






大家好,因为对AI大模型很感兴趣,相信很多兄弟们跟我一样,所以最近花时间了解了一些,有一些总结 分享给大家,希望对各位有所帮助;
本文主要是目标是 讲解如何在本地 搭建一个简易的AI问答系统,主要用java来实现,也有一些简单的python知识;网上很多例子都是以 ChatGPT来讲解的,但因为它对国内访问有限制,OpeAi连接太麻烦,又要虚拟账号注册账号啥的,第一步就劝退了,所以选择了 llama和qwen替代,但是原理都是一样的;
相关概念了解:
(一)大语言模型 LLM
大型语言模型(LLM,Large Language Models),是近年来自然语言处理(NLP)领域的重要进展。这些模型由于其庞大的规模和复杂性,在处理和生成自然语言方面展现了前所未有的能力。
关于LLM的一些关键点:
1.定义:
◦大模型通常指的是拥有大量参数的深度学习模型,这些模型可能包含数十亿至数万亿的参数。
◦LLM是大模型的一个子类,专门设计用于处理和理解自然语言,它们能够模仿人类语言的生成和理解过程。
2.架构:
◦LLM通常基于Transformer架构,这是一种使用自注意力机制(self-attention mechanism)的序列模型,它由多个编码器和解码器层组成,每个层包含多头自注意力机制和前馈神经网络。
3.训练:
◦这些模型在大规模文本数据集上进行训练,这使得它们能够学习到语言的复杂结构,包括语法、语义、上下文关系等。
◦训练过程通常涉及大量的计算资源,包括GPU集群和海量的数据存储。
4.应用:
◦LLM可以应用于各种自然语言处理任务,包括但不限于文本生成、问答、翻译、摘要、对话系统等。
◦它们还展示了在few-shot和zero-shot学习场景下的能力,即在少量或没有额外训练数据的情况下,模型能够理解和执行新任务。
5.发展趋势:
◦学术研究和工业界都在探索LLM的边界,包括如何更有效地训练这些模型,以及如何使它们在不同领域和任务中更具适应性。
◦开源和闭源模型的竞争也在加剧,推动了模型的持续创新和改进。
6.学习路径:
◦对于那些希望深入了解LLM的人来说,可以从学习基本的Transformer模型开始,然后逐渐深入到更复杂的模型,如GPT系列、BERT、LLaMA、Alpaca等,国内的有 qwen(通义千问)、文心一言、讯飞星火、华为盘古、言犀大模型(ChatJd)等 。
7.社区资源:
◦Hugging Face等平台提供了大量的开源模型和工具,可以帮助研究人员和开发者快速上手和应用LLM。
LLM的出现标志着NLP领域的一个新时代,它们不仅在学术研究中产生了深远的影响,也在商业应用中展现出了巨大的潜力。
(二)Embedding
在自然语言处理(NLP)和机器学习领域中,"embedding" 是一种将文本数据转换成数值向量的技术。这种技术将单词、短语、句子甚至文档映射到多维空间中的点,使得这些点在数学上能够表示它们在语义上的相似性或差异。
Embeddings 可以由预训练模型生成,也可以在特定任务中训练得到。常见的 embedding 方法包括:
1. Word2Vec:由 Google 提出,通过上下文预测目标词(CBOW)或通过目标词预测上下文(Skip-gram)来训练词向量。
2. GloVe:全球向量(Global Vectors for Word Representation),通过统计词共现矩阵来优化词向量。
3. FastText:Facebook 研究院提出的一种方法,它基于词 n-gram 来构建词向量,适用于稀少词和未见过的词。
4. BERT:基于 Transformer 架构的预训练模型,可以生成上下文相关的词嵌入,即“动态”词嵌入。
5. ELMo:利用双向 LSTM 语言模型生成的词嵌入,同样考虑了上下文信息。
