






Shell 工具和脚本(Shell Tools and Scripting)
一、shell脚本
1.1、变量赋值
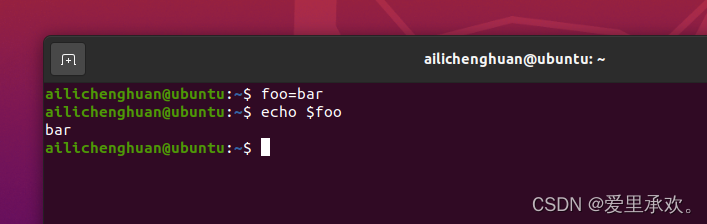
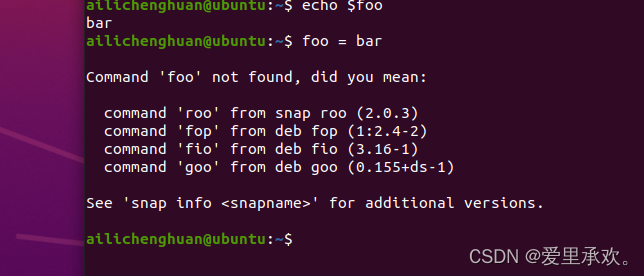
在bash中为变量赋值的语法是foo=bar,访问变量中存储的数值,其语法为 $foo。 需要注意的是,foo = bar (使用空格隔开)是不能正确工作的,因为解释器会调用程序foo 并将 = 和 bar作为参数。 总的来说,在shell脚本中使用空格会起到分割参数的作用,有时候可能会造成混淆,请务必多加检查。
Bash中的字符串通过' 和 "分隔符来定义,但是它们的含义并不相同。以'定义的字符串为原义字符串,其中的变量不会被转义,而 "定义的字符串会将变量值进行替换。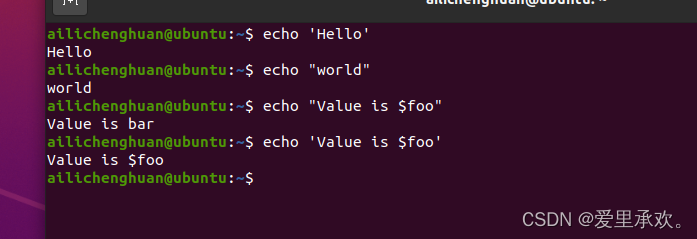
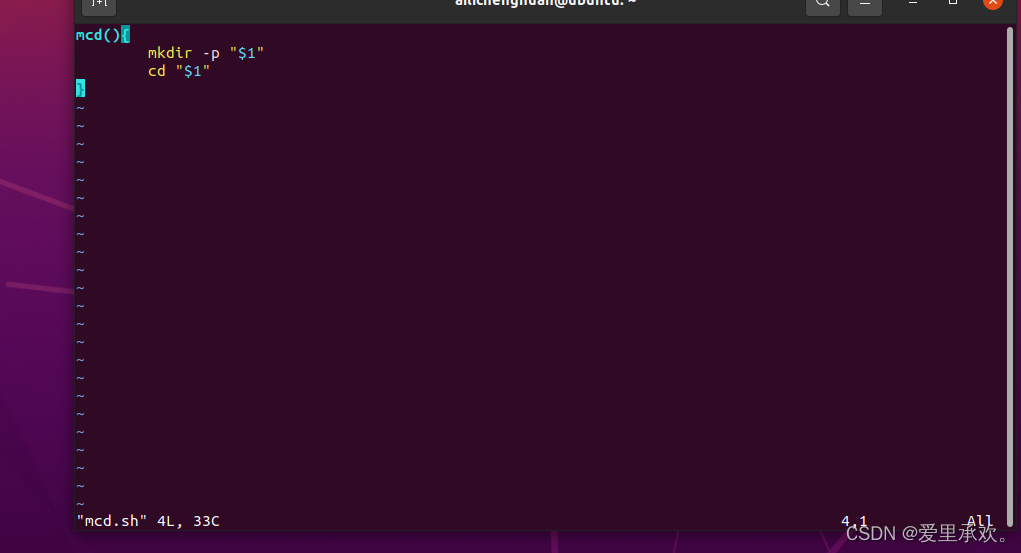
和其他大多数的编程语言一样,bash也支持if, case, while 和 for 这些控制流关键字。同样地, bash 也支持函数,它可以接受参数并基于参数进行操作。下面这个函数是一个例子,它会创建一个文件夹并使用cd进入该文件夹。
在这里我们首先调用了mcd()函数,之后调用"mkdir"命令来创建这个目录,"$1"是一种特殊变量,类似于其他语言里的"argv","argv"第一项将包含该参数。
"sourch mcd.sh"将会在我们的shell中加载并执行这个脚本。
"mcd test"我们从当前目录移动到"test"目录,
这里 $1 是脚本的第一个参数。与其他脚本语言不同的是,bash使用了很多特殊的变量来表示参数、错误代码和相关变量。下面列举了其中一些变量,更完整的列表可以参考 这里。
$0- 脚本名$1到$9- 脚本的参数。$1是第一个参数,依此类推。$@- 所有参数$#- 参数个数$?- 前一个命令的返回值$$- 当前脚本的进程识别码!!- 完整的上一条命令,包括参数。常见应用:当你因为权限不足执行命令失败时,可以使用sudo !!再尝试一次。$_- 上一条命令的最后一个参数。如果你正在使用的是交互式 shell,你可以通过按下Esc之后键入 . 来获取这个值。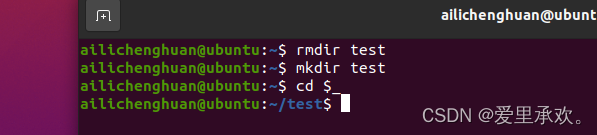
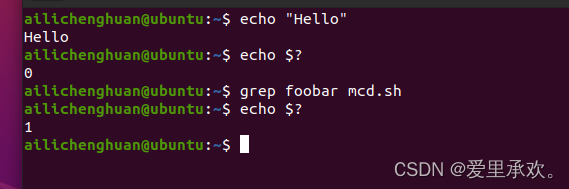
上图,"echo $?"返回0则代表程序正常执行返回,没有问题,而返回1则代表程序出现错误,"grep foorbar mcd.sh":表示从"mcd.sh"中寻找"foobar"字符串,但是该字符串不存在,故,"grep"不会输出任何内容,但是会返回1告诉我们程序发生了错误。
