









首先要明确一点,这个搭建的是自己的API服务器;不是什么科大讯飞、百度语音这种付费API,而且那是直接使用别人的API,这是搭建自己的API,相比之下还是有区别的
材料准备
云服务器 (本人使用的的是阿里云服务器 Ubuntu(Linux操作系统))
环境搭建
1. Python 3.7
话不多说直接上代码
sudo su
yum -y install git
yum -y install gcc
yum -y install zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel gdbm-devel db4-devel libpcap-devel xz-devel libffi-devel
wget https://www.python.org/ftp/python/3.7.3/Python-3.7.3.tgz
tar -zxvf Python-3.7.3.tgz
mkdir /usr/local/python3
cd Python-3.7.3
./configure --prefix=/usr/local/python3
make && make install
ln -s /usr/local/python3/bin/python3.7 /usr/bin/python3
ln -s /usr/local/python3/bin/pip3.7 /usr/bin/pip3
到这里python 3.7 的环境搭建完毕
测试一下
输入python3回车
ctrl+Z 退出python编辑器
2. 使用pip3一键安装其他环境
在当前所在的目录下新建一个libs.txt文件
libs.txt文件中内容如下:
absl-py==0.8.1
astor==0.8.0
certifi==2019.9.11
cycler==0.10.0
gast==0.2.2
google-pasta==0.1.7
