







论文信息
WSDM 2018
Personalized Top-N Sequential Recommendation via Convolutional Sequence Embedding
Jiaxi Tang (Simon Fraser University); Ke Wang (Simon Fraser
University)
原文地址:https://arxiv.org/abs/1809.07426
Abstract
Top- N sequential recommendation models each user as a sequence of items interacted in the past and aims to predict top- N ranked items that a user will likely interact in a “near future”.
交互的顺序表示顺序模式(sequential pattern)扮演很重要的角色,一般一个序列中最近(more recent)的交互物品对下一个物品有着更大的影响。为了充分利用这个结论,我们提出了一个模型Caser,这个模型的主要思想是:在时间和潜空间上我们将一系列最近物品(recent items)embed到一个image中,然后像用卷积过滤器学习image的局部特征一样去学习顺序模式(sequential pattern)。这个方法为捕捉用户的general preferences和sequential patterns提供了一个统一的灵活的网络结构。
Introduction
大多数系统中,Top-N recommendation都只基于用户的general preferences(long term and static
behaviors),而没有考虑the recency of
items.。另一类用户行为是sequential patterns,即用户的下一个交互物品或动作更可能和用户最近的活动或最近交互的物品有关。
1 Top-N Sequential Recommendation
给定用户U与物品的交互序列S_u=(S_u,1,…,S_u,|Su|),这里1,…,|Su|表示的是用户与物品交互的相对顺序,即S_u,1表示用户u交互的第一个物品。基于这个交互序列S_u,我们的目标是通过综合考虑用户的general preferences和sequential patterns,为每个用户推荐一个物品列表,以最大程度上满足用户u的未来需求。
2 Limitations of Previous Work
早期top-N sequential Recommendation的工作是基于马尔可夫链的,L-阶马尔可夫链式是基于前L个动作进行推荐的。本质上,一阶马尔科夫链就是通过最大化似然估计来学习一个item-to-item的转移矩阵。基于马尔可夫链的工作有FPMC、Fossil等,但这些方法都有下面几个limitations。
(1)没有建模union-level sequential patterns
基于马尔科夫链的模型只考虑了point-level sequential patterns,也就是说它只是考虑了之前的每个actions单独对target action产生的影响。Fossil虽然考虑了高阶马尔科夫链,但是它只是将每个物品的潜表示进行了权重和操作,这并不足以建模union-level的影响。

(2)没有允许skip behavior
这里的skip behaviors是说过去的行为可能会跳过几步,但仍然对后续动作是有强影响的。(这里举个例子,一个游客依次在机场、旅店、餐馆、酒吧和旅游景点办理手续,虽然机场、旅店之后紧接着的不是旅游景点,但直觉上他们是有着比较强的关联的,相反餐馆、酒吧对旅游景点的影响倒是没那么大)。但这是基于马尔可夫链的方法不能做到的。
为了为以上两点提供证据,作者这里进行了一个小实验,这里就不介绍了。
3 Contributions
为了解决上述两个问题,一个叫Caser的模型提出了,这个模型的 颖性在于我们将前L个物品表示为一个L×d的矩阵E,d是latent dimensions,矩阵E的行保持着交互物品的顺序。然后我们将这个矩阵E视为L个物品的一个image,通过不同的卷积过滤器去学习这 image的局部特征(也即在潜空间中学习sequential patterns)。主要 contributions在于:(1)通过使用水平和垂直两个过滤器Caser可以捕捉到point-level,union-level和skip behaviors;(2)Caser可以同时建模用户的general preferences 和sequential patterns,并且在单个统一框架中概括了几种现有的state-of-the-art的方法。
Proposed Methodology
该模型采用卷积神经网络(CNN)学习序列特征(sequential features),采用隐因子模型(LFM)学习用户特征。Caser网络设计的目标是多重的:在union-level和point-level捕获用户的一般偏好和顺序模式,并捕获跳过行为,所有这些都在未观察到的空间中。caser 由三个部分组成,embedding layer,convolutional layer, fully-connected layer。对于每个用户u,我们从用户序列S_u中提取每L个连续项作为输入,并将它们的下一个T项作为目标,如下图左侧所示。这是通过在用户序列上滑动一个大小为L +T的窗口来实现的,每个窗口都为u生成一个训练实例,它由一个三元组(u、前L项、后T项)表示。

