







摘要
top-n序列推荐模型讲每个用户过去有过交互的商品看成一个序列,目的是来预测用户未来可能有交互行为的商品的前N个的排序。这个交互作用的顺序揭示了序列patterns扮演了一个重要的角色,揭示了序列中最近的项目对下一个项目的影响更大。在这篇论文中提出了convoltional sequence embedding recommendation model (caser).其主要思想是将在时间和空间上最近的项目序列形成一个”“图像”,并且使用卷积滤波器学习序列pattern作为图像的局部特征。这种方法提供了一个统一的、可执行的网络结构,用于捕获一般首选项和顺序模式。
introduction
给定所有用户的顺序,目标是通过综合考虑一般偏好和顺序模式,向每个用户推荐一个项目列表,最大限度地满足他们未来的需求。不像传统的top-N推荐,top-N顺序的推荐模型将用户行为看作与一个商品的序列,而不是等同于商品的集合。Caser使用水平和垂直卷积过滤器捕获点级、单位级和跳过行为的顺序模式。Caser对用户的一般偏好和顺序模式进行建模,并在一个统一的框架中概括了几种现有的最先进的方法。
model
该模型采用卷积神经网络(CNN)学习序列特征,采用隐因子模型(LFM)学习用户特征。Caser网络设计的目标是多重的:在统一级和点级捕获用户的一般偏好和顺序模式,并捕获跳过行为,所有这些都在未观察到的空间中。如图3所示,Caser由三个组件组成:嵌入查找层、卷积层和全连接层。caser 由三个部分组成,embedding layer,convolutional layer,fully-connected layer.对于每个用户u,我们从用户序列Su中提取每L个连续项作为输入,并将它们的下一个T项作为目标,如图3左侧所示。这是通过在用户序列上滑动一个大小为L +T的窗口来实现的,每个窗口都为u生成一个训练实例,它由一个三元组(u、前L项、后T项)表示。
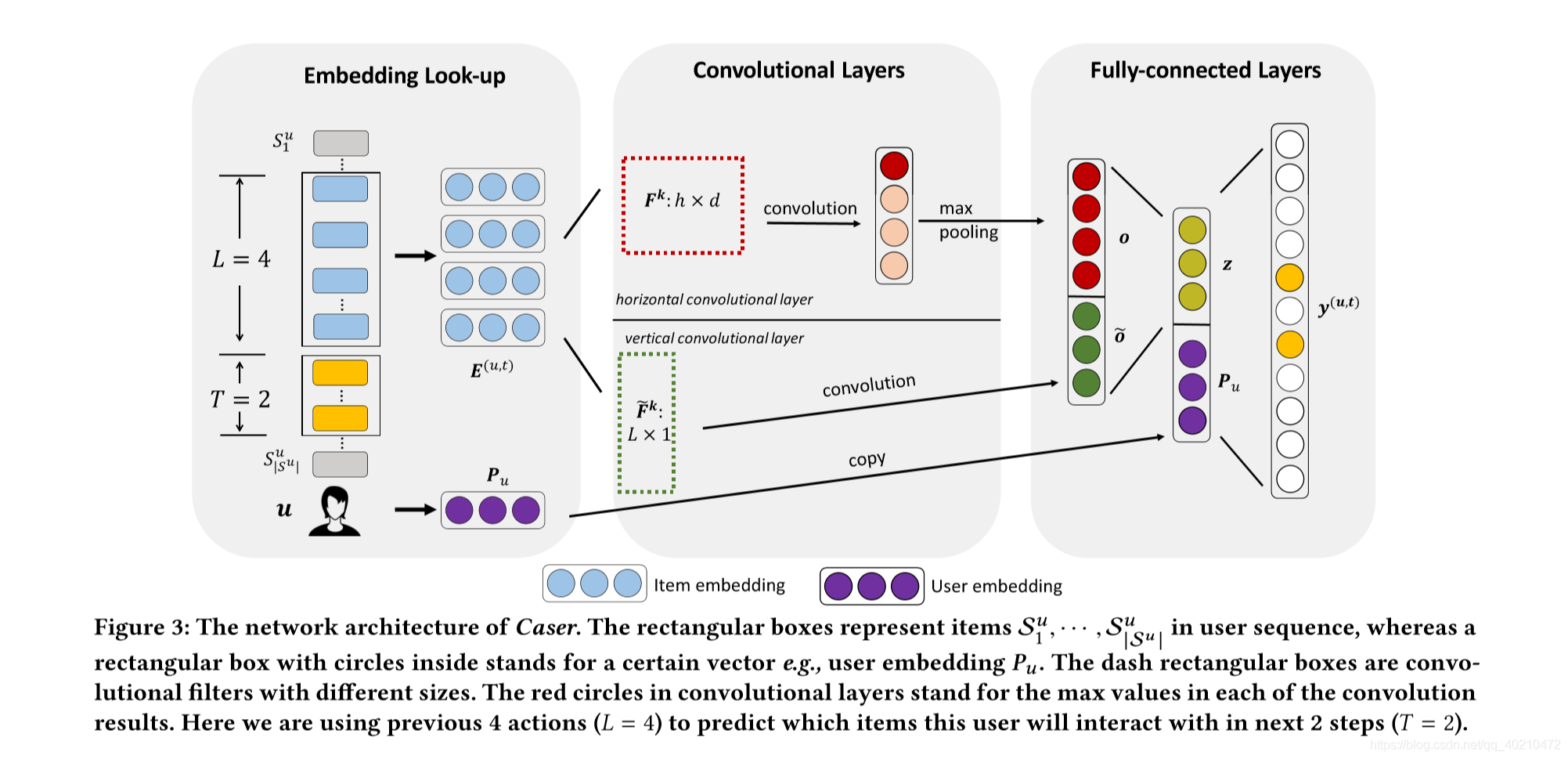
embedding layerCaser