命令通常使用 STDOUT来返回输出值,使用STDERR 来返回错误及错误码,便于脚本以更加友好的方式报告错误。 返回码或退出状态是脚本/命令之间交流执行状态的方式。返回值0表示正常执行,其他所有非0的返回值都表示有错误发生。
退出码可以搭配 &&(与操作符 - 在第一个命令没有错误的情况下执行第二个命令)和 ||(或操作符 - 第一个命令失败,则执行第二个命令,第一个命令成功,则跳过第二个命令(短路))使用,用来进行条件判断,决定是否执行其他程序。它们都属于短路运算符(short-circuiting)。同一行的多个命令可以用 ; 分隔。程序 true 的返回码永远是0,false 的返回码永远是1。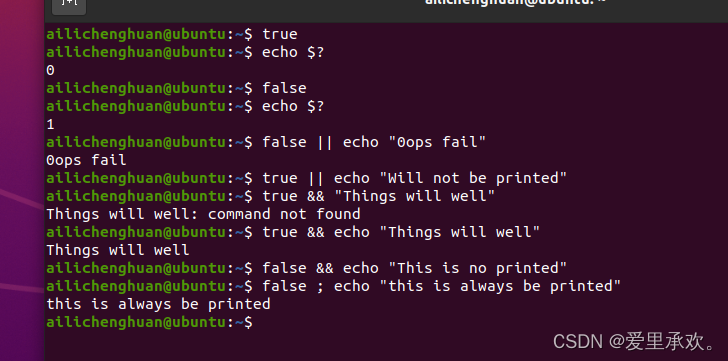
"foo=$(pwd)":该命令打印我们现在所在的当前工作目录,然后将其存储到"foo"变量中。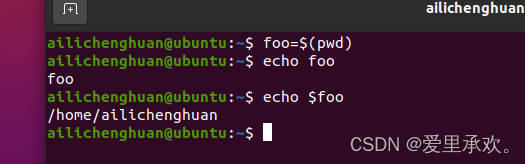
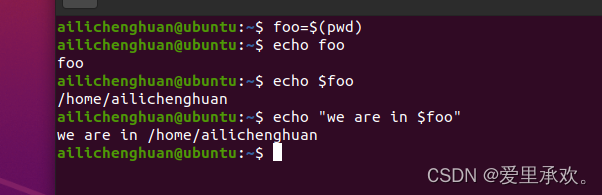
我们上述的命令都是将变量扩展为字符串输出,我们还有另一个"魔法"叫进程替换,它和命令替换有些相似,"cat < (ls) < (ls ..)":命令会在内部执行,然后将输出放入一个类似临时文件的东西中,并将文件标识符提供给最左边的命令。所以在这种情况下,我们正在查看这个目录,将其放入临时文件中,并对父文件夹做同样的事情,然后将两个文件连接起来。(因为一些命令并不是从标准输入流中获取输入的,而是从某些文件中获取的)
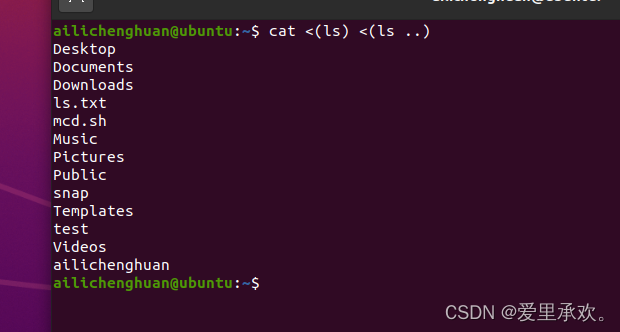
所以我们得到了两个命令连在一起的输出。
#!/bin/bash
echo "Starting program at $(date)" # date会被替换成日期和时间
echo "Running program $0 with $# arguments with pid $$"
for file in "$@"; do
grep foobar "$file" > /dev/null 2> /dev/null
# 如果模式没有找到,则grep退出状态为 1
# 我们将标准输出流和标准错误流重定向到Null,因为我们并不关心这些信息
if [[ $? -ne 0 ]]; then
echo "File $file does not have any foobar, adding one"
echo "# foobar" >> "$file"
fi
done"$0":我们正在运行的脚本文件名。
"$#":我们给该命令参数的数量。
"$$":正在运行该命令的进程ID(PID)
"$@":它将展开为所有的参数,因此我们可以不必限定参数而只编写"$1"、"$2"、"$3",如果我们不知道有多少参数,可以将所有的参数放在那里。然后将其传递给for循环,for循环将依次创建"file"变量,并将每一个参数赋值给"file"。
"grep":在某个文件中搜索字符串