grpcio==1.24.1
h5py==2.10.0
Keras-Applications==1.0.8
Keras-Preprocessing==1.1.0
kiwisolver==1.3.1
Markdown==3.1.1
matplotlib==3.4.2
numpy==1.17.2
opt-einsum==3.1.0
Pillow==8.2.0
protobuf==3.10.0
pyparsing==2.4.7
python-dateutil==2.8.1
python-speech-features==0.6
scipy==1.6.3
six==1.12.0
tensorboard==2.0.0
tensorflow-estimator==2.0.0
tensorflow==2.0.0
termcolor==1.1.0
Werkzeug==0.16.0
wrapt==1.11.2
Keras==2.2.4
tensorflow-cpu==1.4.0
保存之后,输入 pip3 install -r libs.txt 回车
然后,见证奇迹,如果没报错,恭喜你,环境已经配置成功了
如果。。。呸呸呸!哪有那么多如果 o(´^`)o
下载ASRT开源项目
cd ..
wget https://d.ailemon.net/asrt_released/ASRT_v0.6.1.zip
yum install -y unzip
unzip ASRT_v0.6.1.zip
cd ASRT_v0.6.1
运行API服务器
让项目可以在后台一直运行
yum install screen
screen -S ASRT_1
在打开的新窗口中输入以下代码运行服务器
python3 asrserver.py
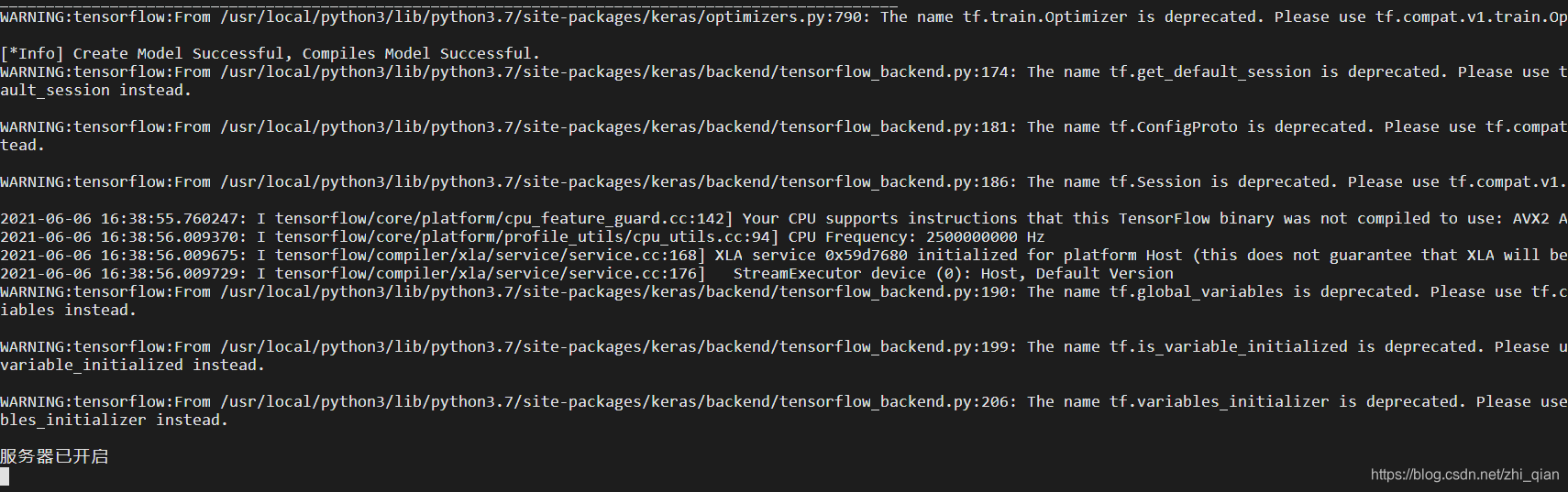
出现图中服务器已开启则证明服务器已成功运行
