







NSGA2主要是对NSGA算法的改进。NSGA是N. Srinivas 和 K. Deb在1995年发表的一篇名为《Multiobjective function optimization using nondominated sorting genetic algorithms》的论文中提出的。该算法在快速找到Pareto前沿和保持种群多样性方面都有很好的效果,不过在这么多年的应用中也出现了如下的一些问题:
- 非支配排序的时间复杂的很大,为 O(MN2) 。其中M为目标函数的数量,N为种群数量。
- 缺少精英机制。
- 需要自己指定共享参数。该参数将对种群的多样性产生很大的影响。
NSGA2算法将在以下方面进行改进:
1. 快速的非支配排序
在NSGA进行非支配排序时,规模为
N
的种群中的每个个体都要针对
鉴于此,论文中提出了一种快速非支配排序法,该方法的时间复杂度为
O(MN2)
。
该算法需要保存两个量:
支配个数np。该量是在可行解空间中可以支配个体p的所以个体的数量。
被支配个体集合SP。该量是可行解空间中所有被个体p支配的个体组成的集合。
排序算法的伪代码如下:
在上面伪代码中,第一部分循环为二重循环,时间复杂度为 O(N2) ,第二部分循环中,我们可以假设共有x个级别,而每个级别中最多有 (N−N/x) 各个体,每个个体的支配集合中也最多有 (N−N/x) 各个体。由此可得出循环次数为 x∗(N−N/x)∗(N−N/x)=((x−1)2/x2)N2M ,即时间复杂度为 O(MN2) 。

2. 保留多样性
原始的NSGA算法中使用共享函数的方法来维持物种的多样性,这种方法包含一个共享参数,该参数为所求解问题中所期望的共享范围。在该范围内,两个个体共享彼此的适应度。但是该方法有两个难点:
共享函数方法在保持多样性的性能很大程度上依赖于所选择的共享参数值。
由于每个解必须与种群中其它所有解比较,共享函数方法的总体复杂度为 O(N2) 。
在NSGA2中用拥挤比较的方法替换了共享函数方法。而要实现这两种方法,首先我们需要定义两个操作:密度估算和拥挤比较算子。
密度估算
我们根据每一目标函数计算这点两侧的两个点的平均距离。这个数值作为以最近邻居作为顶点的长方体周长的估计(称为拥挤系数)。在中,第i个解在它所在前沿面的拥挤系数是它周围长方体的长度(如虚线框所示)
伪代码如下:
这里, I[i].m 代表集合 I 中第i个个体的第m个目标函数值,参数fmaxm 和 fminm 是第m 个目标函数的最大和最小值。这个过程的复杂度主要由排序算法占据。由于有M次独立的排序,每次最多有N 个解(当多有种群成员都在一个前沿面中)包括进来,上述算法的计算复杂度为 O(MNlogN) 。拥挤比较算子:拥挤比较算子在算法的不同阶段将选
择的过程导向均匀分布的Pareto 最优前沿面。假设种群中每
一个体有两个属性:- 非支配排名( irank );
- 拥挤系数( idistance ).
现在我们定义一个偏序 <n <script type="math/tex" id="MathJax-Element-285"><_n</script>如下:
i<nj 如果 irank<jrank
或 irank=jrank
并且 idistance>jdistance
就是说,在两个有不同非支配排名解中,我们更喜欢拥
有更低(更好)排名的解。否则如果两个解属于同一前沿面,
那么我们更喜欢处于相对不太拥挤区域的解。

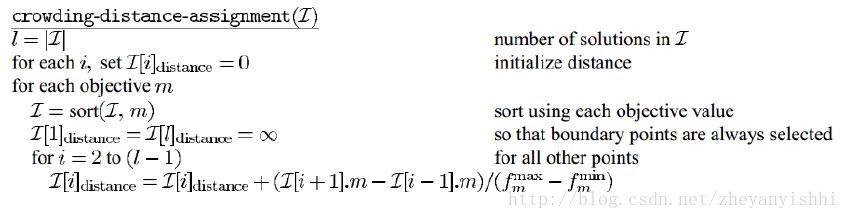
3.主体循环部分
(1).随机初始化开始种群P0。并对P0进行非支配排序,初始化每个个体的rank值。
(2). t = 0
(3).通过二进制锦标赛法从Pt选择个体,并进行交叉和变异操作,产生新一代种群Qt。
(4).通过合并Pt 和 Qt 产生出组合种群Rt = Pt UQt 。
(5).对Rt进行非支配排序,并通过排挤和精英保留策略选出N个个体,组成新一代种群Pt+1。
(6).跳转到步骤3,并循环,直至满足结束条件。
while condition:
Rt = Pt + Qt
F = fast_nondominate_sort( Rt )
Pt+1 = [ ]
i = 0
while len(Pt+1) + len( F[i] ) < N:
crowding_distance_assignment( F[i] )
Pt+1 += F[i]
i += 1
Pt+1 += F[i][0:N-len(Pt+1)]
Qt+1 = make_new_generation( Pt+1 )
t = t+1
下面分析NSAG2算法的整体复杂度,以下为该算法中的基本操作和其最差复杂度:
(1).非支配排序,最差复杂度为O(M(2N)2)。
(2).拥挤距离估算赋值,最差复杂度为O(M(2N)log(2N))。
(3).拥挤操作排序,最差复杂度为O(2Nlog(2N))。















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









