






计算机只能运行本地代码
用某种编程语言编写的程序就称为 源代码,保存源代码的文件称为 源文件。
因为源文件是简单的文本文件,所以用Windows 自带的记事本等文本编辑器就可以编写。
源代码是无法直接运行的。这是因为,CPU 能直接解析并运行的不是源代码而是本地代码的程序。作为计算机大脑的Pentium 等CPU,也只能解释已经转换成本地代码的程序内容。
本地(native)这个术语有“母语的”意思。对CPU 来说,母语就是机器语言,而转换成机器语言的程序就是本地代码。用任何编程语言编写的源代码,最后都要翻译成本地代码,否则CPU 就不能理解。也就是说,即使是用不同编程语言编写的代码,转换成本地代码后,也都变成用同一种语言(机器语言)来表示了。
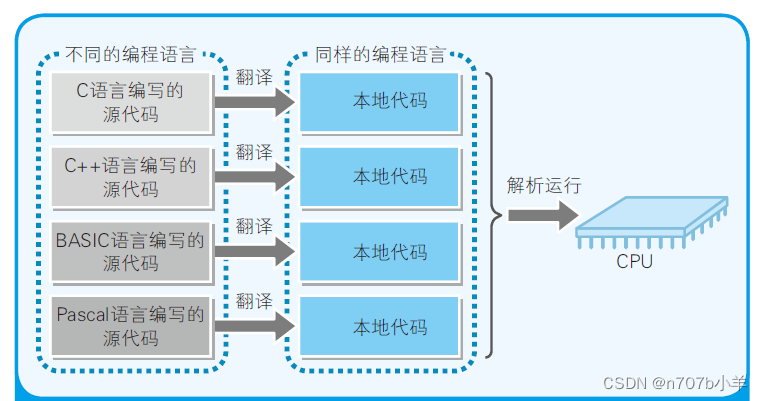
本地代码的内容
Windows 中EXE 文件的程序内容,使用的就是本地代码。
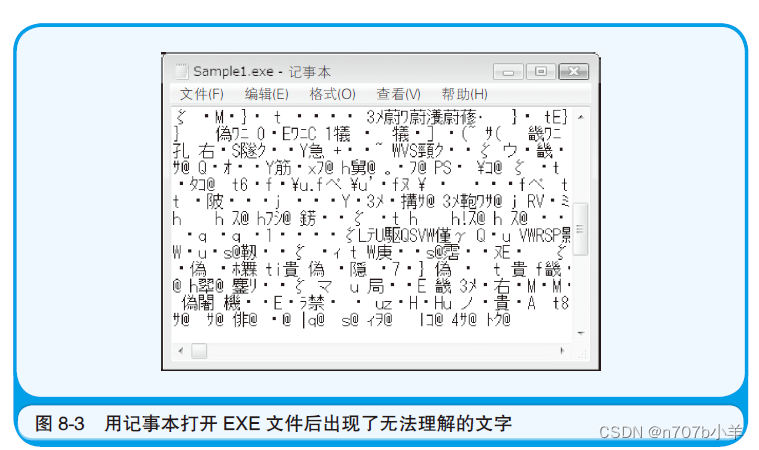
用记事本打开由源代码转换成本地代码得到的EXE文件,页面显示情况如图所示。据此我们应该可以看出,本地代码的内容是人类无法理解的。也正是因为如此,才有了用人类容易理解的C 语言等编程语言来编写源代码,然后再将源代码转换成本地代码这一方法。
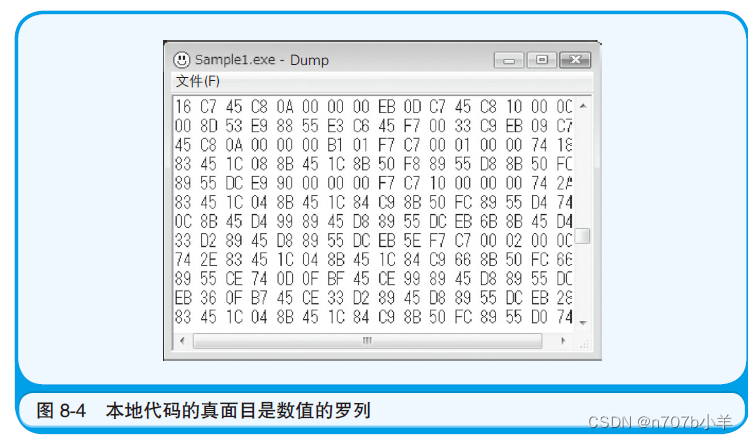
接下来,我们把刚才的EXE 文件的内容Dump 一下。 Dump是指把文件的内容,每个字节用2 位十六进制数来表示的方式。本地代码的内容就是各种数值的罗列,这一点想必大家都了解。而这些数值就是本地代码的真面目。每个数值都表示某一个命令或数据。这里我们用的是原始的Dump 程序。
而计算机就是把所有的信息作为数值的集合来处理的。例如,A这个字符数据就是用十六进制数41 来表示的。与此相同,计算机指令也是数值的罗列。这就是本地代码。
编译器负责转换源代码
能够把C 语言等高级编程语言编写的源代码转换成本地代码的程序称为 编译器。每个编写源代码的编程语言都需要其专用的编译器。将C 语言编写的源代码转换成本地代码的编译器称为C 编译器。编译器首先读入代码的内容,然后再把源代码转换成本地代码。编译器中就好像有一个源代码同本地代码的对应表。但实际上,仅仅靠对应表是无法生成本地代码的。读入的源代码还要经过语法解析、句法解析、语义解析等,才能生成本地代码。
根据CPU 类型的不同,本地代码的类型也不同。因而,编译器不仅和编程语言的种类有关,和CPU 的类型也是相关的。例如,Pentium等x86 系列CPU 用的C 编译器,同PowerPC 这种CPU 用的C 编译器就不同。从另一个方面来看,这其实是非常方便的。因为这样一来,同样的源代码就可以翻译成适用于不同CPU 的本地代码了。
因为编译器本身也是程序的一种,所以也需要运行环境。例如,有Windows 用的C 编译器、Linux 用的C 编译器等。此外,还有一种交叉编译器,它生成的是和运行环境中的CPU 不同的CPU 所使用的本地代码。现在编译器基本上不需要购买,都已经默认集成到开发IDE 中了。