通过向神经网络嵌入先前的项目来捕获潜在空间中的序列特征。将长为L的序列映射成embedding。将其堆积在一起。除了商品的embedding,用户的特征是用LFM生成的,在图中标注为紫色。###cNN借鉴CNN在文本分类[12]中的思想,我们的方法考虑了L×d矩阵E为前L项在潜空间中的“像”,将序列模式作为该“像”的局部特征。这种方法允许使用卷积滤波器来搜索顺序模式。
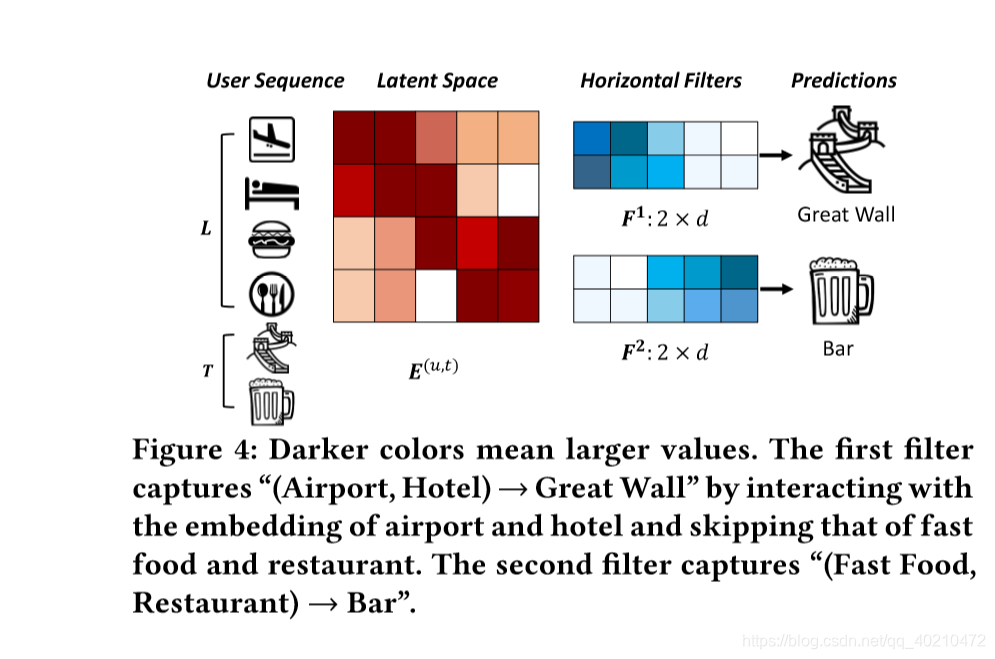
图4显示了两个“水平过滤器”,它们捕获两个联合级别的顺序模式。这些过滤器,表示为h×d矩阵,高度h = 2,全宽等于d。它们通过在E矩阵的行上滑动来接收序列模式的信息。类似地,一个“垂直lter”是一个L×1矩阵,它会滑过去E的列。与图像识别不同,“图像”E不是给定的,因为所有项的嵌入Qi必须与所有过滤器同时学习。
水平卷积网络
这层,在图三第二部分的上边网络上有N个水平滤波器。举个例子,如果L=4,那个可能有8个滤波器,每个h= {1,2,3,4}对应两个滤波器。Fk滤波器会从上到下滑动,并与物品的横向维度发生相互作用,下面是卷积公式,其实就是E中的几行与滤波器做卷积然后为卷积层加一个非线性激活函数。
下面这个是矩阵的行i到行i-h+1与滤波器的作用结果。
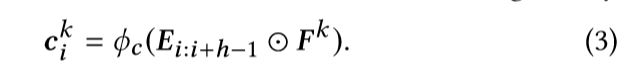
所以最终的Fk滤波器卷积结果为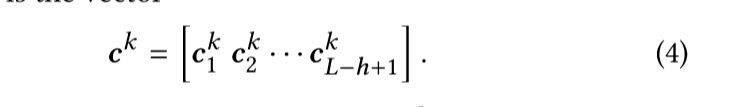 如果h=2的时候,则生成的ck的shape是4-2+1 = 3 --3*1.然后,我们对ck应用一个最大池化操作,从这个特定过滤器生成的所有值中提取最大值。最大值捕获过滤器提取的最显著的特征。因此,对于这一层中的n个字符,输出值 shape为n
如果h=2的时候,则生成的ck的shape是4-2+1 = 3 --3*1.然后,我们对ck应用一个最大池化操作,从这个特定过滤器生成的所有值中提取最大值。最大值捕获过滤器提取的最显著的特征。因此,对于这一层中的n个字符,输出值 shape为n
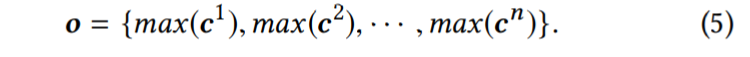
水平滤波器通过嵌入e与每一个连续的h项进行交互。通过学习嵌入和过滤器,可以将编码目标项预测误差的目标函数最小化(更多信息见第3.4节)。通过不同高度的滑动杆,无论位置如何,信号都能被接收到。因此,可以训练水平过滤器来捕获具有多个union大小的union级模式.
