







问题定义

经典SVM
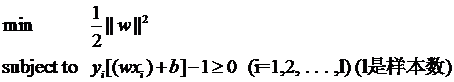

离群点

以我们人类的常识来判断,说有一万个点都符合某种规律(因而线性可分),有一个点不符合,那这一个点是否就代表了分类规则中我们没有考虑到的方面呢(因而规则应该为它而做出修改)?
其实我们会觉得,更有可能的是,这个样本点压根就是错误,是噪声,是提供训练集的同学人工分类时打瞌睡错放进去的。所以我们会简单的忽略这个样本点,仍然使用原来的分类器,其效果丝毫不受影响。
但这种对噪声的容错性是人的思维带来的,我们的程序可没有。由于我们原本的优化问题的表达式中,确实要考虑所有的样本点(不能忽略某一个,因为程序它怎么知道该忽略哪一个呢?),在此基础上寻找正负类之间的最大几何间隔,而几何间隔本身代表的是距离,是非负的,像上面这种有噪声的情况会使得整个问题无解。这种解法其实也叫做“硬间隔”分类法,因为他硬性的要求所有样本点都满足和分类平面间的距离必须大于某个值。
因此由上面的例子中也可以看出,硬间隔的分类法其结果容易受少数点的控制,这是很危险的(尽管有句话说真理总是掌握在少数人手中,但那不过是那一小撮人聊以自慰的词句罢了,咱还是得民主)。
松弛变量
上面那个问题的解决方法也很明显,就是仿照人的思路,允许一些点到分类平面的距离不满足原先的要求。由于不同的训练集各点的间距尺度不太一样,因此用间隔(而不是几何间隔)来衡量有利于我们表达形式的简洁。我们原先对样本点的要求是:

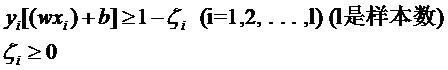
把损失加入到目标函数里的时候,就需要一个惩罚因子(cost,也就是libSVM的诸多参数中的C),原来的优化问题就变成了下面这样:
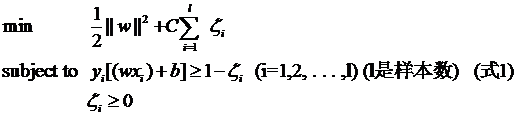
一是并非所有的样本点都有一个松弛变量与其对应。实际上只有“离群点”才有,或者也可以这么看,所有没离群的点松弛变量都等于0(对负类来说,离群点就是在前面图中,跑到H2右侧的那些负样本点,对正类来说,就是跑到H1左侧的那些正样本点)。
二是松弛变量的值实际上标示出了对应的点到底离群有多远,值越大,点就越远。
三是惩罚因子C决定了你有多重视离群点带来的损失,显然当所有离群点的松弛变量的和一定时,你定的C越大,对目标函数的损失也越大,此时就暗示着你非常不愿意放弃这些离群点,最极端的情况是你把C定为无限大,这样只要稍有一个点离群,目标函数的值马上变成无限大,马上让问题变成无解,这就退化成了硬间隔问题。
四是惩罚因子C不是一个变量,整个优化问题在解的时候,C是一个你必须事先指定的值,指定这个值以后,解一下,得到一个分类器,然后用测试数据看看结果怎么样,如果不够好,换一个C的值,再解一次优化问题,得到另一个分类器,再看看效果,如此就是一个参数寻优的过程,但这和优化问题本身决不是一回事,优化问题在解的过程中,C一直是定值,要记住。
五是尽管加了松弛变量这么一说,但这个优化问题仍然是一个优化问题(汗,这不废话么),解它的过程比起原始的硬间隔问题来说,没有任何更加特殊的地方。
惩罚因子
对付数据集偏斜问题的方法之一就是在惩罚因子上作文章,想必大家也猜到了,那就是给样本数量少的负类更大的惩罚因子,表示我们重视这部分样本(本来数量就少,再抛弃一些,那人家负类还活不活了),因此我们的目标函数中因松弛变量而损失的部分就变成了:

其中i=1…p都是正样本,j=p+1…p+q都是负样本。libSVM这个算法包在解决偏斜问题的时候用的就是这种方法。
那C+和C-怎么确定呢?它们的大小是试出来的(参数调优),但是他们的比例可以有些方法来确定。咱们先假定说C+是5这么大,那确定C-的一个很直观的方法就是使用两类样本数的比来算,对应到刚才举的例子,C-就可以定为500这么大(因为10,000:100=100:1嘛)。
但是这样并不够好,回看刚才的图,你会发现正类之所以可以“欺负”负类,其实并不是因为负类样本少,真实的原因是负类的样本分布的不够广(没扩充到负类本应该有的区域)。说一个具体点的例子,现在想给政治类和体育类的文章做分类,政治类文章很多,而体育类只提供了几篇关于篮球的文章,这时分类会明显偏向于政治类,如果要给体育类文章增加样本,但增加的样本仍然全都是关于篮球的(也就是说,没有足球,排球,赛车,游泳等等),那结果会怎样呢?虽然体育类文章在数量上可以达到与政治类一样多,但过于集中了,结果仍会偏向于政治类!所以给C+和C-确定比例更好的方法应该是衡量他们分布的程度。比如可以算算他们在空间中占据了多大的体积,例如给负类找一个超球——就是高维空间里的球啦——它可以包含所有负类的样本,再给正类找一个,比比两个球的半径,就可以大致确定分布的情况。显然半径大的分布就比较广,就给小一点的惩罚因子。
但是这样还不够好,因为有的类别样本确实很集中,这不是提供的样本数量多少的问题,这是类别本身的特征(就是某些话题涉及的面很窄,例如计算机类的文章就明显不如文化类的文章那么“天马行空”),这个时候即便超球的半径差异很大,也不应该赋予两个类别不同的惩罚因子。
核函数与松弛因子
松弛变量也就是个解决线性不可分问题的方法罢了,但是回想一下,核函数的引入不也是为了解决线性不可分的问题么?为什么要为了一个问题使用两种方法呢?
其实两者还有微妙的不同。一般的过程应该是这样,还以文本分类为例。在原始的低维空间中,样本相当的不可分,无论你怎么找分类平面,总会有大量的离群点,此时用核函数向高维空间映射一下,虽然结果仍然是不可分的,但比原始空间里的要更加接近线性可分的状态(就是达到了近似线性可分的状态),此时再用松弛变量处理那些少数“冥顽不化”的离群点,就简单有效得多啦。















 954
954

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









