










*按住ctrl + F 输入功能的关键字搜索找对应代码。如:查询,模糊查询,列约束。 *
数据类型:
整数:int,有符号范围(-2147483648 ~2147483647),无符号范围(0 ~ 4294967295)
小数:decimal,如decimal(5,2)表示共存5位数,小数占2位,整数占3位
字符串:varchar,范围(0~65533),如varchar(3)表示最多存3个字符,一个中文或一个字母都占一个字符 日期时间:
datetime,范围(1000-01-01 00:00:00 ~ 9999-12-31 23:59:59),如’2020-01-01 12:29:5约束: 主键(primary key):物理上存储的顺序 非空(not null):此字段不允许填写空值
唯一(unique):此字段的值不允许重复 默认值(default):当不填写此值时会使用默认值,如果填写时以填写为准 外键(foreign
key):维护两个表之间的关联关系(对关系字段进行约束,当为从表中的关系字段填写值时,会到关联的主表中查询此值是否存在,如果存在则填写成功,如果不存在则填写失败并报错)
函数:是由一个或多个 SQL 语句组成的子程序,可用于封装代码以便重新使用。 函数限制比较多,如不能用临时表,只能用表变量等
存储过程:存储过程是SQL 语句和可选控制流语句的预编译集合,以一个名称存储并作为一个单元处理。
数据表操作:创建、删除
创建数据表
create table 表名(
字段名 类型 约束,
字段名 类型 约束
…
)
例子:
CREATE TABLE `NewTable` (
`name` int(9) NULL ,
`age` varchar(255) NULL
);
删除数据表
格式一 :清除表格:drop table 表名
格式二 : 如果数据库中存在这个表,就把它从数据库中删掉。drop table if exists 表名
例子:
drop table students
或
drop table if exists students
数据操作:增加、删除、修改、查询
查询
select * from 表名
select * from students
查询指定字段
select 列1,列2,... from 表名
数据筛选
select 字段1,字段2… from 表名 where 条件;
select * from students where id=1;
利用比较运算符进行查询
= > >= < <= !=或<>(不等于)
查询20岁以下的学生
select * from students where age<20
利用逻辑运算符进行计算
与或非 and or not
查询年龄小于20的女同学
select * from students where age<20 and sex='女'
模糊查询
使用like比较字,加上SQL里的通配符 (通配符 主要是 _ 和 %)
%表示任意多个任意字符 _表示一个任意字符
查询姓孙的学生
select * from students where name like '孙%'
查询姓名为两个字的学生
select * from students where name like '__' (__ = _ _)
范围查询
in表示在一个非连续的范围内
between … and …表示在一个连续的范围内
查询家乡是北京或上海或广东的学生
select * from students where hometown in('北京','上海','广东')
查询年龄为18至20的学生
select * from students where age between 18 and 20
空判断
null与’'是不同的
判空is null
查询没有填写身份证的学生
select * from students where card is null
查询填写了身份证的学生
select * from students where card is not null
连接查询
等值连接
查询的结果为两个表匹配到的数据
方法一
select * from 表1,表2 where 表1.列=表2.列
select * from students,scoreds where students.studentNo = scoreds.studentNo
方法二
select * from 表1 inner join 表2 on 表1.列 = 表2.列
添加数据
添加一行数据
格式一:所有字段设置值,值的顺序与表中字段的顺序对应
说明:主键列是自动增长,插入时需要占位,通常使用0或者 default 或者 null 来占位,插入成功后以实际数据为准
insert into 表名 values(…)
插入一个学生,设置所有字段的信息
insert into students values(1,'莫迪')
格式二:部分字段设置值,值的顺序与给出的字段顺序对应
insert into 表名(字段1,…) values(值1,…)
插入一个数据,只设置姓名
insert into students(name) values('浅仓唯')
添加多行数据
方式一:写多条insert语句,语句之间用英文分号隔开(简单无脑,基本不会出错)
方式二:写一条insert语句,设置多条数据,数据之间用英文逗号隔开
insert into 表名 values(…),(…)…
插入多个学生,设置所有字段的信息