####垂直卷积网络
该层被展示在图3的下方,我们使用波浪号作为该层的象征,假设这里有n个滤波器,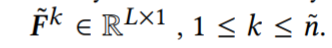
每个滤波器Fk与列交互从左到右滑d次在矩阵E上,产生垂直c˜k卷积结果1*d
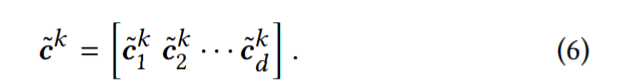
内积的互动,很容易验证这个结果等于加权求和的E和F˜k L行权重:
因此,使用垂直lters,我们可以学习将之前L项的嵌入进行聚合,类似于Fossil的[6]加权和,将之前L项的潜在表示进行聚合.
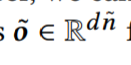
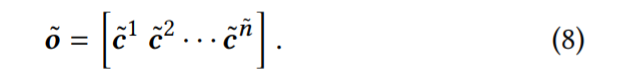
以上为垂直滤波器的输出。
全连接层
我们将两个卷积层的输出连接起来,并将紧密连接的神经网络层馈入其中高级和摘要特征。
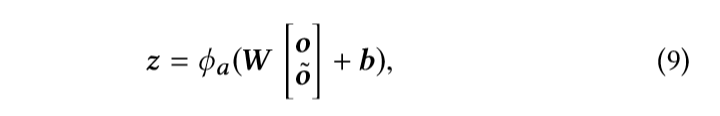
 是权重矩阵,将连接层投影到d维隐层的权重矩阵。z∈Rd就是我们所说的卷积序列嵌入,它包含了之前项的所有序列特征。
是权重矩阵,将连接层投影到d维隐层的权重矩阵。z∈Rd就是我们所说的卷积序列嵌入,它包含了之前项的所有序列特征。
为了捕捉用户的一般偏好,我们嵌入了一个用户embedding pu,并将两个d维向量z和pu连接在一起,然后将它们投射到一个带有|I|节点的输出层中(I的值是正样本加负样本的值的和)
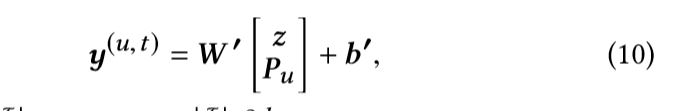
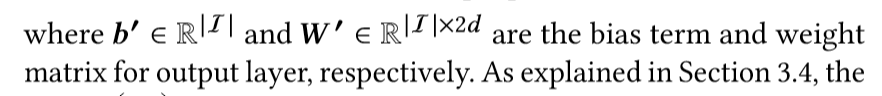
网络训练
极大似然估计为:
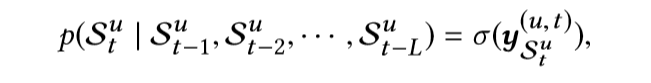 表示在之前的行为序列中观测出的下一个item的概率。然后使用极大似然估计法,对概率进行累乘,构造似然函数。
表示在之前的行为序列中观测出的下一个item的概率。然后使用极大似然估计法,对概率进行累乘,构造似然函数。