6. Sentence Transformers:这是 BERT 的一种变体,专门设计用于生成句子级别的嵌入。
Embeddings 的主要优点在于它们能够捕捉词汇之间的复杂关系,如同义词、反义词以及词义的细微差别。此外,它们还能够处理多义词问题,即一个词在不同上下文中可能有不同的含义。
在实际应用中,embeddings 被广泛用于多种 NLP 任务,如文本分类、情感分析、命名实体识别、机器翻译、问答系统等。通过使用 embeddings,机器学习模型能够理解和处理自然语言数据,从而做出更加准确和有意义的预测或决策。
(三)向量数据库
向量数据库是一种专门设计用于存储和查询高维向量数据的数据库系统。这种类型的数据库在处理非结构化数据,如图像、文本、音频和视频的高效查询和相似性搜索方面表现出色。与传统的数据库管理系统(DBMS)不同,向量数据库优化了对高维空间中向量的存储、索引和检索操作。
以下是向量数据库的一些关键特点和功能:
1.高维向量存储: 向量数据库能够高效地存储和管理大量的高维向量数据,这些向量通常是由深度学习模型(如BERT、ResNet等)从原始数据中提取的特征。
2.相似性搜索: 它们提供了快速的近似最近邻(Approximate Nearest Neighbor, ANN)搜索,能够在高维空间中找到与查询向量最相似的向量集合。
3.向量索引: 使用特殊的数据结构,如树形结构(如KD树)、哈希表、图结构或量化方法,以加速向量的检索过程。
4.混合查询能力: 许多向量数据库还支持结合向量查询和结构化数据查询,这意味着除了向量相似性搜索之外,还可以进行SQL风格的查询来筛选结构化属性。
5.扩展性和容错性: 高效的数据分布和复制策略,使得向量数据库可以水平扩展,以处理海量数据,并且具备数据冗余和故障恢复能力。
6.实时更新: 允许动态添加和删除向量数据,支持实时更新,这对于不断变化的数据集尤其重要。
7.云原生设计: 许多现代向量数据库采用云原生架构,可以轻松部署在云端,利用云服务的弹性计算资源。
向量数据库在多个领域得到应用,包括推荐系统、图像和视频检索、自然语言处理(NLP)以及生物信息学。一些知名的向量数据库项目包括FAISS(由Facebook AI Research开发)、Pinecone、Weaviate、Qdrant、Milvus等。
(四)RAG
文章题目中的 "智能问答" 其实专业术语 叫 RAG;
在大模型(尤其是大型语言模型,LLMs)中,RAG 指的是“Retrieval-Augmented Generation”,即检索增强生成。这是一种结合了 检索(Retrieval)和生成(Generation)技术的人工智能方法, 主要用于增强语言模型在处理需要外部知识或实时信息的任务时的表现;
RAG 是 "Retrieval-Augmented Generation" 的缩写,即检索增强生成。这是一种结合了检索(Retrieval)和生成(Generation)两种技术的人工智能模型架构。RAG 最初由 Facebook AI 在 2020 年提出,其核心思想是在生成式模型中加入一个检索组件,以便在生成过程中利用外部知识库中的相关文档或片段。
在传统的生成模型中,如基于Transformer的模型,输出完全依赖于模型的内部知识,这通常是在大规模语料库上进行预训练得到的。然而,这些模型可能无法包含所有特定领域或最新更新的信息,尤其是在处理专业性较强或时效性较高的问题时。
RAG 架构通过从外部知识源检索相关信息来增强生成过程。当模型需要生成响应时,它会首先查询一个文档集合或知识图谱,找到与输入相关的上下文信息,然后将这些信息与原始输入一起送入生成模型,从而产生更加准确和丰富的内容。
工作原理