1、 Embedding Look-up
Caser通过将前L个物品的embedding(第i个物品的embedding表示为Qi)送入神经网络去捕捉顺序特征(sequence features)。Embedding look-up操作就是将L个物品的embedding堆叠在一起,生成一个矩阵E(u,t),u指的是用户u,t指的是time step
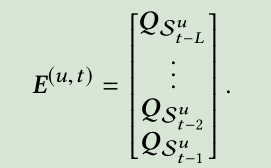
除了item embedding,对每个用户u我们还有一个embedding P_u∈R^d (question:这里的P_u是通过什么得到的呢?是通过参数学习的)
2、 Convolutional Layers
前面已经说过,我们通过将前L个物品构成的L×d矩阵E视为这L个物品在潜空间中的一个“image“,将sequential patterns看成是这个image的局部特征。这样我们就可以得到sequential patterns。
(1) Horizontal convolutional Layer
这里我们需要n个水平过滤器,每个过滤器表示为F^k∈R(h×d)h∈{1,…,L}
F^k:指的是第k个过滤器;h是过滤器的高度;d是物品的embedding维度
如果我们选择前L个物品L=4,则h∈{1,2,3,4},如果每个h有两个过滤器的话,那我们就有了8个过滤器。(question:这里一个高度对应两个过滤器的话,怎么保证两个过滤器学到的是不一样的特征呢?)
现在让我们考虑第k个滤波器,F^k从矩阵E的top到bottom滑动,从水平维度上与物品进行交互,每一次卷积操作如下:
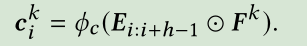

则第k个过滤器的结果为一个向量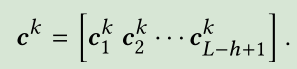 ,然后我们通过max pooling操作得到第k个滤波器抽取的最重要的特征max(c^k),最终我们得到n个过滤器捕捉到的所有特征表示为o
,然后我们通过max pooling操作得到第k个滤波器抽取的最重要的特征max(c^k),最终我们得到n个过滤器捕捉到的所有特征表示为o 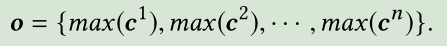
至此,我们就得到了union-level patterns.
(2) Vertical Convolutional Layer
假设有_n个垂直过滤器_F^k ∈RL×1.每一个垂直过滤器_F^k 通过在矩阵E上滑动d次(从左到右),产生一个垂直的卷积结果_c^k 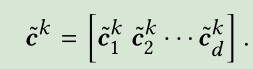
对于内积计算来说,很容易证明这个结果等价于矩阵E的L行上的加权求和,其中_F^k为权重, ,这样我们就可以聚合前L个物品的embedding。通过_n个垂直过滤器,对每个用户我们有_n个加权和。(因为我们希望保持每个潜在维的聚合,所以不需要对垂直卷积结果进行最大池化操作)(question:那这样学到的_n个加权和表示什么意思呢?_n个不同的聚合的优势在哪儿呀?)
,这样我们就可以聚合前L个物品的embedding。通过_n个垂直过滤器,对每个用户我们有_n个加权和。(因为我们希望保持每个潜在维的聚合,所以不需要对垂直卷积结果进行最大池化操作)(question:那这样学到的_n个加权和表示什么意思呢?_n个不同的聚合的优势在哪儿呀?)
3、 Fully Connected Layer
我们将两个卷积结果级联起来然后送入全连接层,通过全连接层,我们可以得到more high-level and abstract的特征z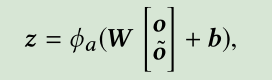
最后,为了捕捉用户的general preferences,我们将z和user embedding级联起来,并进行如下计算得到最终输出值: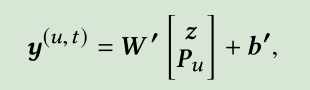
这里W,W’和b,b’分别是权重矩阵和偏置
关于为什么最后要用全连接层?
因为卷积抽取的是局部特征,全连接就是把前面的局部特征重新通过权值矩阵组成一个完整的图,因为用到了所有的局部特征,所以叫全连接。
在CNN结构中,经多个卷积层和池化层后,连接着1个或1个以上的全连接层。全连接层中的每个神经元与其前一层的所有神经元进行全连接,全连接层可以整合卷积层或者池化层中具有类别区分性的局部信息。为了提升 CNN 网络性能,全连接层每个神经元的激励函数一般采用 ReLU 函数。最后一层全连接层的输出值被传递给一个输出,可以采用 softmax 逻辑回归(softmax regression)进行分类,该层也可称为 softmax 层(softmax layer)。














 1128
1128











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