仅靠编译是无法得到可执行文件的,启动及库文件
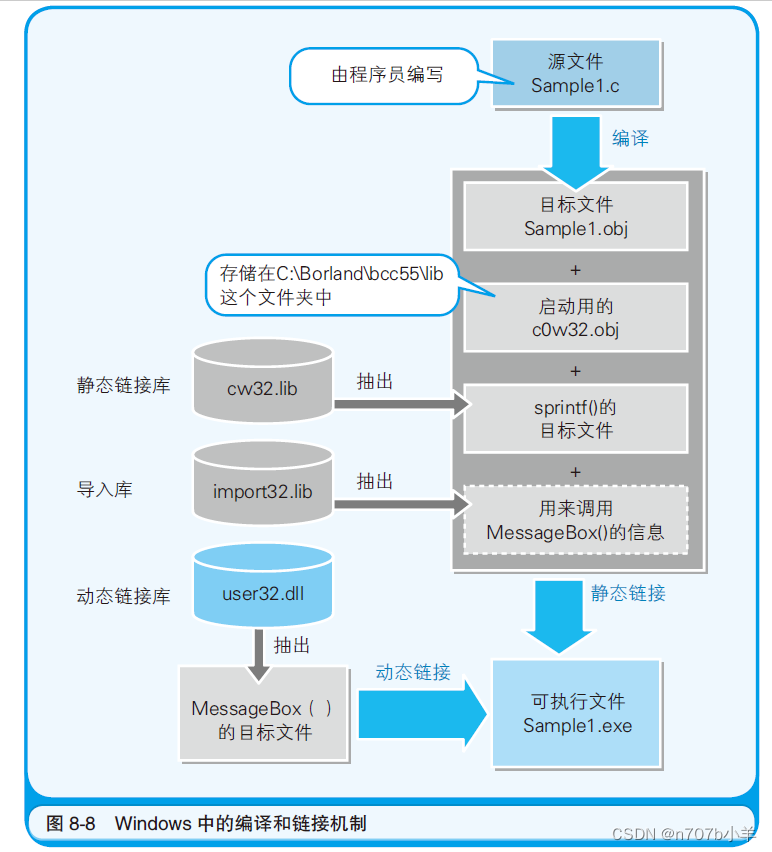
编译器转换源代码后,就会生成本地文件。不过,本地文件是无法直接运行的。为了得到可以运行的EXE 文件,编译之后还需要进行“链接”处理。
下面,就让我们使用Borland C++ Compiler5.5(以下称为Borland C++)来看一下编译和链接是如何进行的。
Borland C++ 的编译器是bcc32.exe 这个命令行工具。命令行工具指的是在Windows 的命令提示符下使用的CUI 程序。在Windows的命令提示符中,运行下列命令后, 由C 语言编写的源文件Smaple1.c就会被编译。
bcc32 -W -c Sample1.c
“-W-c”是用来指定编译Windows 用的程序的选项。 选项是对编译器的指示。有时也称为“开关”。
编译后生成的不是EXE 文件,而是扩展名为“.obj”的 目标文件。Sample1.c 编译后,就生成了Sample1.obj 目标文件。
目标文件(object file)中的object 一词,指的是编译器生成结果的意思。和面向对象编程(object oriented programming)的object 没有任何关系。面向对象编程的对象指的是数据和处理的集合体。
虽然目标文件的内容是本地代码,但却无法直接运行。那么这是为什么呢?原因就是当前程序还处于未完成状态。
不过源代码中都没有记述这些函数的处理内容。因此,这时就必须将存储着如sprintf() 和MessageBox() 的处理内容的目标文件同Sample1.obj 结合,否则处理就不完整,EXE 文件也就无法完成。
把多个目标文件结合,生成1 个EXE 文件的处理就是 链接,运行连接的程序就称为 链接器(linkage editor 或连结器)。Borland C++ 的链接器就是ilink32.exe 的命令行工具。在Windows 命令提示符下运行以下命令后,程序所需的目标文件就会被全部链接生成Sample1.exe 这个EXE 文件。
ilink32 -Tpe -c -x -aa c0w32.obj Sample1.obj, Sample1.exe,,
import32.lib cw32.lib
链接选项“-Tpe-c-x-aa”是指定生成Windows 用的EXE 文件的选项。在这些选项之后,会指定结合的目标文件。而该命令行中就指定了c0w32.obj、Sample1.obj 这两个目标文件,这点相信大家都能看得出来。Sample1.obj 是Sample1.c 编译后得到的目标文件。c0w32.obj 这个目标文件记述的是同所有程序起始位置相结合的处理内容,称为程序的 启动。
因而,即使程序不调用其他目标文件的函数,也必须要进行链接,并和启动结合起来。c0w32.obj 是由Borland C++ 提供的。如果C盘中安装有Borland C++ 的话,文件夹C:\Borland\bcc55\lib 中就会有c0w32.obj 这个文件。
