







大型语言模型(LLM)正在深刻地影响自然语言处理(NLP)领域,其强大的处理各种任务的能力也为其他领域的从业者带来了新的探索路径。推荐系统(RS)作为解决信息过载的有效手段,已经紧密融入我们的日常生活,如何用 LLM 有效重塑 RS 是一个有前景的研究问题[20, 25]。
这篇文章从生成式推荐系统和京东联盟广告的背景入手,首先引出两者结合的动因与策略,随后我们对当前的流程和方法进行了细致的回顾与整理,最后详细介绍了我们在京东联盟广告领域的应用实践。通过深入分析与案例展示,本文旨在为广告领域的推荐系统带来新的见解和启发。
一、背景
生成式推荐系统
A generative recommender system directly generates recommendations or recommendation-related content without the need to calculate each candidate’s ranking score one by one[25].
由于现实系统中的物料(item)数量巨大,传统 RS 通常采用多级过滤范式,包括召回、粗排、精排、重排等流程,首先使用一些简单而有效的方法(例如,基于规则/策略的过滤)来减少候选物料的数量,从数千万甚至数亿到数百个,然后对这些物料应用较复杂的推荐算法,以进一步选择较少数量的物料进行推荐。受限于响应时间的要求,复杂推荐算法并不适用于规模很大的所有物料。
LLM 的生成能力有可能重塑 RS,相较于传统 RS,生成式推荐系统具备如下的优势:1)简化推荐流程。LLM 可以直接生成要推荐的物料,而非计算候选集中每个物料的排名分数,实现从多级过滤范式(discriminative-based,判别式)到单级过滤范式(generative-based,生成式)的变迁。LLM 在每个解码步生成一个向量,表示在所有可能词元(token)上的概率分布。经过几个解码步,生成的 token 就可以构成代表目标物料的完整标识符,该过程隐式枚举所有候选物料以生成推荐目标物料[25]。2)具备更好的泛化性和稳定性。利用 LLM 中的世界知识和推理能力,在具有新用户和物料的冷启动和新领域场景下具备更好的推荐效果和迁移效果。同时,相比于传统 RS,生成式推荐系统的方法也更加具备稳定性和可复用性。特征处理的策略随场景和业务的变化将变小、训练数据量将变少,模型更新频率将变低。
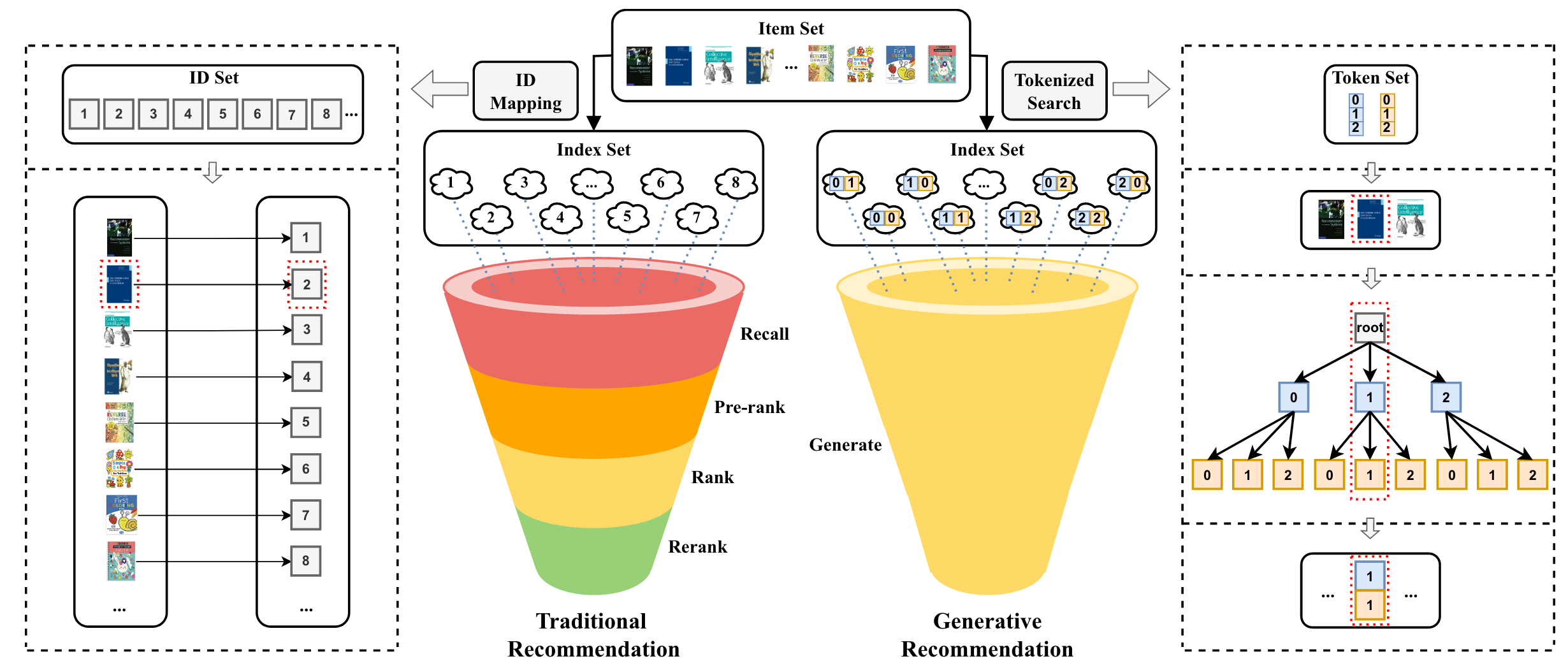
•图 1. 传统推荐系统与基于 LLM 的生成式推荐系统的流程比较[25]
京东联盟广告
京东联盟是京东的一个联盟营销平台,以投放站外 CPS 广告为主。联盟合作伙伴通过生成的链接在其他网站或社交媒体平台上推广京东商品,引导用户点击这些链接并在京东购物,从而获得销售提成(佣金)。京东联盟借此吸引流量,扩大平台的可见度和与用户的接触范围,实现拉新促活等目标。
联盟广告推荐主要针对低活跃度用户进行多场景推荐,这样的推荐面临如下的挑战:1)数据稀疏性:低活跃度用户提供的数据较少,导致更加明显的数据稀疏性问题。数据不足使得基于 ID 的传统推荐模型难以充分地对物料和用户进行表征,进而影响推荐系统的预测准确性。2)冷启动问题:对于新用户或低活跃度用户,冷启动问题尤为严重。由于缺乏足够的历史交互数据,推荐系统难以对这些用户进行有效的个性化推荐。3)场景理解困难:在多场景推荐系统中,理解不同场景下用户的具体需求尤为关键。对于低活跃度用户,由于交互数据有限,推荐系统更难以识别出用户在不同场景下的行为差异和需求变化。4)多样性和新颖性:保持推荐内容的多样性和新颖性对于吸引低活跃度用户至关重要。然而,由于对这些用户的了解有限,推荐系统难以平衡推荐的准确性与多样性。