这时候点击 ctrl+A+D 键,在不关闭该程序的情况下离开该窗口
配置开放20000端口
这个开放的端口号需要到asrserver.py文件中修改(默认是20000)
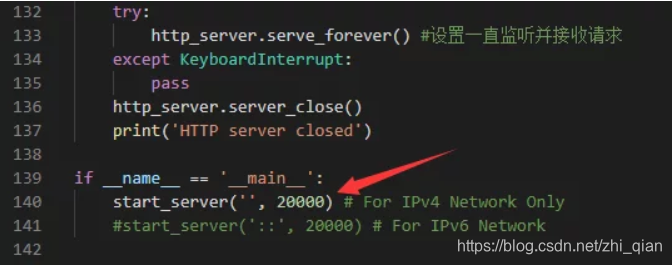
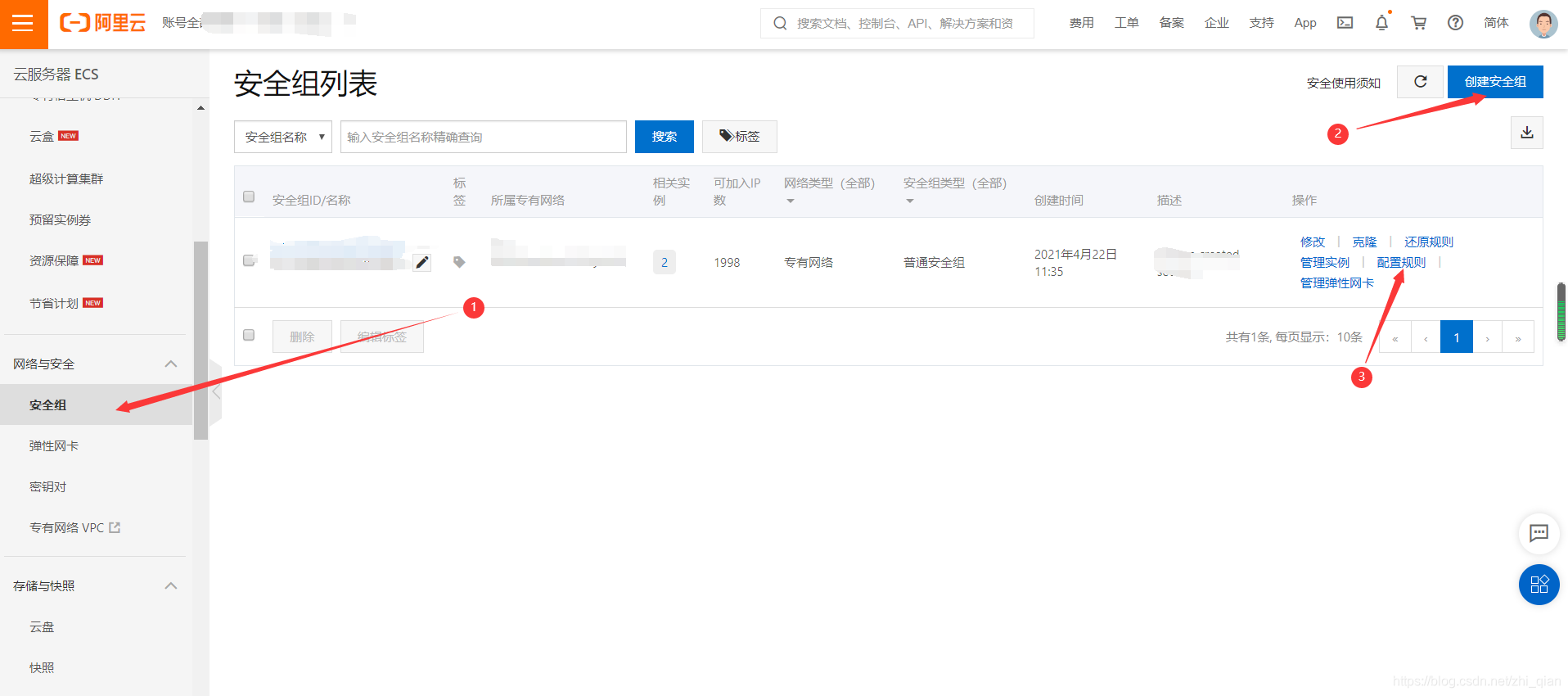
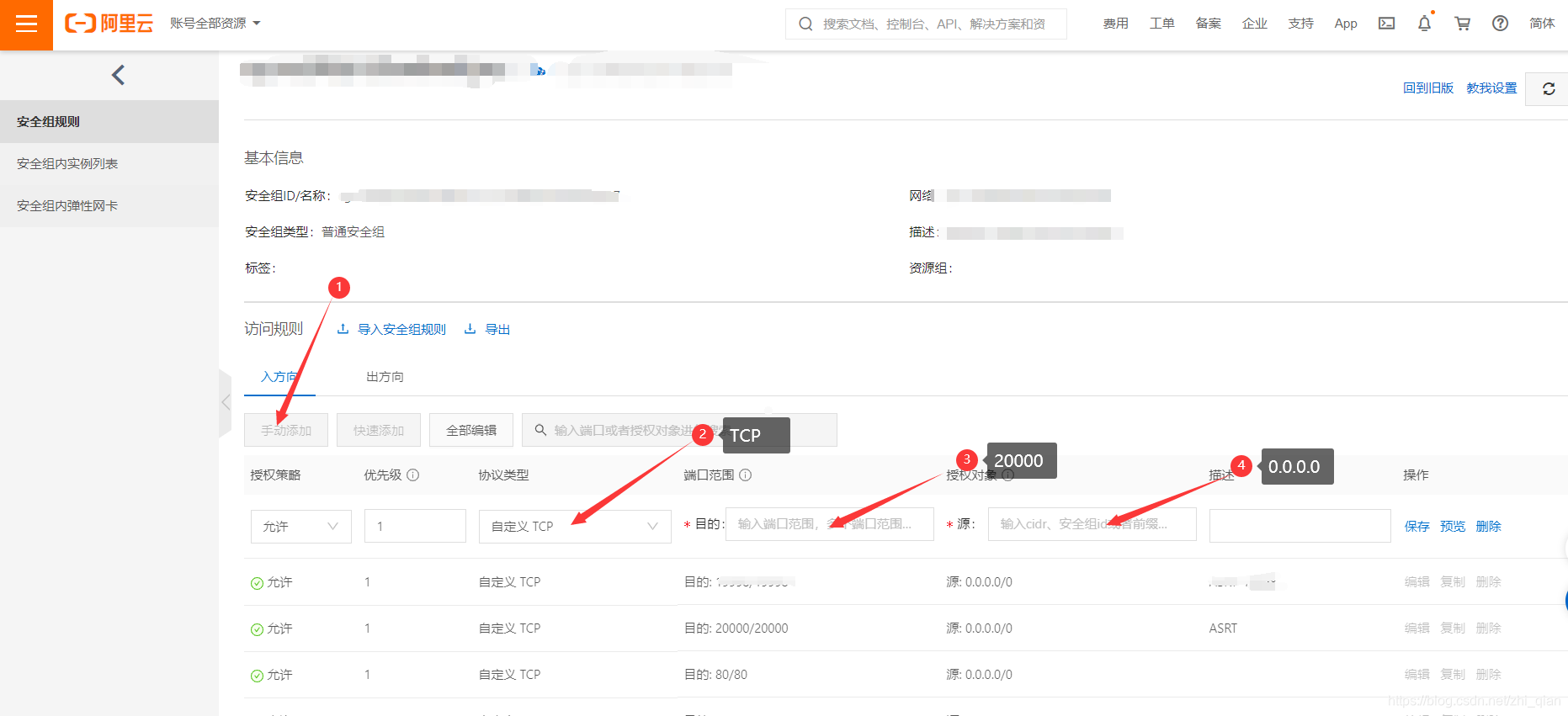
保存后就搭建完成了
API测试
-
打开浏览器,访问http://xxx.xxx.xxx.xxx:20000/ (前面的XXX是您服务器的IPV4地址)
访问到的界面如下:

则证明API部署成功 -
接下来测试一下API效果
打开API测试工具,根据使用说明操作。

测试工具免费下载 -
使用项目testClient.py代码,上传指定路径音频转文字测试
测试代码如下:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import wave
import numpy as np
import requests
def main():
url = 'https://api.ailemon.net/asrt/v1/' # 测试API接口地址,如果使用自己的请注释
# url = 'http://127.0.0.1:666/'
# url = 'http://xxx.xxx.xxx.xxx:20000/' # 修改为自己的API接口,并取消注释
token = 'qwertasd'
wavsignal, fs = read_wav_data('D:\\lfasr.wav') # 音频文件路径
print(wavsignal, fs)
datas = {'token': token, 'fs': fs, 'wavs': wavsignal}
print("类型:", type(datas))
print("datas:", datas)
