







岭回归(英文名:ridge regression, Tikhonov regularization)是一种专用于共线性数据分析的有偏估计回归方法,实质上是一种改良的最小二乘估计法,通过放弃最小二乘法的无偏性,以损失部分信息、降低精度为代价获得回归系数更为符合实际、更可靠的回归方法,对病态数据的拟合要强于最小二乘法。
通常岭回归方程的R平方值会稍低于普通回归分析,但回归系数的显著性往往明显高于普通回归,在存在共线性问题和病态数据偏多的研究中有较大的实用价值。
使用数理统计模型从海量数据中有效挖掘信息越来越受到业界关注。在建立模型之初,为了尽量减小因缺少重要自变量而出现的模型偏差,通常会选择尽可能多的自变量。然而,建模过程需要寻找对因变量最具有强解释力的自变量集合,也就是通过自变量选择(指标选择、字段选择)来提高模型的解释性和预测精度。指标选择在统计建模过程中是极其重要的问题。Lasso算法则是一种能够实现指标集合精简的估计方法。
Tibshirani(1996)提出了Lasso(The Least Absolute Shrinkage and Selectionator operator)算法。这种算法通过构造一个惩罚函数获得一个精炼的模型;通过最终确定一些指标的系数为零,LASSO算法实现了指标集合精简的目的。这是一种处理具有复共线性数据的有偏估计。Lasso的基本思想是在回归系数的绝对值之和小于一个常数的约束条件下,使残差平方和最小化,从而能够产生某些严格等于0的回归系数,得到解释力较强的模型。R统计软件的Lars算法的软件包提供了Lasso算法。根据模型改进的需要,数据挖掘工作者可以借助于Lasso算法,利用AIC准则和BIC准则精炼简化统计模型的变量集合,达到降维的目的。因此,Lasso算法是可以应用到数据挖掘中的实用算法。
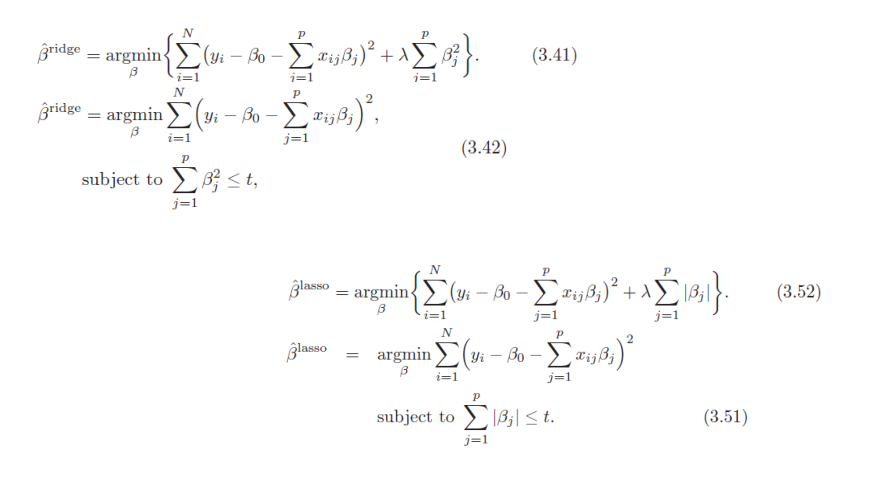
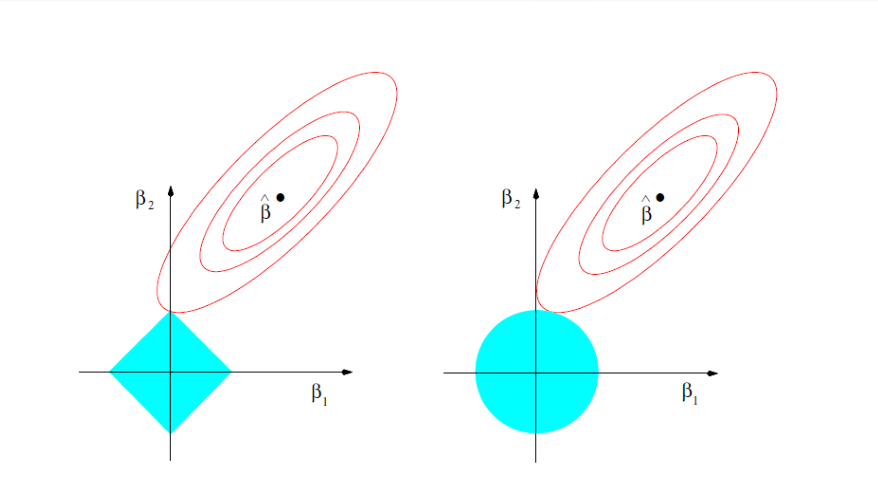
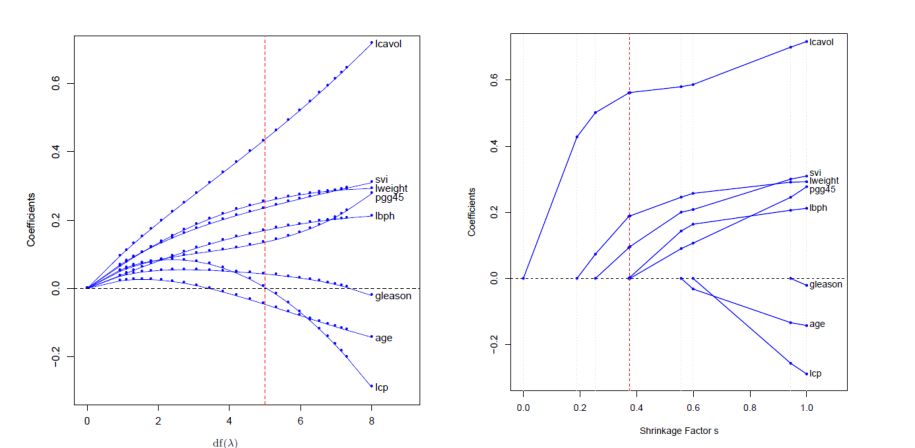
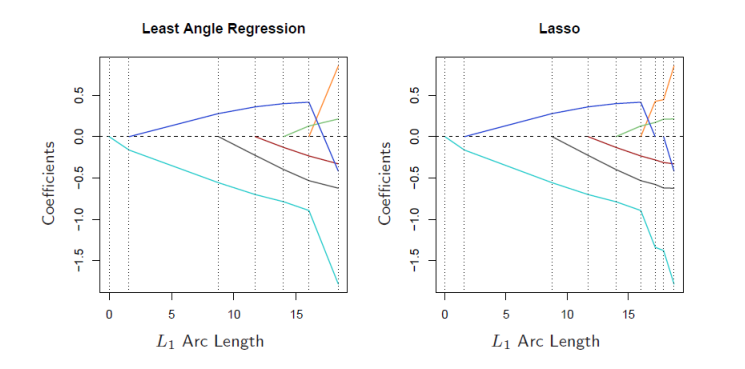
左图可以看出岭回归选择k时很难使变量系数为0,LASSO回归选择一个k可以是多数变量系数为0
用最小角回归求多元回归中的最优解。