那么,大家可能会有这样一个疑问:“链接时不指定sprintf() 和MessageBox() 的目标文件也没问题么?”这个担心是多余的。在链接的命令行末尾,存在着扩展名是“.lib”的import32.lib 和cw32.lib 这两个文件。这是因为sprintf() 的目标文件在cw32.lib 中,MessageBox() 的目标文件在import32.lib 中(实际上,MessageBox() 的目标文件在user32.dll 这个DLL 文件中。关于这一点,我们会在后面进行说明)。
像import32.lib 及cw32.lib 这样的文件称为库文件。 库文件指的是把多个目标文件集成保存到一个文件中的形式。链接器指定库文件后,就会从中把需要的目标文件抽取出来,并同其他目标文件结合生成EXE 文件。
Sample1.obj 是尚未完成的本地代码,这个在前面已经进行了说明。这是因为,Sample1.obj 文件中包含有“链接时请结合sprintf() 及MessageBox()”这样的信息。意思是如果不存在其他函数的话,程序就无法运行。
之所以使用库文件,是为了简化为链接器的参数指定多个目标文件这一过程。例如,在链接调用了数百个标准函数的程序时,就要在链接器的命令行中指定数百个目标文件,这样就太繁琐了。而利用存储着多个目标文件的库文件的话,则只需在链接器的命令行中指定几个库文件就可以了。
通过以目标文件的形式或集合多个目标文件的库文件形式来提供函数,就可以不用公开标准函数的源代码内容。由于标准函数的源代码是编译器厂商的贵重财产,因此若被其他公司任意转用的话,可能会造成一些损失。
DLL 文件及导入库
Windows 以函数的形式为应用提供了各种功能。这些形式的函数称为 API(Application Programming Interface,应用程序接口)。例如,Sample1.c 中调用的MessageBox(),它并不是C 语言的标准函数,而是Windows 提供的API 的一种。MessageBox() 提供了显示消息框的功能。
Windows 中,API 的目标文件,并不是存储在通常的库文件中,而是存储在名为 DLL(Dynamic Link Library) 文件的特殊库文件中。就如Dynamic 这一名称所表示的那样,DLL 文件是程序运行时动态结合的文件。
在前面的介绍中,我们提到MessageBox() 的目标文件是存储在import32.lib 中的。实际上,import32.lib 中仅仅存储着两个信息,一是MessageBox() 在user32.dll 这个DLL 文件中,另一个是存储着DLL 文件的文件夹信息,MessageBox() 的目标文件的实体实际上并不存在。我们把类似于import32.lib 这样的库文件称为导入库。
与此相反,存储着目标文件的实体,并直接和EXE 文件结合的库文件形式称为 静态链接库。静态(static = 静态的)同动态(dynamic =动态的)是相反的意思。存储着sprintf() 的目标文件的cw32lib 就是静态链接库。sprintf() 提供了通过指定格式把数值转换成字符串的功能。