1.检索(Retrieval):
•当模型接收到一个输入或查询时,RAG 首先从外部知识库或数据源中检索相关信息。 这通常涉及到使用向量数据库和近似最近邻搜索算法来找到与输入最相关的文档片段或知识条目。
1.生成(Generation):
•一旦检索到相关的信息,这些信息会被整合到生成模型的输入中,作为上下文或提示(prompt)。 这样,当模型生成输出时,它就能利用这些额外的信息来提供更准确、更详细和更相关的响应。
基本流程:
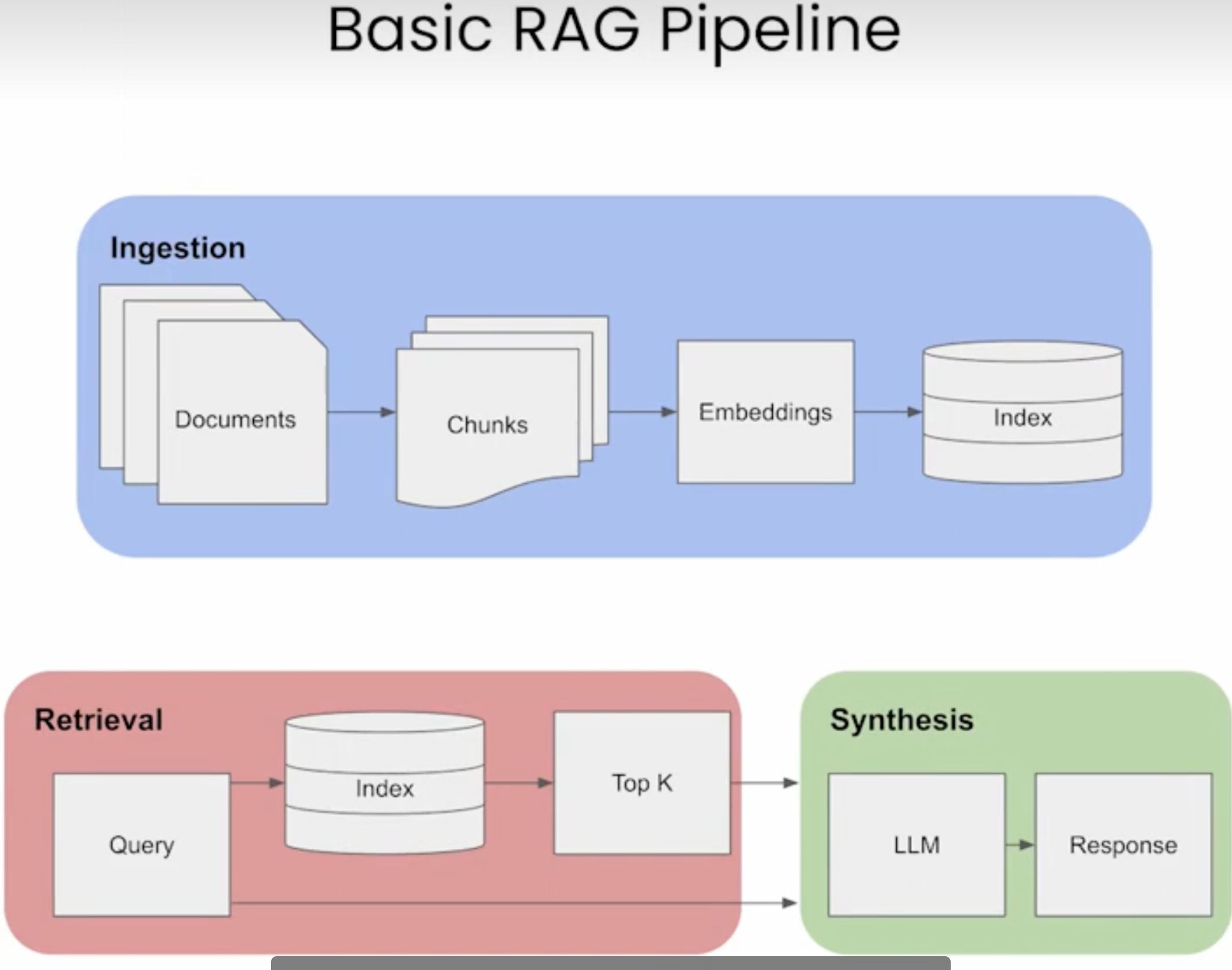
RAG的优势:
1.减少知识局限性:LLMs 通常受限于其训练数据,而 RAG 可以让模型访问实时或最新的信息,从而克服这一限制。
2.减少幻觉:幻觉是指模型生成不存在于其训练数据中的不真实信息。RAG 通过提供事实依据,可以减少这种现象。
3.提高安全性:RAG 可以通过控制检索的范围和类型,避免模型生成潜在的有害或敏感信息。
4.增强领域专业性:对于特定领域的查询,RAG 可以从专业的知识库中检索信息,从而使模型的回答更具专业性
RAG 可以应用于多种场景,包括但不限于:
•问答系统:RAG 能够检索到与问题最相关的答案片段,然后基于这些片段生成最终的回答。
•对话系统:在对话中,RAG 可以帮助模型引用历史对话或外部知识来生成更自然、更有信息量的回复。
•文档摘要:RAG 能够从大量文档中提取关键信息,生成总结或概述。
•文本补全:在文本补全任务中,RAG 可以参考相关文档来提供更准确的建议。
RAG 架构的一个重要组成部分是检索组件,它通常使用向量相似度搜索技术,如倒排索引或基于神经网络的嵌入空间搜索。这使得模型能够在大规模文档集合中快速找到最相关的部分。
AI 应用开发框架
(一)Langchain
官网:LangChain
LangChain不是一个大数据模型,而是一款可以用于开发类似AutoGPT的AI应用的开发工具,LangChain简化了LLM应用程序生命周期的各个阶段,且提供了 开发协议、开发范式,并 拥有相应的平台和生态;
LangChain 是一个由 Harrison Chase 创立的框架,专注于帮助开发者使用语言模型构建端到端的应用程序。它特别设计来简化与大型语言模型(LLMs)的集成,使得创建由这些模型支持的应用程序变得更加容易。LangChain 提供了一系列工具、组件和接口,可以用于构建聊天机器人、生成式问答系统、摘要工具以及其他基于语言的AI应用。
LangChain 的核心特性包括:
1.链式思维(Chains): LangChain 引入了“链”(Chain)的概念,这是一系列可组合的操作,可以按顺序执行,比如从获取输入、处理数据到生成输出。链条可以嵌套和组合,形成复杂的逻辑流。
2.代理(Agents): 代理是更高级别的抽象,它们可以自主地决定如何使用不同的链条来完成任务。代理可以根据输入动态选择最佳行动方案。
3.记忆(Memory): LangChain 支持不同类型的内存,允许模型保留历史对话或操作的上下文,这对于构建有状态的对话系统至关重要。
4.加载器和拆分器(Loaders and Splitters): 这些工具帮助读取和处理各种格式的文档,如PDF、网页、文本文件等,为模型提供输入数据。
5.提示工程(Prompt Engineering): LangChain 提供了创建和管理提示模板的工具,帮助引导模型生成特定类型的内容。
6.Hub: LangChain Hub 是一个社区驱动的资源库,其中包含了许多预构建的链条、代理和提示,可以作为构建块来加速开发过程。
7.与外部系统的集成: LangChain 支持与外部数据源和API的集成,如数据库查询、知识图谱、搜索引擎等,以便模型能够访问更广泛的信息。