如果我们关心程序的输出,我们可以将其重定向到某个地方,以保存它或是连接其它文件。但在这里,我们需要关注错误代码,对于这个脚本,我们想知道"grep"是否运行成功。我们完全可以忽略输出,则将输出重定向到"/dev/null"(黑洞文件),它是UNIX中的一种特殊设备,你可以像写入文件一样写入数据,但它将被丢弃,"2>"用于重定向标准错误流,因为这两个流是分开的,你需要告诉Bash如何去处理它。所以在这行代码中,我们检查文件是否包含"foobar",如果包含,则返回0;如果不包含,则返回非0的错误代码。
在条件语句中,我们比较 $? 是否等于0。"-ne":"not equal"(不相等)
"echo # foobar":希望这是对文件的注释,然后我们使用">>"在文件末尾追加,因为文件名已经被传递给脚本,我们之前不知道文件名,所以我们用了"file"变量,现在要将其展开。
Bash实现了许多类似的比较操作,您可以查看 test 手册(或于终端上键入命令"man test")。 在bash中进行比较时,尽量使用双方括号 [[ ]] 而不是单方括号 [ ],这样会降低犯错的几率,尽管这样并不能兼容 sh。 更详细的说明参见这里。
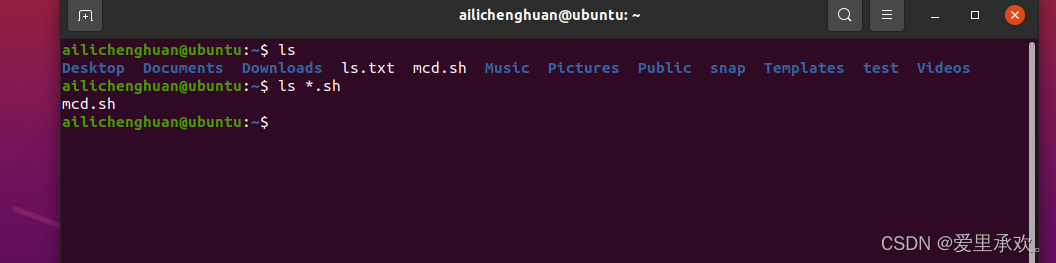
下面的图片我们使用"ls"可以看到现在路径下的文件,如果我们想要显示所有后缀是".sh"的文件该怎么样呢?我们可以使用"*",即在想要显示的文件后缀前加入它,就可以完成要求。
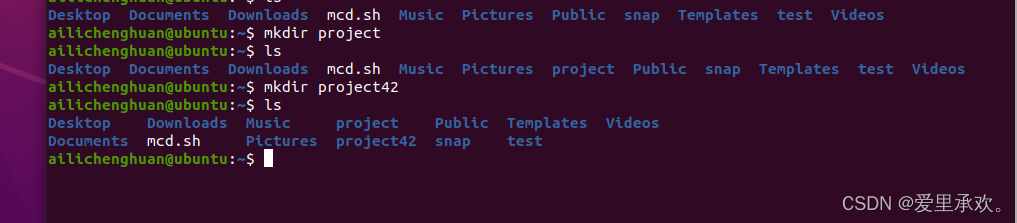
上图我们可以看到我们拥有以"project"开头的文件,假设我们现在只想匹配"project"后加一个字符,而并非两个字符,我们可以使用"?",它可以扩展为任何一个字符。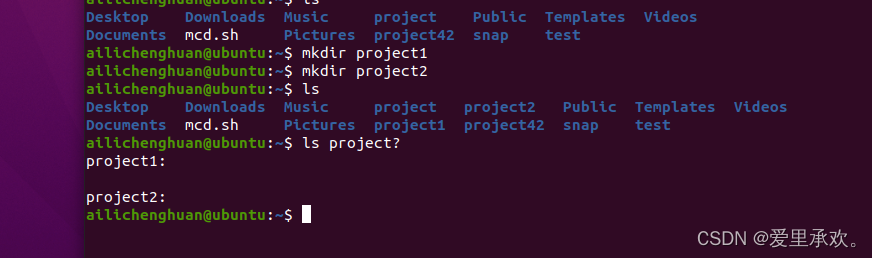
当执行脚本时,我们经常需要提供形式类似的参数。bash使我们可以轻松的实现这一操作,它可以基于文件扩展名展开表达式。这一技术被称为shell的 通配(globbing)
- 通配符 - 当你想要利用通配符进行匹配时,你可以分别使用
?和*来匹配一个或任意个字符。例如,对于文件foo,foo1,foo2,foo10和bar,rm foo?这条命令会删除foo1和foo2,而rm foo*则会删除除了bar之外的所有文件。 - 花括号
{}- 当你有一系列的指令,其中包含一段公共子串时,可以用花括号来自动展开这些命令。这在批量移动或转换文件时非常方便。
convert image.{png,jpg}
# 会展开为
convert image.png image.jpg
cp /path/to/project/{foo,bar,baz}.sh /newpath
# 会展开为
cp /path/to/project/foo.sh /path/to/project/bar.sh /path/to/project/baz.sh /newpath
# 也可以结合通配使用
mv *{.py,.sh} folder
