







DOM:Document Object Model(文档对象模型)
用来将标记型文档封装成对象,并将标记型文档中的所有的内容(标签,文本,属必等)都封装成对象。
封装成对象的目的是为了更方便的操作这些文档以及当档中的所有内容
因为对象的出现就可以有属性和行为被调用。
文档对象模型
文档:标记型文档(html,xml)
对象:封装了属性和行为的实例,可以被直接调用。
模型:所有标记型文档都具有一些共性特征的一个体现。
标记型文档(标签,属性,标签中封装的数据)
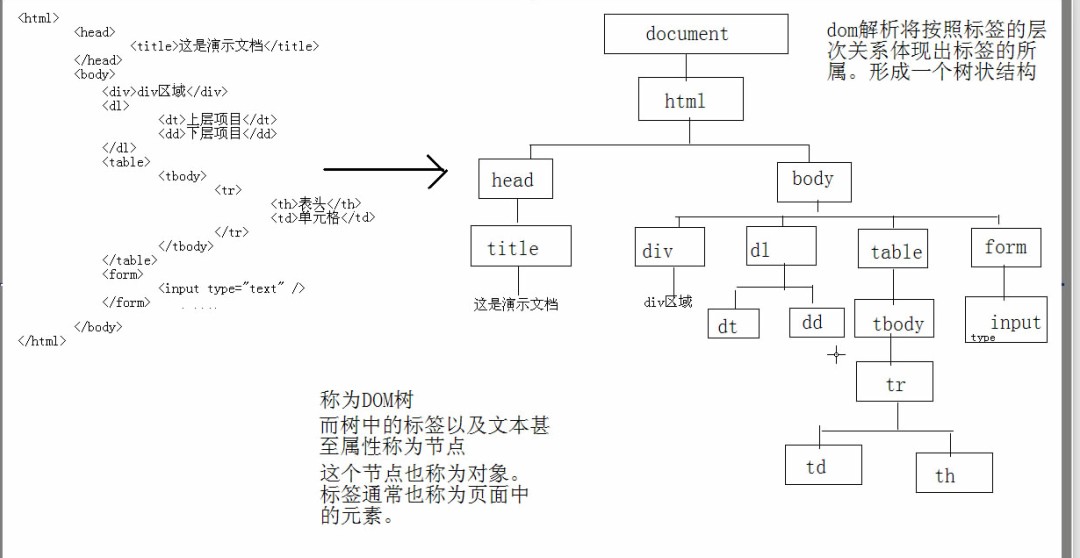
DOM是如何对标记型文档进行打操作的呢?
要操作标记型文档必须对其进行解析
解析方式:将标记型文档解析一棵树,并将树中的内容都封装成节点对象
好处:可以对树中的节点进行任意操作,比如:增删改查
弊端:这种解析需要将整个标记型文档加载进内存,意味着如果标记型文档的体积很大,较为浪费内存空间。
SAX解析方式,不是w3c标准,DOM是w3c的标准。它是基于事件驱动的解析,获取数据的速度很快,但是不能
对标记进行增删改。
DOM模型有三种:
DOM level 1:将html文档封装成对象。
DOM level 2:在level 1基础上加入了新功能,比如解析名称空间。
用来将标记型文档封装成对象,并将标记型文档中的所有的内容(标签,文本,属必等)都封装成对象。
封装成对象的目的是为了更方便的操作这些文档以及当档中的所有内容
因为对象的出现就可以有属性和行为被调用。
文档对象模型
文档:标记型文档(html,xml)
对象:封装了属性和行为的实例,可以被直接调用。
模型:所有标记型文档都具有一些共性特征的一个体现。
标记型文档(标签,属性,标签中封装的数据)
DOM是如何对标记型文档进行打操作的呢?
要操作标记型文档必须对其进行解析
解析方式:将标记型文档解析一棵树,并将树中的内容都封装成节点对象
好处:可以对树中的节点进行任意操作,比如:增删改查
弊端:这种解析需要将整个标记型文档加载进内存,意味着如果标记型文档的体积很大,较为浪费内存空间。
SAX解析方式,不是w3c标准,DOM是w3c的标准。它是基于事件驱动的解析,获取数据的速度很快,但是不能
对标记进行增删改。
DOM模型有三种:
DOM level 1:将html文档封装成对象。
DOM level 2:在level 1基础上加入了新功能,比如解析名称空间。
DOM level 3:将xml文档封装成了对象















 1107
1107











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