insert into students values(1,'浅仓唯1'),(2,'浅仓唯2')
格式二:insert into 表名(列1,…) values(值1,…),(值1,…)…
插入多个学生,只设置姓名
insert into students(name) values('浅仓唯'),('浅仓唯')
修改
update 表名 set 列1=值1,列2=值2… where 条件*
修改id为5的学生数据,姓名改为 狄仁杰,年龄改为 20
update students set name='狄仁杰',age=20 where id=5
删除
delete from 表名 where 条件
删除id为6的学生数据
delete from students where id=6
逻辑删除:
对于重要的数据,不能轻易执行delete语句进行删除,一旦删除,数据无法恢复,这时可以进行逻辑删除。
1、给表添加字段,代表数据是否删除,一般起名isdelete,0代表未删除,1代表删除,默认值为0
2、当要删除某条数据时,只需要设置这条数据的isdelete字段为1
3、以后在查询数据时,只查询出isdelete为0的数据
1、给学生表添加字段(isdelete),默认值为0,如果表中已经有数据,需要把所有数据的isdelete字段更新为0
update students set isdelete=0
2、删除id为1的学生
update students set isdelete=1 where id=1
3、查询未删除的数据
select * from students where isdelete=0
消除重复行
在select后面列前使用distinct可以消除重复的行
select distinct 列1,… from 表名;
select distinct sex from students
排序
将行数据按照列1进行排序,如果某些行列1的值相同时,则按照列2排序,以此类推
select * from 表名
order by 列1 asc|desc,列2 asc|desc,…
默认按照列值从小到大排列
asc从小到大排列,即升序
desc从大到小排序,即降序
查询所有学生信息,按年龄从小到大排序
select * from students order by age
查询所有学生信息,按年龄从大到小排序,年龄相同时,再按学号从小到大排序
select * from students order by age desc,studentNo
总数
查询学生总数
select count(*) from students;
最大值
select max(age) from students where sex='女';
最小值
select min(id) from students where isdelete=0;
列总和(sum)
select sum(age) from students where hometown='北京';
平均值(avg)
查询女生的平均年龄
select avg(age) from students where sex='女'
汇总
count()计数函数
count(*)包含空值,count(列名)不包含空值
select count(*),count(教师名称) from teacher;
分组
按照字段分组,表示此字段相同的数据会被放到一个组中
分组后,分组的依据列会显示在结果集中,其他列不会显示在结果集中
可以对分组后的数据进行统计,做聚合运算
select 学号,姓名,性别,年龄 from 学生表 group by 学号
select 性别,count(*) from student GROUP BY 性别;
分组后的筛选
select 课程号,avg(成绩) as 平均成绩 from score GROUP BY 课程号 having avg(成绩)>=80;
as 给数据库起别名 可以省略
select column_1 as 列1,column_2 as 列2 from text as 表;
select * from students as stu,scoreds as sc where stu.studentNo = sc.studentNo
获取部分行
当数据量过大时,在一页中查看数据是一件非常麻烦的事情
select * from 表名
limit start,count
查询前3行学生信息
select * from students limit 0,3
分页
每页显示m条数据,求:显示第n页的数据
select * from students limit (n-1)*m,m
求总页数
查询总条数p1 使用p1除以m得到p2 如果整除则p2为总数页 如果不整除则p2+1为总页数
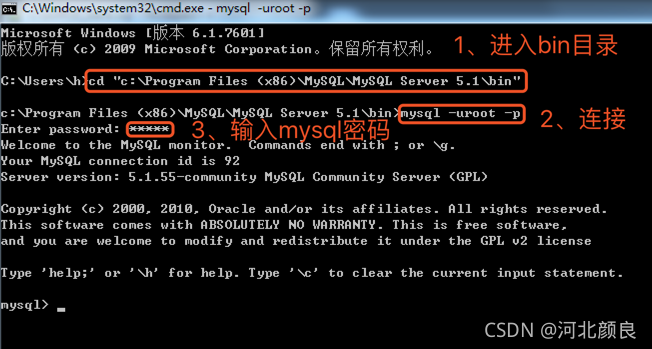
命令行客户端
连接数据库
mysql.exe -h127.0.0.1 -P3306 -uroot -p
-h host IP地址/域名 127.0.0.1/localhost 自己电脑这台服务器
-P port 端口
-u user 用户名 root 管理员用户
-p password 密码 默认是空的
连接结尾的位置不能添加分号。
简写形式 连接结尾的位置不能添加分号。
mysql -uroot -p
MySQL管理命令
quit; 退出服务器的连接
show databases; 显示当前数据库服务器下所有的数据库