通过结合导入库文件,执行时从DLL 文件中调出的MessageBox()函数这一信息就会和EXE 文件进行结合。这样,链接器链接时就不会再出现错误消息,从而就可以顺利编写EXE 文件。
至此,我们总结一下Windows 中的编译及链接机制
可执行文件运行时的必要条件
在了解了通过程序的编译及链接来生成EXE 文件的机制后,接下来看一下EXE 文件的运行机制。EXE 文件是作为单独的文件储存在硬盘中的。通过资源管理器找到并双击EXE 文件,就会把EXE 文件的内容加载到内存中运行。
请大家思考一下下面的问题。本地代码在对程序中记述的变量进行读写时,是参照数据存储的内存地址来运行命令的。在调用函数时,程序的处理流程就会跳转到存储着函数处理内容的内存地址上。EXE文件作为本地代码的程序,并没有指定变量及函数的实际内存地址。在类似于Windows 操作系统这样的可以加载多个可执行程序的运行环境中,每次运行时,程序内的变量及函数被分配到的内存地址都是不同的。那么,在EXE 文件中,变量和函数的内存地址的值,是如何来表示的呢?
下面就让我们来揭晓答案。那就是EXE 文件中给变量及函数分配了虚拟的内存地址。在程序运行时,虚拟的内存地址会转换成实际的内存地址。链接器会在EXE 文件的开头,追加转换内存地址所需的必要信息。这个信息称为 再配置信息。
EXE 文件的再配置信息,就成为了变量和函数的相对地址。相对地址表示的是相对于基点地址的偏移量,也就是相对距离。实现相对地址,也是需要花费一番心思的。在源代码中,虽然变量及函数是在不同位置分散记述的,但在链接后的EXE 文件中,变量及函数就会变成一个连续排列的组。这样一来,各变量的内存地址就可以用相对于变量组起始位置这一基点的偏移量来表示,同样,各函数的内存地址也可以用相对于函数组起始位置这一基点的偏移量来表示。而各组基点的内存地址则是在程序运行时被分配的。
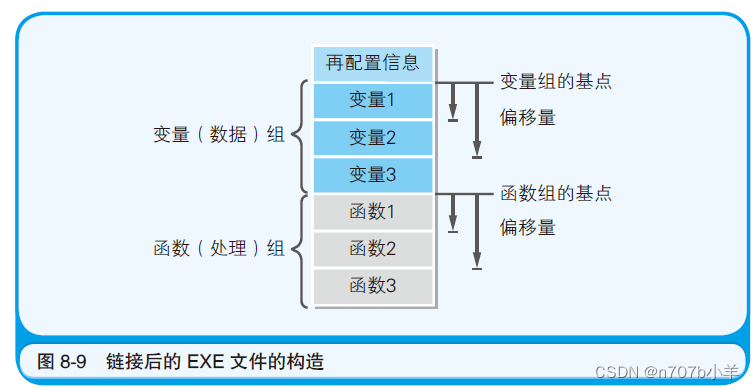
程序加载时会生成栈和堆
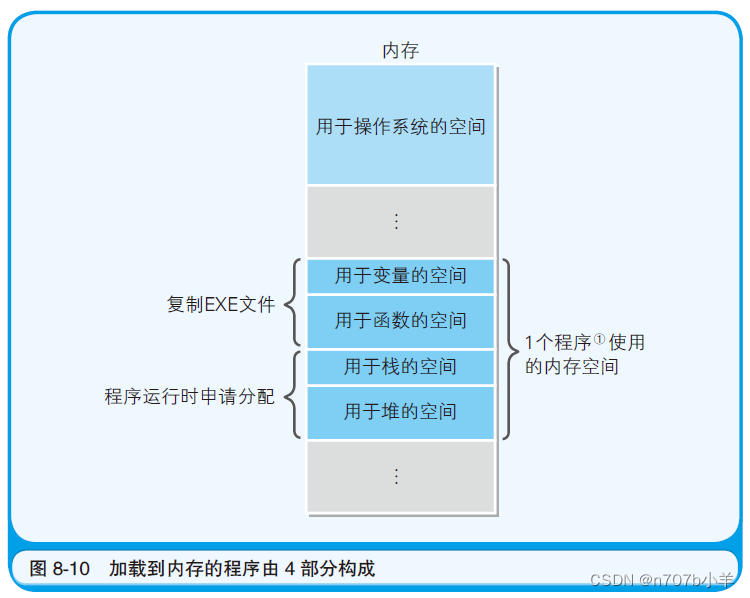
EXE 文件的内容分为再配置信息、变量组和函数组,这一点想必大家都清楚了吧。不过,当程序加载到内存后,除此之外还会额外生成两个组,那就是栈和堆。 栈是用来存储函数内部临时使用的变量(局部变量),以及函数调用时所用的参数的内存区域。 堆是用来存储程序运行时的任意数据及对象的内存领域。
EXE 文件中并不存在栈及堆的组。栈和堆需要的内存空间是在EXE 文件加载到内存后开始运行时得到分配的。因而,内存中的程序,就是由用于变量的内存空间、用于函数的内存空间、用于栈的内存空间、用于堆的内存空间这4 部分构成的。当然, 在内存中, 加载Windows 等操作系统的内存空间又是另外一回事了。