京东联盟广告+生成式推荐系统
将 LLM 融入推荐系统的关键优势在于,它们能够提取高质量的文本表示,并利用其中编码的世界知识对用户和物料进行理解和推荐。与传统的推荐系统不同,基于 LLM 的模型擅长捕获上下文信息,更有效地理解用户信息、物料描述和其他文本数据。通过理解上下文,生成式推荐系统可以提高推荐的准确性和相关性,从而提升用户满意度。同时,面对有限的历史交互数据带来的冷启动和数据稀疏问题,LLM 还可通过零/少样本推荐能力为推荐系统带来新的可能性。这些模型可以推广到未见过的新物料和新场景,因为它们通过事实信息、领域专业知识和常识推理进行了广泛的预训练,具备较好的迁移和扩展能力。
由此可见,京东联盟广告是生成式推荐系统一个天然的应用场。
二、生成式推荐系统的四个环节
为了实现如上的范式变迁,有四个基本环节需要考虑[26]:1)物料表示:在实践中,直接生成物料(文档或商品描述)几乎是不可能的。因此,需要用短文本序列,即物料标识符,表示物料。2)模型输入表示:通过提示词定义任务,并将用户相关信息(例如,用户画像和用户历史行为数据)转换为文本序列。3)模型训练:一旦确定了生成模型的输入(用户表示)和输出(物料标识符),就可以基于 Next Token Prediction 任务实现训练。4)模型推理:训练后,生成模型可以接收用户信息来预测对应的物料标识符,并且物料标识符可以对应于数据集中的真实物料。
虽然整个过程看起来很简单,但实现有效的生成式推荐并非易事。在上述四个环节中需要考虑和平衡许多细节。下面详细梳理了现有工作在四个环节上的应用与探索:
物料表示
An identifier in recommender systems is a sequence of tokens that can uniquely identify an entity, such as a user or an item. An identifier can take various forms, such as an embedding, a sequence of numerical tokens, and a sequence of word tokens (including an item title, a description of the item, or even a complete news article), as long as it can uniquely identify the entity[25].
推荐系统中的物料通常包含来自不同模态的各种信息,例如,视频的缩略图、音乐的音频和新闻的标题。因此,物料标识符需要在文本空间中展示每个物料的复杂特征,以便进行生成式推荐。一个好的物料标识符构建方法至少应满足两
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 162
162

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









