







最近对程序语言如何从 源代码->字节码(or 机器码)->执行 产生了兴趣,为此从今天开始,给自己制定了一个学习计划,
目的是能够对Java源代码如何到class文件字节码,再如何在JVM上执行有比较深入的理解。
学习的第一步,就从难啃的编译原理开始。
之前对编译原理有一定了解,尤其是工作中对词法分析比较了解,所以学习从语义分析开始,
对应的龙书页码是 P195
1. 相关定义
SSD :语法制导定义。
每个文法符号引入一组属性,每个文法的产生式都配备一组与之关联的语义计算规则。
属性可以分为两类:
综合属性:用于自下而上传递信息,属性值可以从其子结点的属性值计算出来的。
继承属性:自上而下传递信息,是由该结点兄弟结点和父结点的属性值计算出来的。
2. 求值
可以在进行语法分析形成语法分析树过程中配合语义规则进行SSD求值。
从书中的例子上看,配合自下而上语法分析的SSD求值可以从低向上进行,对应的是综合属性求值。
而配合自上而下的语法分析的SSD求值涉及继承属性求值,求值顺序并不那么直观。可以参考例子5.3。
3. 依赖图与求值顺序
为了便于进行SSD求值,引入了依赖图的概念,一棵语法分析树如果有了对应的依赖图,就可以按照依赖图的拓扑排序进行求值。
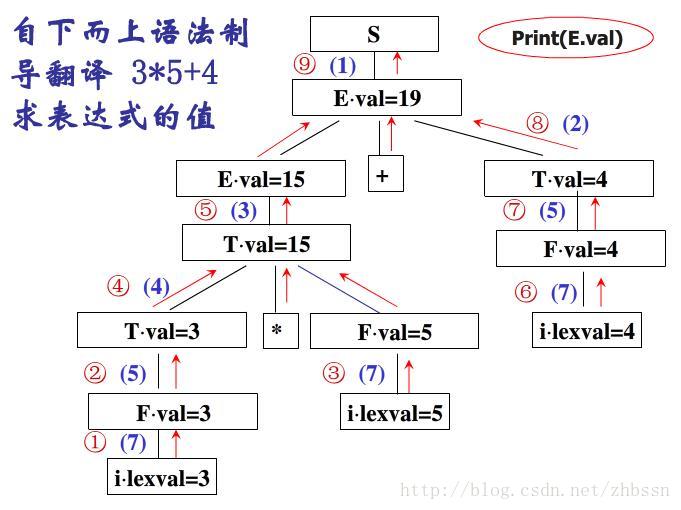
拓扑排序并不是唯一的,图5.7中1 2 3 4 5 6 7 8 9是一个拓扑排序,而1 3 5 2 4 6 7 8 9也是一个拓扑排序。
如果一棵语法分析树存在包含环的依赖图,则无法进行拓扑排序。
但是有两类SSD可以确定依赖图不存在环,因此可以进行拓扑排序进而根据这个顺序进行SSD求值。
这两类是:S属性的SSD,L属性的SSD。
4. S属性与L属性
如果一个SSD每个属性都是综合属性,则就是S型的。
如果一个SSD的属性要么是综合属性,要么是只依赖于上部父亲节点或者左部兄弟节点属性进行计算,则就是L型的。
最后上传下综合属性和继承属性的两个计算实例:
(1)综合属性计算实例
(2)继承属性计算实例

















 7824
7824

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