8.监控和调试工具: 为了更好地理解和优化应用程序,LangChain 提供了日志记录和分析功能,帮助开发者追踪模型的行为和性能。
(二)LangChain4J
上面说的 LangChain 是基于python 开发的,而 LangChain4J 是一个旨在为 Java 开发者提供构建语言模型应用的框架。受到 Python 社区中 LangChain 库的启发,LangChain4J 致力于提供相似的功能,但针对 Java 生态系统进行了优化。它允许开发者轻松地构建、部署和维护基于大型语言模型的应用程序,如聊天机器人、文本生成器和其他自然语言处理(NLP)任务。
主要特点:
1.模块化设计:LangChain4J 提供了一系列可组合的模块,包括语言模型、记忆、工具和链,使得开发者可以构建复杂的语言处理流水线。
2.支持多种语言模型:LangChain4J 支持与各种语言模型提供商集成,如 Hugging Face、OpenAI、Google PaLM 等,使得开发者可以根据项目需求选择最合适的模型。
3.记忆机制:它提供了记忆组件,允许模型记住先前的对话历史,从而支持上下文感知的对话。
4.工具集成:LangChain4J 支持集成外部工具,如搜索API、数据库查询等,使得模型能够访问实时数据或执行特定任务。
5.链式执行:通过链式执行,可以将多个语言处理步骤链接在一起,形成复杂的处理流程,例如先分析用户意图,再查询数据库,最后生成回复。
主要功能:
1.LLM 适配器:允许你连接到各种语言模型,如 OpenAI 的 GPT-3 和 GPT-4,Anthropic 的 Claude 等。
2.Chains 构建:提供一种机制来定义和执行一系列操作,这些操作可以包括调用模型、数据检索、转换等,以完成特定的任务。
3.Agent 实现:支持创建代理(agents),它们可以自主地执行任务,如回答问题、完成指令等。
4.Prompt 模板:提供模板化的提示,帮助指导模型生成更具体和有用的回答。
5.工具和记忆:允许模型访问外部数据源或存储之前的交互记录,以便在会话中保持上下文。
6.模块化和可扩展性:使开发者能够扩展框架,添加自己的组件和功能。
本地问答系统搭建环境准备
(一)用 Ollama 启动一个本地大模型
1.下载安装 Ollma
2.ollama 是一个命令行工具,用于方便地在本地运行 LLaMA 系列模型和其他类似的 transformer 基础的大型语言模型。该工具简化了模型的下载、配置和推理过程,使得个人用户能够在自己的机器上直接与这些模型交互,而不需要直接接触复杂的模型加载和推理代码;
3.下载地址:https://ollama.com/,下载完成后,打开 Ollma,其默认端口为11334,浏览器访问:http://localhost:11434 ,会返回:Ollama is running,电脑右上角展示图标;

1.下载 大模型
2.安装完成后,通过命令行下载大模型,命令行格式:ollma pull modelName,如:ollma pull llama3;
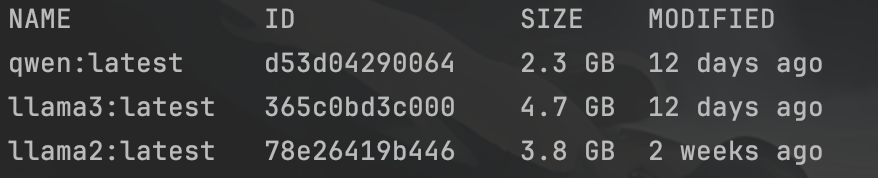
3.大模型一般要几个G,需要等一会;个人建议至少下载两个, llama3、 qwen(通义千问),这两个都是开源免费的,英文场景 用 llama3,中文场景用 qwen;
下载完成后,通过 ollma list 可以查看 已下载的大模型;
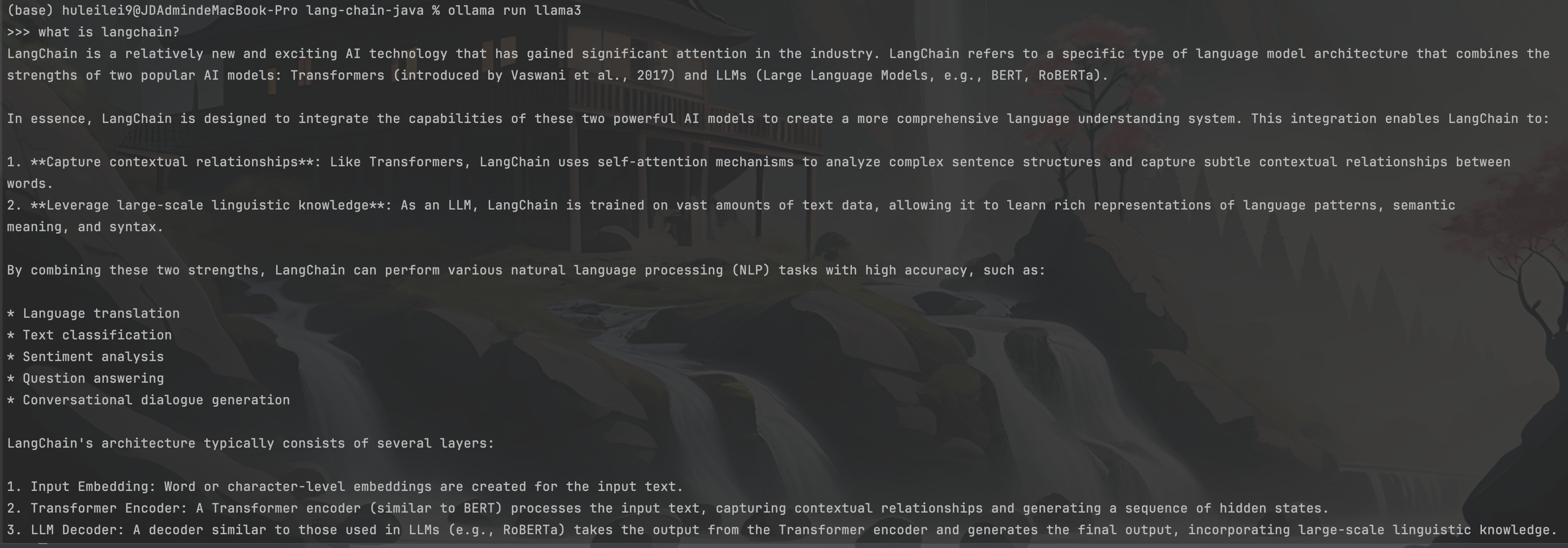
1.启动 大模型
确认下载完成后,用命令行 :ollma run 模型名称,来启动大模型;启动后,可以立即输入内容与大模型进行对话,如下:
(二)启动 本地向量数据库 chromadb