栈及堆的相似之处在于,他们的内存空间都是在程序运行时得到申请分配的。不过,在内存的使用方法上,二者存在些许不同。栈中对数据进行存储和舍弃(清理处理)的代码,是由编译器自动生成的,因此不需要程序员的参与。使用栈的数据的内存空间,每当函数被调用时都会得到申请分配,并在函数处理完毕后自动释放。与此相对,堆的内存空间,则要根据程序员编写的程序,来明确进行申请分配或释放。
根据编程语言的不同,对堆用的内存空间进行申请分配和释放的程序的编写方法也是多种多样的。C 语言中是通过malloc() 函数来进行申请分配、通过free() 函数来释放的。而C++ 中则是通过new 运算符来申请分配、通过delete 运算符来释放的。
无论是C 语言还是C++,如果没有在程序中明确释放堆的内存空间,那么即使在处理完毕后,该内存空间仍会一直残留。这个现象称为 内存泄露(memory leak),它是令C 语言及C++ 的程序员们十分头疼的一个bug(程序的错误)。如果内存泄露一直存在的话,就有可能会造成内存不足而导致宕机。这就好比,如果水龙头一直嘀嗒嘀嗒地漏水,那么一晚上的时间水桶就可能会装满并溢出。
有点难度的Q&A
Q :编译器和解释器有什么不同?
A :编译器是在运行前对所有源代码进行解释处理的。而解释器则是在运行时对源代码的内容一行一行地进行解释处理的。
Q :“分割编译”指的是什么?
A :将整个程序分为多个源代码来编写,然后分别进行编译,最后链接成一个EXE 文件。这样每个源代码都相对变短,便于程序管理。
Q :“Build”指的是什么?
A :根据开发工具种类的不同,有的编译器可以通过选择“Build”菜单来生成EXE 文件。这种情况下,Build 指的是连续执行编译和链接。
Q :使用DLL 文件的好处是什么?
A :DLL 文件中的函数可以被多个程序共用。因此,借助该功能可以节约内存和磁盘。此外,在对函数的内容进行修正时,还不需要重新链接(静态链接)使用这个函数的程序。
Q :不链接导入库的话就无法调用DLL 文件中的函数吗?
A :通过使用LoadLibrary() 及GetProcAddress() 这些API,即使不链接导入库,也可以在程序运行时调用DLL 文件中的函数。不过使用导入库更简单一些。
Q :“叠加链接”这个术语指的是什么?
A :将不会同时执行的函数,交替加载到同一个地址中运行。通过使用“叠加链接器”这一特殊的链接器即可实现。在计算机中配置的内存容量不多的MS-DOS 时代,经常使用叠加链接。
Q :和内存管理相关的“垃圾回收机制”指的是什么呢?
A :垃圾回收机制(garbage collection)指的是对处理完毕后不再需要的堆内存空间的数据和对象进行清理,释放它们所使用的内存空间。这里把不需要的数据比喻为了垃圾。进行该处理时,C 语言用的是free() 函数,C++ 用的是delete 运算符。在C++ 的基础上开发出来的Java 及C# 这些编程语言中,程序运行环境会自动进行垃圾回收。这样就可以避免由于程序员的疏忽(忘了记述内存的释放处理)而造成内存泄露了。















 774
774











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