# 会移动所有 *.py 和 *.sh 文件
mkdir foo bar
# 下面命令会创建foo/a, foo/b, ... foo/h, bar/a, bar/b, ... bar/h这些文件
touch {foo,bar}/{a..h}
touch foo/x bar/y
# 比较文件夹 foo 和 bar 中包含文件的不同
diff <(ls foo) <(ls bar)
# 输出
# < x
# ---
# > y假设我们在文件夹中有一个图像,我们想将其从PNG转化成JPG, 我们只需输入"convert image.{png,jpg}"即可,我们还可以输入"touch foo{}"touch一串foo,所有这些都将会被扩展。
我们还可多层操作,将它们做笛卡尔积,"touch project{1,2}/src/test/test{1,2,3}.py"如果我们有一些这样的组:"{1,2}",然后后面有{1,2,3},这将以这两个组的笛卡尔积进行扩展,并将扩展为下图所有的这些东西,我们可以快速的创建文件。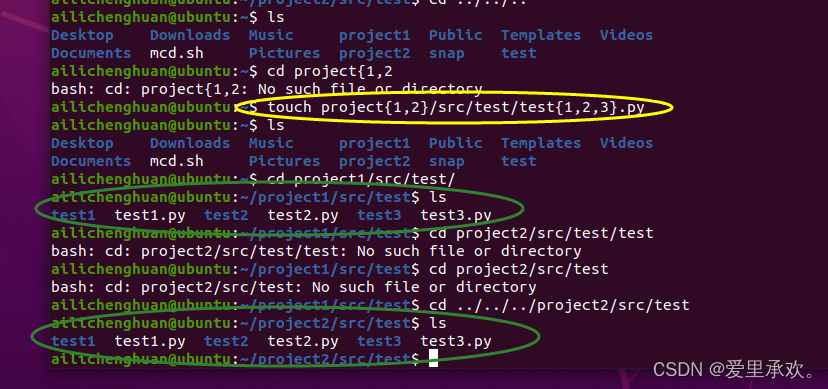
我们还可以将"*"和"{}"结合使用,我们还可以用类似区间的东西。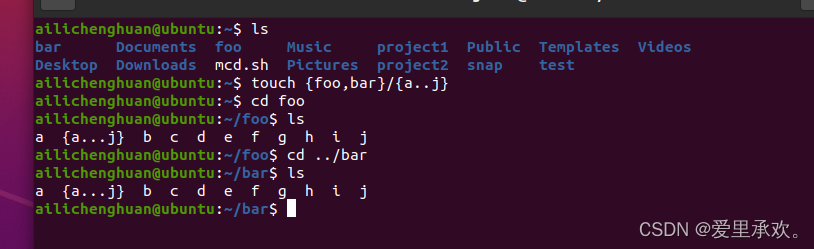
这将会扩展到"foo/a"、"foo/b"...所有这些组合,一直到"j",同样,对于"bar"也是如此。
那么如果我们在这两个目录创建两个不同的文件,并且演示一下之前讲过的进程替换,比如我们想检查一下这两个文件夹有哪些个文件不同,我们可以使用"diff",并让其在两个"ls"的输出间作比较。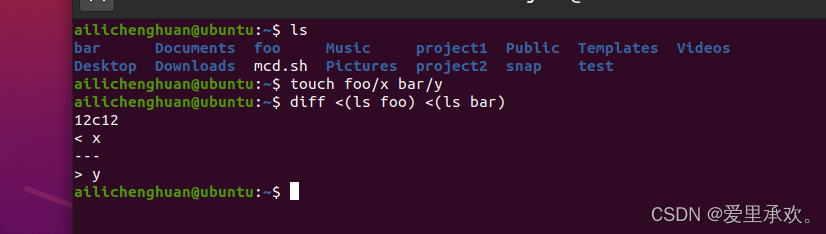
毫无疑问,我们得到的结果是"x"存在于第一个文件夹中,"y"存在于第二个文件夹中。
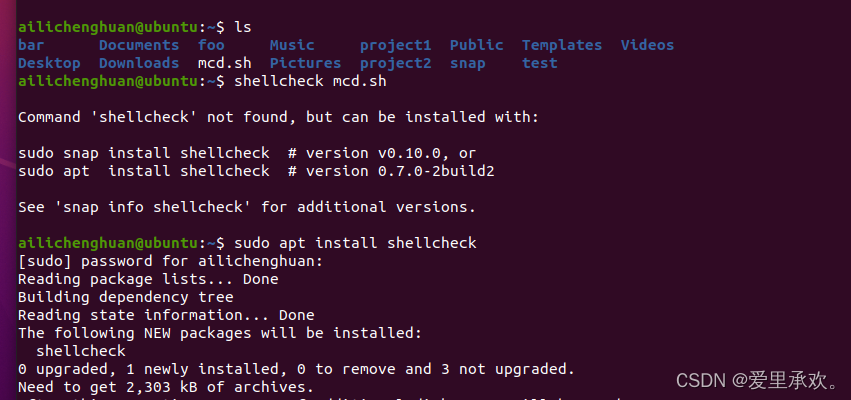
编写 bash 脚本有时候会很别扭和反直觉。例如 shellcheck 这样的工具可以帮助你定位sh/bash脚本中的错误。
注意,脚本并不一定只有用 bash 写才能在终端里调用。比如说,这是一段 Python 脚本,作用是将输入的参数倒序输出:
#!/usr/local/bin/python
import sys
for arg in reversed(sys.argv[1:]):
print(arg)内核知道去用 python 解释器而不是 shell 命令来运行这段脚本,是因为脚本的开头第一行的 shebang。
在 shebang 行中使用 env 命令是一种好的实践,它会利用环境变量中的程序来解析该脚本,这样就提高了您的脚本的可移植性。env 会利用我们第一节讲座中介绍过的PATH 环境变量来进行定位。 例如,使用了env的shebang看上去是这样的#!/usr/bin/env python。
shell函数和脚本有如下一些不同点:
- 函数只能与shell使用相同的语言,脚本可以使用任意语言。因此在脚本中包含