Chroma 是一款 AI 原生开源矢量数据库,它内置了入门所需的一切,可在本地运行,是一款很好的入门级向量数据库。
1.安装:pip install chromadb ;
2.启动:chroma run :
用java 实现 本地AI问答功能
(一)核心maven依赖:
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<langchain4j.version>0.31.0</langchain4j.version>
</properties>
<dependencies>
<!-- langchain4j -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-core</artifactId>
<version>${langchain4j.version}</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
<version>${langchain4j.version}</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai</artifactId>
<version>${langchain4j.version}</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-embeddings</artifactId>
<version>${langchain4j.version}</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-chroma</artifactId>
<version>${langchain4j.version}</version>
</dependency>
<!-- ollama -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-ollama</artifactId>
<version>${langchain4j.version}</version>
</dependency>
<!-- chroma 向量数据库 -->
<dependency>
<groupId>io.github.amikos-tech</groupId>
<artifactId>chromadb-java-client</artifactId>
<version>0.1.5</version>
</dependency>
</dependencies>
(二)代码编写:
1. 加载本地文件作为本地知识库:
public static void main(String[] args) throws ApiException {
//======================= 加载文件=======================
Document document = getDocument("笑话.txt");
}
private static Document getDocument(String fileName) {
URL docUrl = LangChainMainTest.class.getClassLoader().getResource(fileName);
if (docUrl == null) {
log.error("未获取到文件");
}
Document document = null;
try {
Path path = Paths.get(docUrl.toURI());
document = FileSystemDocumentLoader.loadDocument(path);