r = requests.post(url, datas)
r.encoding = 'utf-8'
print("识别结果:", r.text)
def read_wav_data(filename):
'''
读取一个wav文件,返回声音信号的时域谱矩阵和播放时间
'''
wav = wave.open(filename, "rb") # 打开一个wav格式的声音文件流
num_frame = wav.getnframes() # 获取帧数
num_channel = wav.getnchannels() # 获取声道数
framerate = wav.getframerate() # 获取帧速率
num_sample_width = wav.getsampwidth() # 获取实例的比特宽度,即每一帧的字节数
str_data = wav.readframes(num_frame) # 读取全部的帧
wav.close() # 关闭流
wave_data = np.frombuffer(str_data, dtype=np.short) # 将声音文件数据转换为数组矩阵形式
wave_data.shape = -1, num_channel # 按照声道数将数组整形,单声道时候是一列数组,双声道时候是两列的矩阵
wave_data = wave_data.T # 将矩阵转置
# wave_data = wave_data
return wave_data, framerate
if __name__ == '__main__':
main()
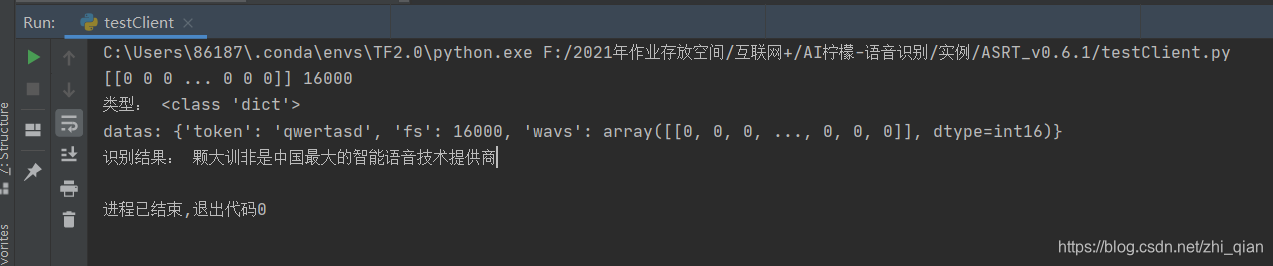
测试结果如下:














 140
140











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