shebang是很重要的。 - 函数仅在定义时被加载,脚本会在每次被执行时加载。这让函数的加载比脚本略快一些,但每次修改函数定义,都要重新加载一次。
- 函数会在当前的shell环境中执行,脚本会在单独的进程中执行。因此,函数可以对环境变量进行更改,比如改变当前工作目录,脚本则不行。脚本需要使用 export 将环境变量导出,并将值传递给环境变量。
- 与其他程序语言一样,函数可以提高代码模块性、代码复用性并创建清晰性的结构。shell脚本中往往也会包含它们自己的函数定义。
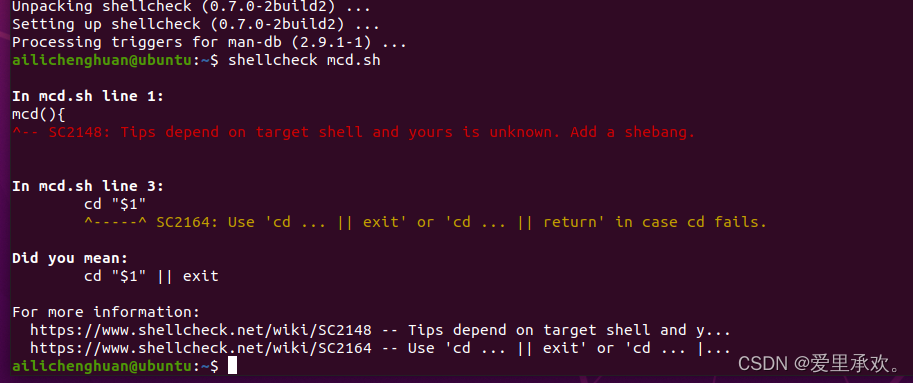
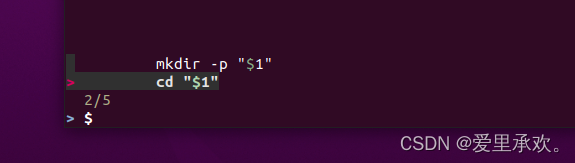
"shellcheck"工具:它可以为我们提供警告、语法错误,和其他可能不正确引用或文件中错放空格的问题。例如,对于非常简单的"mcd.sh"文件,我们会得到一些错误提示,我们缺少了"shebang",如果在不同的系统上运行,可能无法正确解释它;另外,"cd"的命令可能会不正确的扩展,我们可以使用它下面给出的方法。这样做更改的效果是,如果"cd"没有正确执行,你不能"cd"进入该文件夹,因为要么你没有权限,要么其不存在,这将返回一个非0的错误代码,脚本将执行"exit",这将停止脚本的运行,而不是继续对实际不存在的地方执行命令。
二、Shell工具
2.1、查看命令如何使用
看到这里,您可能会有疑问,我们应该如何为特定的命令找到合适的标记呢?例如 ls -l, mv -i 和 mkdir -p。更普遍的是,给您一个命令行,您应该怎样了解如何使用这个命令行并找出它的不同的选项呢? 一般来说,您可能会先去网上搜索答案,但是,UNIX 可比 StackOverflow 出现的早,因此我们的系统里其实早就包含了可以获取相关信息的方法。
在上一节中我们介绍过,最常用的方法是为对应的命令行添加-h 或 --help 标记。另外一个更详细的方法则是使用man 命令。man 命令是手册(manual)的缩写,它提供了命令的用户手册。
例如,man rm 会输出命令 rm 的说明,同时还有其标记列表,包括之前我们介绍过的-i。 事实上,目前我们给出的所有命令的说明链接,都是网页版的Linux命令手册。即使是您安装的第三方命令,前提是开发者编写了手册并将其包含在了安装包中。在交互式的、基于字符处理的终端窗口中,一般也可以通过 :help 命令或键入 ? 来获取帮助。
有时候手册内容太过详实,让我们难以在其中查找哪些最常用的标记和语法。 TLDR pages 是一个很不错的替代品,它提供了一些案例,可以帮助您快速找到正确的选项。
例如,自己就常常在tldr上搜索tar 和 ffmpeg 的用法。
2.2、查找文件
如果我们已经知道要查找所有名为"src"的文件,那么我们可以用"find",我们将在当前文件夹下调用"find","."表示当前文件夹,我们要让它的名称为"src",类型是文件夹,输入这个命令后,它将递归的浏览文件夹,并查找所有符合该标准的文件或文件夹。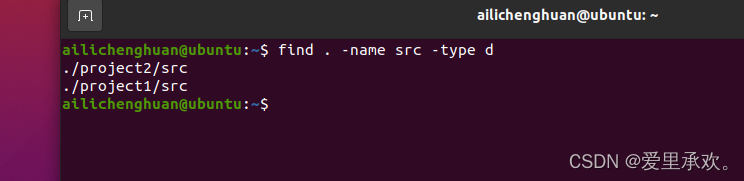