} catch (URISyntaxException e) {
log.error("加载文件发生异常", e);
}
return document;
}
1.拆分文件内容:
//======================= 拆分文件内容=======================
//参数:分段大小(一个分段中最大包含多少个token)、重叠度(段与段之前重叠的token数)、分词器(将一段文本进行分词,得到token)
DocumentByLineSplitter lineSplitter = new DocumentByLineSplitter(200, 0, new OpenAiTokenizer());
List<TextSegment> segments = lineSplitter.split(document);
log.info("segment的数量是: {}", segments.size());
//查看分段后的信息
segments.forEach(segment -> log.info("========================segment: {}", segment.text()));
1.文本向量化 并存储到向量数据库:
//提前定义两个静态变量
private static final String CHROMA_DB_DEFAULT_COLLECTION_NAME = "java-langChain-database-demo";
private static final String CHROMA_URL = "http://localhost:8000";
//======================= 文本向量化=======================
OllamaEmbeddingModel embeddingModel = OllamaEmbeddingModel.builder()
.baseUrl("http://localhost:11434")
.modelName("llama3")
.build();
//======================= 向量库存储=======================
Client client = new Client(CHROMA_URL);
//创建向量数据库
EmbeddingStore<TextSegment> embeddingStore = ChromaEmbeddingStore.builder()
.baseUrl(CHROMA_URL)
.collectionName(CHROMA_DB_DEFAULT_COLLECTION_NAME)
.build();
segments.forEach(segment -> {
Embedding e = embeddingModel.embed(segment).content();
embeddingStore.add(e, segment);
});
1.向量库检索:
//======================= 向量库检索=======================
String qryText = "北极熊";
Embedding queryEmbedding = embeddingModel.embed(qryText).content();
EmbeddingSearchRequest embeddingSearchRequest = EmbeddingSearchRequest.builder().queryEmbedding(queryEmbedding).maxResults(1).build();