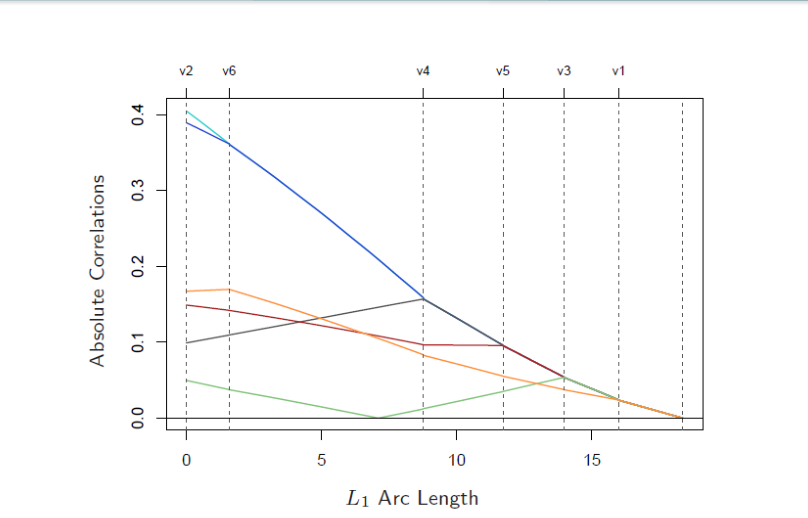
首先选择v2变量,可以看出v2与残差相关系数逐渐减小。(目的就是寻找残差与所有变量的向量相关系数为0,就是残差垂直于变量组成的超平面,此曲线与LASSO寻优图类似),之后v6赶上v2所有寻优方向变成了v2与v6的夹角方向了,v2与v6绘制成一条线,最后找到一个最优解。
调用R中的lars包进行存在多重共线性的变量的选择
导入数据集longley
把数据集转换为矩阵
w <- as.matrix(longley)
laa <- lars(w[,2:7],w[,1])
w[,1]表示第一列表示因变量
> laa
Call:
lars(x = w[, 2:7], y = w[, 1])
R-squared: 0.993
Sequence of LASSO moves:
GNP Year Armed.Forces Unemployed Employed Population Year Employed
Var 1 5 3 2 6 4 -5 -6
Step 1 2 3 4 5 6 7 8
Employed Year Employed Employed
Var 6 5 -6 6
Step 9 10 11 12
说明:
第一步:加第一变量,第二步:加第五变量,第七步:减去第五变量
> summary(laa)
LARS/LASSO
Call: lars(x = w[, 2:7], y = w[, 1])
Df Rss Cp
0 1 1746.86 1210.0561
1 2 1439.51 996.6871
2 3 32.31 12.6400
3 4 23.18 8.2425
4 5 22.91 10.0505
5 6 22.63 11.8595
6 7 18.04 10.6409
7 6 14.74 6.3262
8 5 13.54 3.4848
9 6 13.27 5.2974
10 7 13.01 7.1189
11 6 12.93 5.0624
12 7 12.84 7.0000
cp越小越好,可以看出cp=3.4848最小,所以在第8步达到最优,所以删除5,6变量最好。















 9779
9779

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