use 数据库名称; 进入指定的数据库
show tables; 显示当前数据库中所有的数据表
desc 表名称; 描述表中都有哪些列
select database();查看当前使用的数据库
备份
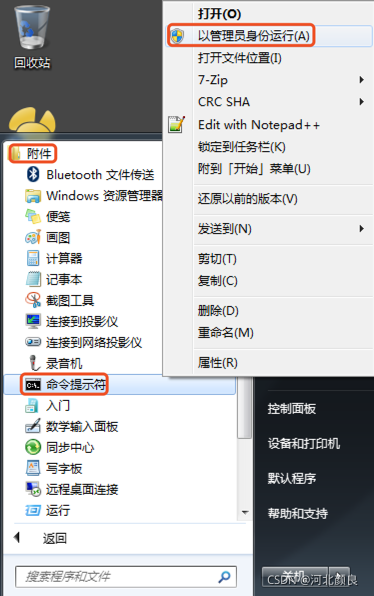
输入命令
cd C:\Program Files (x86)\MySQL\MySQL Server 5.1\bin
mysqldump –uroot –p 数据库名 > ceshi.sql
按提示输入mysql的密码
恢复
- 先创建新的数据库
2.mysql -uroot –p 新数据库名 < ceshi.sql
列约束
mysql可以对要插入的数据进行特定的验证,只有满足条件才允许插入,否则被认为非法的插入。例如编号不能出现重复,性别只能是男或者女,工资只能是正数
create table t3(
id INT 列约束
);
主键约束——PRIMARY KEY
声明了主键约束的列上不允许插入重复的值,一个表中只能有一个主键约束,通常是加在编号列,会加快数据的查询速度。
主键字段的值不能为null。
创建一个数据表
create table create_index(
id int primary key,
name varchar(10) unique,
age int,
key (age)
);
空约束——NULL
null不是数据类型,是列的一个属性。
表示当前列是否可以为null,表示什么都没有。
null, 允许为空。默认。
非空约束——NOT NULL
声明了非空约束的列上禁止插入NULL
唯一约束——UNIQUE
声明了唯一约束的列不允许出现重复的值,允许插入NULL,甚至多个NULL
可能会影响排序
两个NULL之间不能划等号
默认值约束——DEFAULT
“默认值(Default)”的完整称呼是“默认值约束(Default Constraint)”。MySQL 默认值约束用来指定某列的默认值。
(1)列级添加默认值约束
语法:create table 表名(
字段名 字段类型 default 默认值
)
(2)给已有表添加默认值约束
语法: alter table 表名 modify 字段名 字段类型 default 默认值;
(3)删除默认值约束
语法: alter table 表名 modify 字段名 字段类型 ;
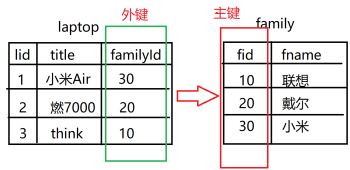
外键约束
为了建立表之间的关联,外键约束列上的值,必须得在另一个表的主键列中出现过。
外键列和对应的主键列的列类型要保持一致。
foreign key(外键列) references 另一个表(主键列)
自增列
AUTO_INCREMENT: 自动自增,插入数据的时候,不需要设置编号,只需要设置为NULL,就会获取当前的最大值然后加1插入。
自增列,如果指定值,就按照指定的来,如果没有指定值就自增。
如果指定的值是0或null,就按照自增的来。
create table t_stu(
sid int primary key auto_increment,
sname varchar(20)
);
索引
一般的应用系统对比数据库的读写比例在10:1左右,而且插入操作和更新操作很少出现性能问题,遇到最多的,也是最容易出问题的,还是一些复杂的查询操作,所以查询语句的优化显然是重中之重
当数据库中数据量很大时,查找数据会变得很慢
优化方案:索引
查看索引
show index from 表名;
创建索引
建表时创建索引
create table create_index(
id int primary key,
name varchar(10) unique,
age int,
key (age)
);
对于已经存在的表,添加索引
如果指定字段是字符串,需要指定长度,建议长度与定义字段时的长度一致
字段类型如果不是字符串,可以不填写长度部分
create index 索引名称 on 表名(字段名称(长度))
create index age_index on create_index(age);
create index name_index on create_index(name(10));
删除索引:
drop index 索引名称 on 表名;
示例:
为表title_index的title列创建索引:
create index title_index on test_index(title(10));
执行查询语句:
select * from test_index where title='test10000';
缺点:
虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE,因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件
但是,在互联网应用中,查询的语句远远大于增删改的语句,甚至可以占到80%~90%,所以也不要太在意,只是在大数据导入时,可以先删除索引,再批量插入数据,最后再添加索引
视图
查看视图:查看表会将所有的视图也列出来
show tables;
使用:视图的用途就是查询
select * from v_stu_score_course;















 1340
1340











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