我们还可以用它来查找特定模式的文件路径,我们希望有一些文件夹(并不在意数量),我们想要的是所有的Python脚本,所有扩展名为".py"的东西,这些都需要在名为test的文件夹下。"-type f"代表查找类型是文件。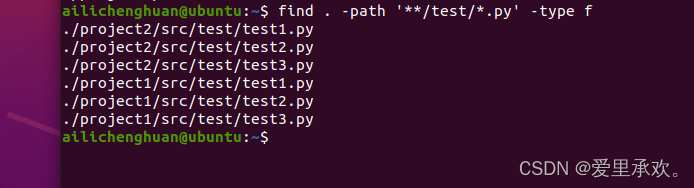
你还可以查找修改过的文件,"-mtime"用于修改时间,在过去一天内修改过的文件,这几乎将是所有文件。
"find"不仅仅可以用于查找,我们还可以在找到这些文件时进行一些操作。所有,我们查找所有扩展名为"tmp"的文件,并且我们告诉"find",在此文件中的所有文件我们将对其执行"rm"命令。
# 删除全部扩展名为.tmp 的文件
find . -name '*.tmp' -exec rm {} \;
# 查找全部的 PNG 文件并将其转换为 JPG
find . -name '*.png' -exec convert {} {}.jpg \;
如果我们只想匹配以"tmp"结尾的内容,你可以使用"fd",这是一个更短的命令,它默认使用正则表达式,甚至还能忽略搜索你的git文件。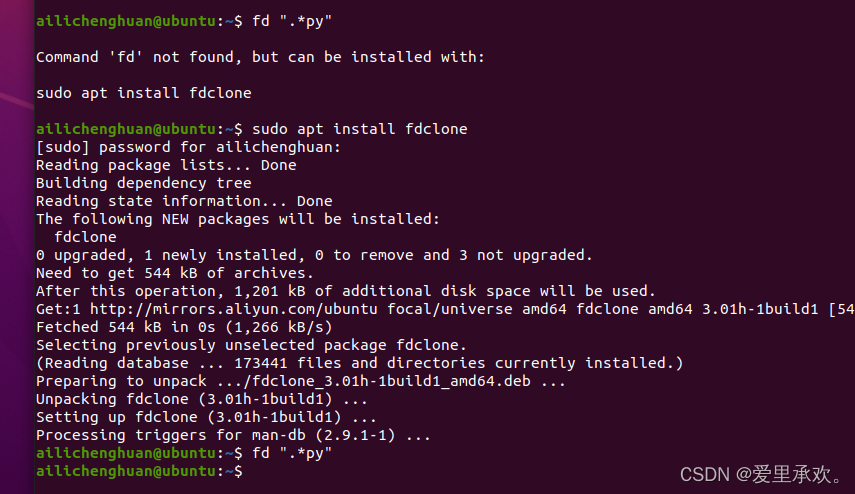
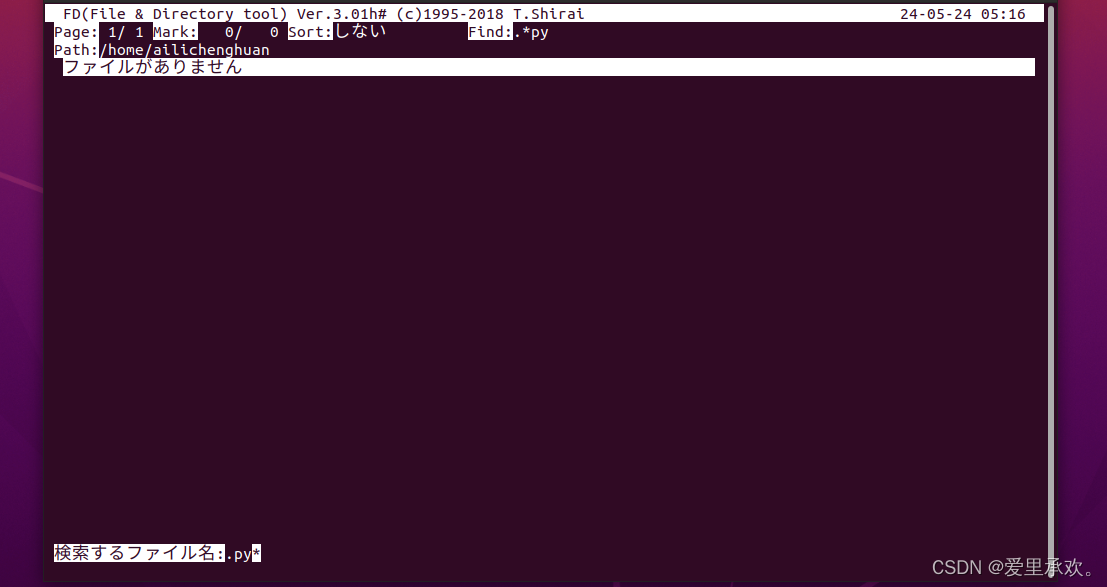
# 查找所有名称为src的文件夹
find . -name src -type d
# 查找所有文件夹路径中包含test的python文件
find . -path '*/test/*.py' -type f
# 查找前一天修改的所有文件
find . -mtime -1
# 查找所有大小在500k至10M的tar.gz文件
find . -size +500k -size -10M -name '*.tar.gz'fd 就是一个更简单、更快速、更友好的程序,它可以用来作为find的替代品。它有很多不错的默认设置,例如输出着色、默认支持正则匹配、支持unicode并且我认为它的语法更符合直觉。以模式PATTERN 搜索的语法是 fd PATTERN。
大多数人都认为 find 和 fd 已经很好用了,但是有的人可能想知道,我们是不是可以有更高效的方法,例如不要每次都搜索文件而是通过编译索引或建立数据库的方式来实现更加快速地搜索。
这就要靠 locate 了。 locate 使用一个由 updatedb负责更新的数据库,在大多数系统中 updatedb 都会通过 cron (Cron是一种在Unix、Linux和类Unix操作系统中用于定期运行任务的工具。它允许用户指定一个或多个命令或脚本,并设置在指定时间或周期运行这些命令或脚本的方式。)每日更新。这便需要我们在速度和时效性之间作出权衡。而且,find 和类似的工具可以通过别的属性比如文件大小、修改时间或是权限来查找文件,locate则只能通过文件名。 这里有一个更详细的对比。
