 基本数据类型中是没有 String 类型的,但是在 JVM 的常量池中,却有 utf-8 类型的结构,用来间接存储字符串,比如类名、函数名、字段名、程序中的字符串常量,间接是因为上述类型不是直接持有 utf-8 结构的索引,而是它们自身对应的结构的索引,它们自身机构中最终会索引到 utf-8 结构上。所以 String 类型的实例通常保存在方法区中的类常量池中,而不是保存在堆中。Class 这种数据类型的实例和 String 也一样,保存在方法区中。
常数
根据数据的实际意义常量分为:
- 数值类型,其中包含 整数类型,如12,小数类型,如12.5
- 布尔类型 true false
- 字符类型 字符串类型 如 'a'、\\、'%'
- 引用类型,主要是 null 和 对象的引用(没有常数的对象引用,只能通过反射和枚举才能用 String 类型数据常数获得对象引用)
常量、变量
变量的声明:
从实现层面来看,变量的声明提供了变量的大小和存储位置的说明(如果是字段,JVM 通过符号索引来确定它的存储位置,具体见:对象的内存结构),变量的类型,说明了要创建的存储单元的大小,变量的名字,说明了创建的存储单元的存储位置
从抽象层面来看,变量的声明是程序员和计算机之间的通信,是通过计算机提供的接口告诉计算机要创造一个什么样的信息存储单元
和动态语言相比,java 这种静态语言在变量声明的时候就指定了变量的大小,动态语言是执行程序的时候根据变量值的类型决定变量的大小,这好比一个人的人名没有类型,但是这个人这个实体对象是有类型的。
和弱类型语言相比,java 这种强类型语言,在使用变量的时候,需要先声明变量的类型。而弱类型语言是编译器根据变量的值自动决定变量的类型,并且变量的值的类型改变时,变量的类型亦自动改变
变量的使用:
- 变量内容的引用
- 修改变量的内容
数据类型转换:
class HelloWorld
{
public static void main(String [] args)
{
short s = 1;
System.out.println(s);
}
}这段代码用 javap 反汇编之后得到:
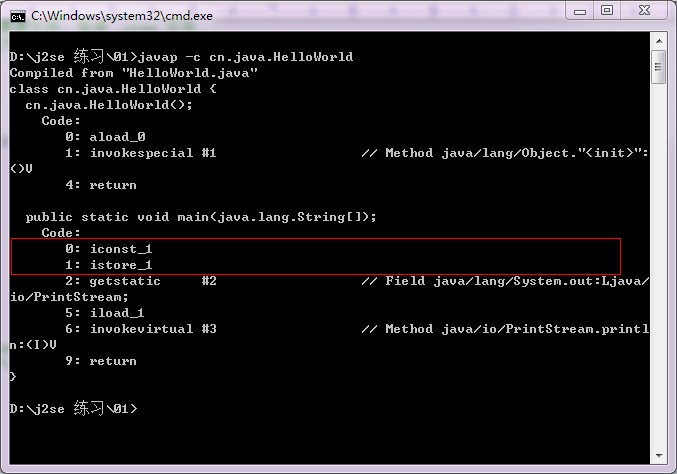
short s = 1; 这个表达式里面 1 是默认的整型,那么就是 int 类型了,s 是 short 类型,这样的话,相当于默认给1变为(short)1,这种默认的行为,java 编译器是会检查数据类型转换是否可行的,因为是默认,容易犯错误,而不像显示的强制类型转换,开发者是有意识的使用类型转换,此时 java 编译器对类型转换的要求就没有那么严格。隐式转换的时候,在 java 编译器检查类型类型转换遵循“ java 编译器能判断没有越界的不会报错,否则会报错。”。因为 1 是常数,java 编译器自然可以判定有没有越界。而 short s = s + 1; s + 1 是个变量表达式,必须在程序执行的时候,才知道表达式的值,此时 java 编译器就会报错。short s += 1;这个是个特殊的情况,在这里老毕有一句话解释了,说凡是复合赋值运算符都是带有强制类型转换的,也就是显示的强制类型转换,那么 java 编译器就不会报错了,因为你一旦使用复合运算符,java 编译器认为你是有意识的使用类型转换,为什么java编译器这样设定,我觉得可能是复合赋值运算符本来就是给高手准备的一种简易表达形式,java 编译器把使用者设为高手,自然要限制少一点。














 211
211











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