EmbeddingSearchResult<TextSegment> embeddedEmbeddingSearchResult = embeddingStore.search(embeddingSearchRequest);
List<EmbeddingMatch<TextSegment>> embeddingMatcheList = embeddedEmbeddingSearchResult.matches();
EmbeddingMatch<TextSegment> embeddingMatch = embeddingMatcheList.get(0);
TextSegment textSegment = embeddingMatch.embedded();
log.info("查询结果: {}", textSegment.text());
1.与LLM交互
//======================= 与LLM交互=======================
PromptTemplate promptTemplate = PromptTemplate.from("基于如下信息用中文回答:\n" +
"{{context}}\n" +
"提问:\n" +
"{{question}}");
Map<String, Object> variables = new HashMap<>();
//以向量库检索到的结果作为LLM的信息输入
variables.put("context", textSegment.text());
variables.put("question", "北极熊干了什么");
Prompt prompt = promptTemplate.apply(variables);
//连接大模型
OllamaChatModel ollamaChatModel = OllamaChatModel.builder()
.baseUrl("http://localhost:11434")
.modelName("llama3")
.build();
UserMessage userMessage = prompt.toUserMessage();
Response<AiMessage> aiMessageResponse = ollamaChatModel.generate(userMessage);
AiMessage response = aiMessageResponse.content();
log.info("大模型回答: {}", response.text());
(三)功能测试:
1.代码中用到 "笑话.txt" 是我随便从网上找的一段内容,大家可以随便输入点内容,为了给大家展示测试结果,我贴一下我 文本内容:
有一只北极熊和一只企鹅在一起耍,
企鹅把身上的毛一根一根地拔了下来,拔完之后,对北极熊说:“好冷哦!”
北极熊听了,也把自己身上的毛一根一根地拔了下来,
转头对企鹅说:
”果然很冷!”
1.当我输入问题:“北极熊干了什么”,程序打印如下结果:
根据故事,北极熊把自己的身上的毛一根一根地拔了下来
结语
1.以上便是 完成了一个超简易的AI问答 功能,如果想搭一个问答系统,可以用Springboot搞一个Web应用,把上面的代码放到 业务逻辑中即可;
2.langchain 还有其他很多很强大的能力,prompt Fomat、output Fomat、工具调用、memory存储等;
3.早点认识和学习ai,不至于被它取代的时候,连对手是谁都不知道;
















 769
769

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