"locate":只会查找你的文件系统中包含你想要的子字符串的路径。该命令找路径的速度很快,因为它已经在此上构建了一个系统,为了使其保持更新,我们使用"updatedb"命令来更新数据库。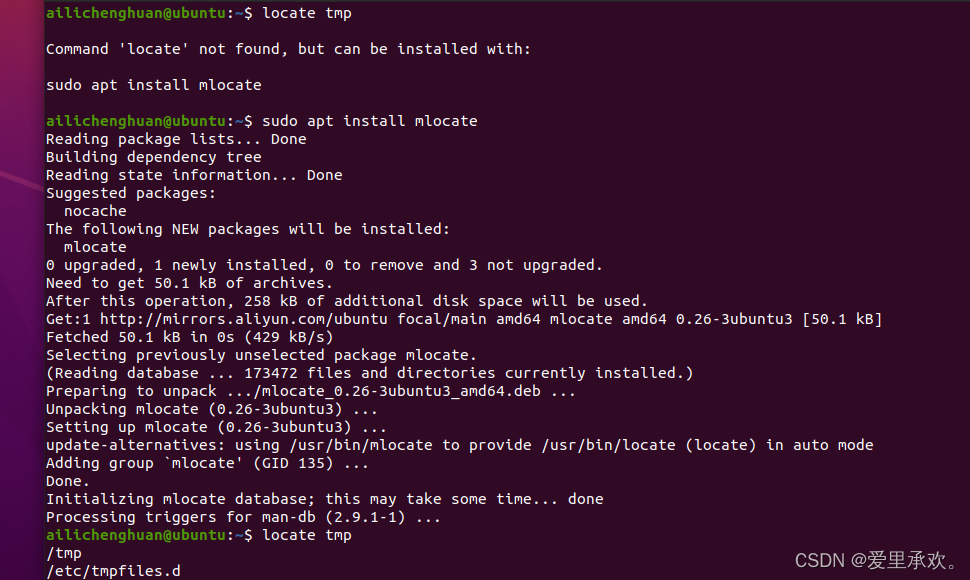
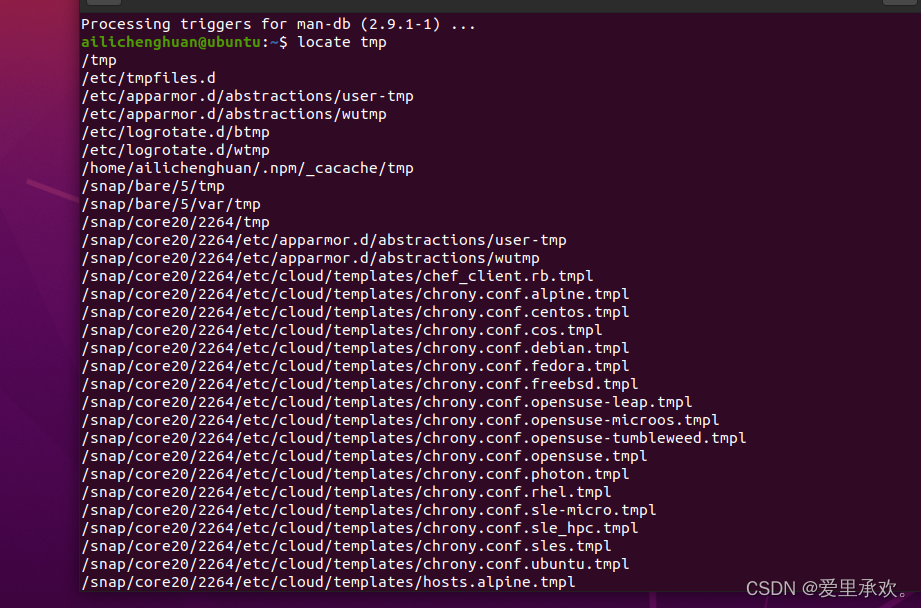
如果我们想查找文件的内容,可以使用之前提到的"grep"命令。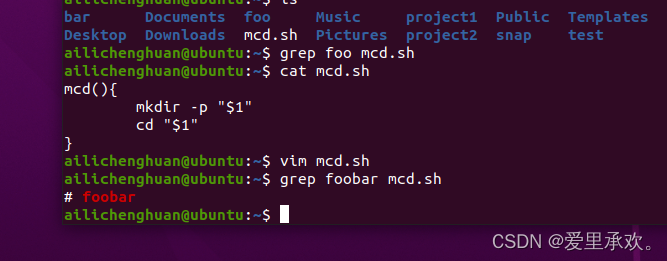
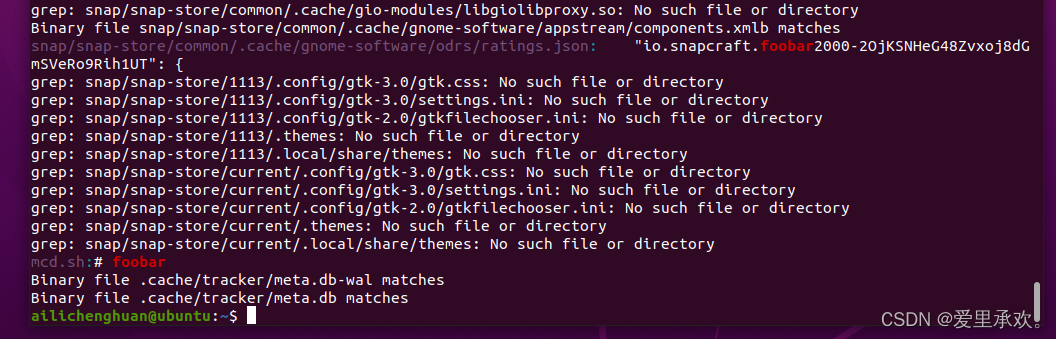
如果你想要在再次递归的搜索当前结构,并查找更多文件,怎么办?我们可以使用"find"和"-exec"。但其实,"grep"有"-R"标志,它将遍历整个目录。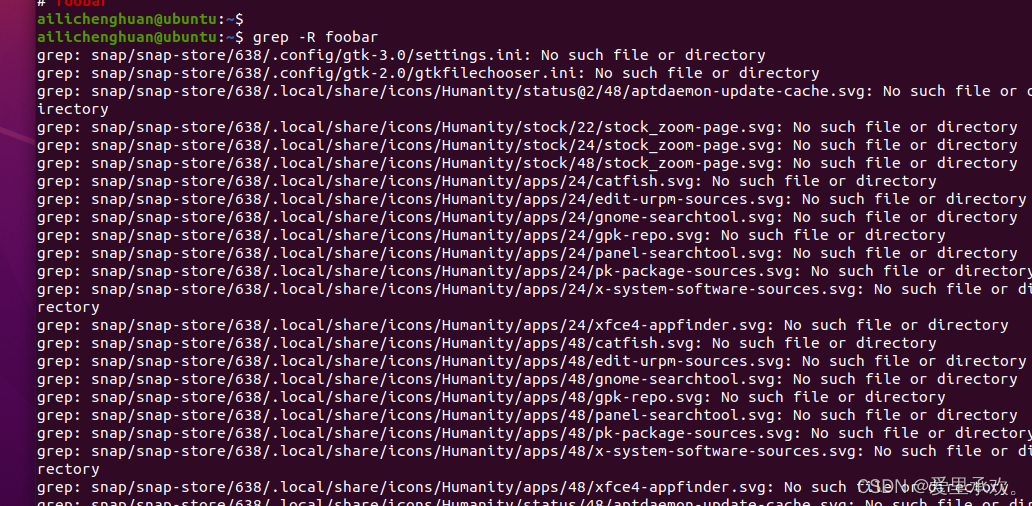
2.3、查找代码
查找文件是很有用的技能,但是很多时候您的目标其实是查看文件的内容。一个最常见的场景是您希望查找具有某种模式的全部文件,并找它们的位置。
为了实现这一点,很多类UNIX的系统都提供了grep命令,它是用于对输入文本进行匹配的通用工具。它是一个非常重要的shell工具,我们会在后续的数据清理课程中深入的探讨它。
grep 有很多选项,这也使它成为一个非常全能的工具。其中我经常使用的有 -C :获取查找结果的上下文(Context);-v 将对结果进行反选(Invert),也就是输出不匹配的结果。举例来说, grep -C 5 会输出匹配结果前后五行。当需要搜索大量文件的时候,使用 -R 会递归地进入子目录并搜索所有的文本文件。
但是,我们有很多办法可以对 grep -R 进行改进,例如使其忽略.git 文件夹,使用多CPU等等。
因此也出现了很多它的替代品,包括 ack, ag 和 rg。它们都特别好用,但是功能也都差不多,我比较常用的是 ripgrep (rg) ,因为它速度快,而且用法非常符合直觉。例子如下:
rg "import requests" -t py ~/scratch # 在"scratch"文件中快速搜索导入了"requests"库
的所有的python文件
# 查找所有使用了 requests 库的文件
rg -t py 'import requests'
# 查找所有没有写 shebang("^#!" - 正则表达式) 的文件(包含隐藏文件 -u不忽略隐藏文件)
rg -u --files-without-match "^#!"
# 查找所有的foo字符串,并打印其之后的5行
rg foo -A 5
# 打印匹配的统计信息(匹配的行和文件的数量)
rg --stats PATTERN
rg "import requests" -t py -C 5 --stats ~/scratch # 它会告诉我们搜索所有内容的信息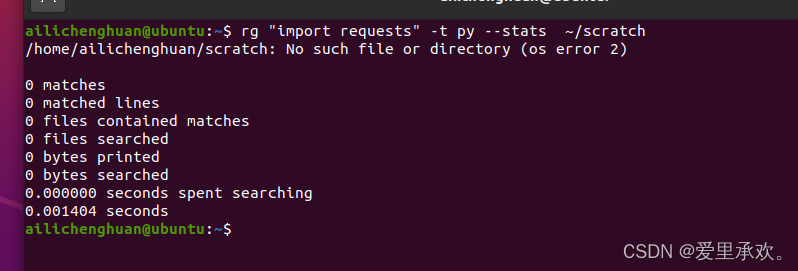