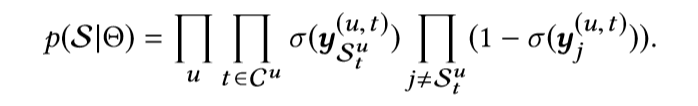
对其进行负对数运算,我们得到目标损失函数,也就是二进制交叉熵损失,i为正样本,j为负样本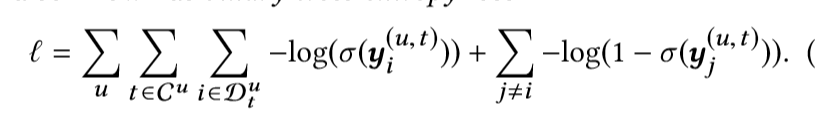
我们最大化概率也就是最小化损失函数。通过最小化损失函数来得到最优参数。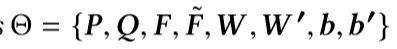
我们为每一个target都找到3个负样本。超参数通过验证集来调整。使用Adam进行优化算法。batchsize为100.为防止过拟合,L2范数适用于所有模型参数,并在全连接层上使用了50%的dropout 。
推荐
在获取到训练好的神经网络后,我们为每个用户进行推荐,我们使用户的隐层状态PU与它的最后L个items的表达作为网络输入。我们推荐输出层最高的N个值。注意,target itemsT 参数在训练中使用,而N是训练后推荐的参数。
connection to existing models
实验
- 数据集:只有当数据集包含顺序模式时,顺序推荐才有意义。为了识别这类数据集,我们将序列关联规则挖掘应用于多个公共数据集,并计算它们的序列强度。
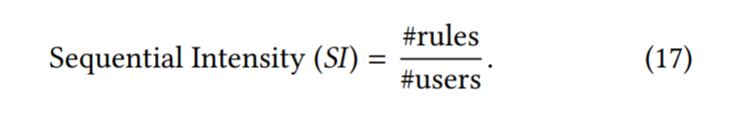
- 分子是使用最小支持阈值(即(5)及置信度即, 50%),马尔科夫阶L从1到5。分母是用户总数。我们使用SI来估计数据集中序列信号的强度。
- 我们将每个用户序列中70%的操作作为训练集,并使用接下来10%的操作作为验证集来搜索最优超参数设置对所有模型。每个用户序列中其余20%的操作用作评估模型性能的测试集
- 测量准则:
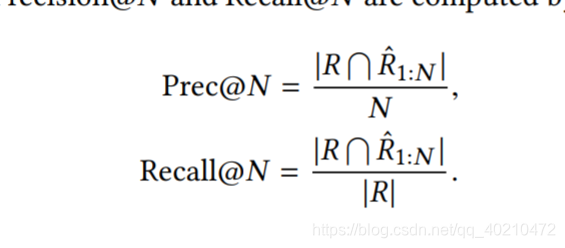
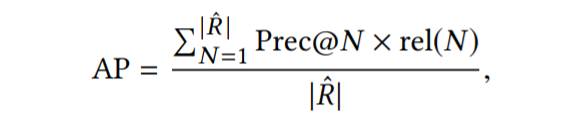
rel (N) = 1如果第N个项目在R Rˆ平均意味精度(MAP)是所有用户AP的平均值。















 1199
1199











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