2.4、查找shell命令
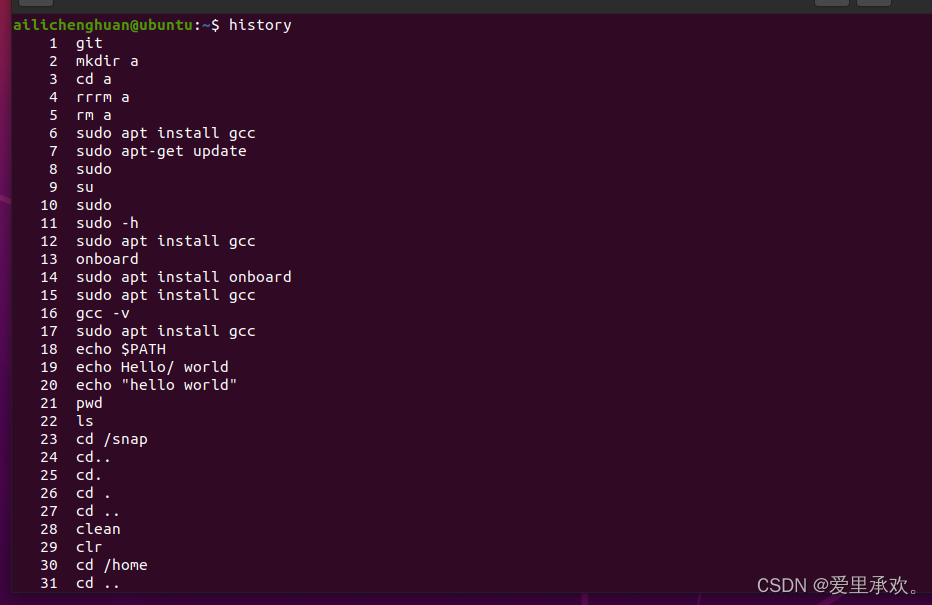
history 命令允许您以程序员的方式来访问shell中输入的历史命令。这个命令会在标准输出中打印shell中的历史命令。如果我们要搜索历史记录,则可以利用管道将输出结果传递给 grep 进行模式搜索。 history | grep find 会打印包含find子串的命令。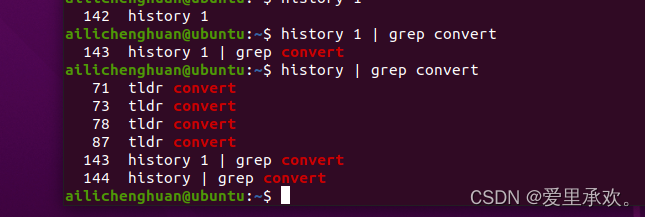
对于大多数的shell来说,您可以使用 Ctrl+R 对命令历史记录进行回溯搜索。敲 Ctrl+R 后您可以输入子串来进行匹配,查找历史命令行。
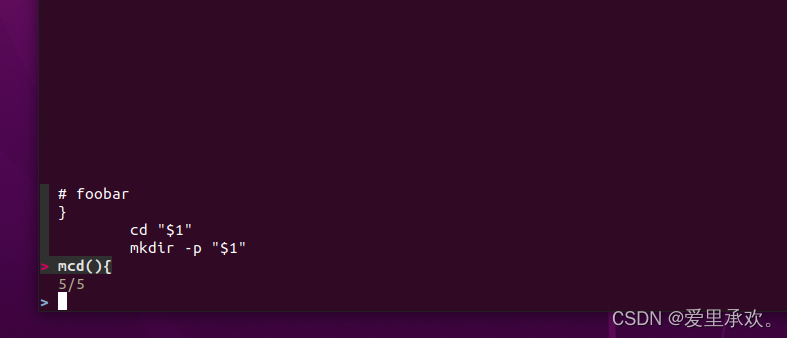
Ctrl+R 可以配合 fzf 使用。fzf 是一个通用的模糊查找工具,它可以和很多命令一起使用。这里我们可以对历史命令进行模糊查找并将结果以赏心悦目的格式输出。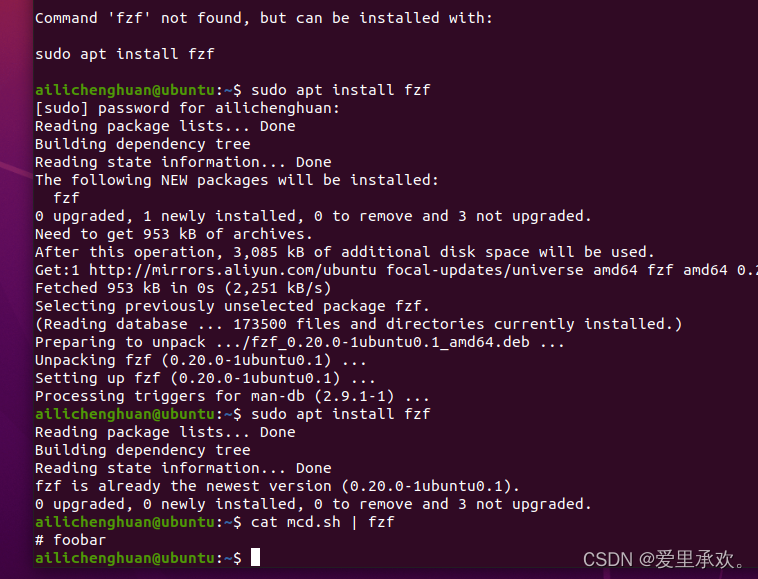

"历史子字符串搜索":另外一个和历史命令相关的技巧我喜欢称之为基于历史的自动补全。 这一特性最初是由 fish shell 创建的,它可以根据您最近使用过的开头相同的命令,动态地对当前的shell命令进行补全。这一功能在 zsh 中也可以使用,它可以极大的提高用户体验。
2.5、文件夹导航
"-R"来递归的列出某个目录的结构。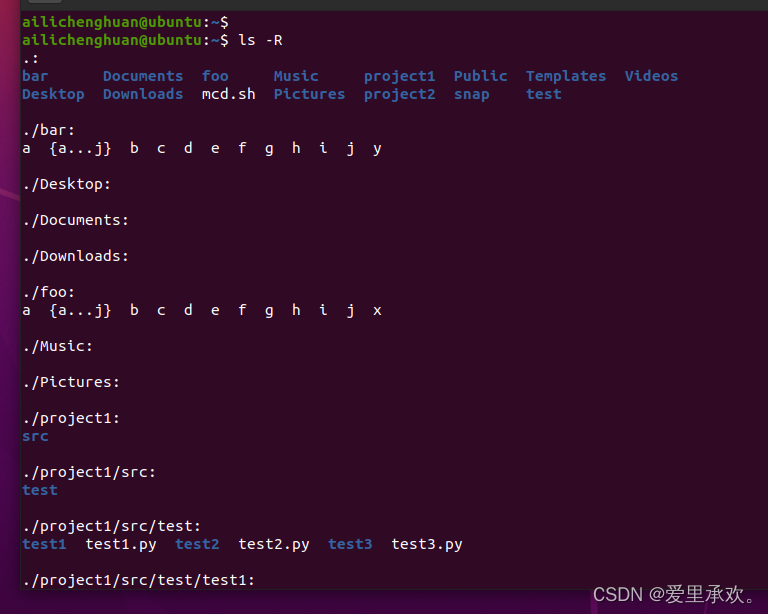
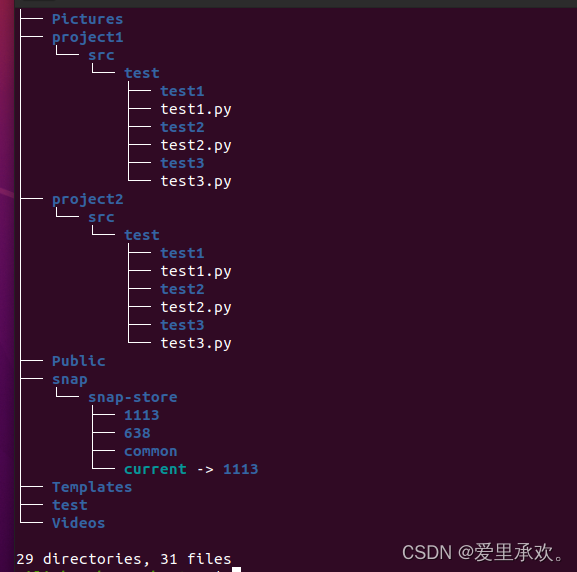
"tree":更友好的打印目录结构。
之前对所有操作我们都默认一个前提,即您已经位于想要执行命令的目录下,但是如何才能高效地在目录间随意切换呢?有很多简便的方法可以做到,比如设置alias,使用 ln -s 创建符号连接等。而开发者们已经想到了很多更为精妙的解决方案。
由于本课程的目的是尽可能对你的日常习惯进行优化。因此,我们可以使用fasd和 autojump 这两个工具来查找最常用或最近使用的文件和目录。
Fasd 基于 frecency 对文件和文件排序,也就是说它会同时针对频率(frequency)和时效(recency)进行排序。默认情况下,fasd使用命令 z 帮助我们快速切换到最常访问的目录。例如, 如果您经常访问/home/user/files/cool_project 目录,那么可以直接使用 z cool 跳转到该目录。对于 autojump,则使用j cool代替即可。
还有一些更复杂的工具可以用来概览目录结构,例如 tree, broot 或更加完整的文件管理器,例如 nnn 或 ranger。
















 1149
1149

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











