







主从同步
mysql主从同步的核心是其二进制日志文件binlog,该文件中记录了所有的 DDL(数据定义语言)语句和 DML(数据操纵语言)语句,但不包括数据查询(SELECT、SHOW)语句。
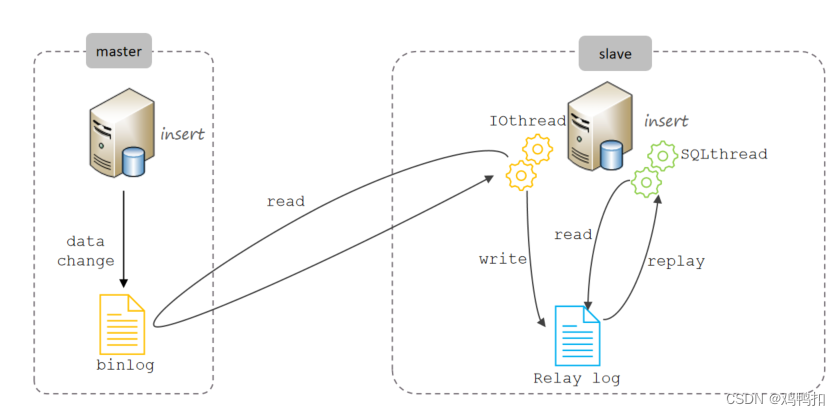
复制分成三步:
- Master 主库在事务提交时,会把数据变更记录在二进制日志文件 Binlog 中。
- 从库通过IOthread读取主库的二进制日志文件 Binlog ,写入到从库的中继日志 Relay Log 。
- 从库再通过SQLthread重做中继日志中的事件,从而改变自己原有的数据。
注意:binlog是mysql的日志,redo log和undo log是InnoDB的日志。
分库分表
主从结构一般只能分担部分访问压力,但是如果数据量过多,有存储压力,或者用户过多,遇到了CPU或者IO的瓶颈,那么我们就需要分库分表。一般来说,单表的数据达到一千万或者20G之后,我们就需要分库分表。
拆分策略
分库分表的拆分策略分为
- 垂直分库
- 垂直分表
- 水平分库
- 水平分表
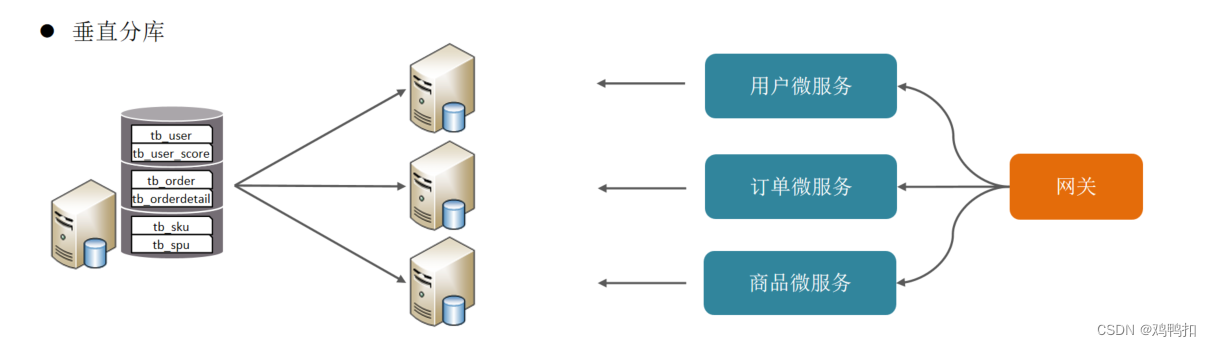
垂直分库
垂直分库:以表为依据,根据业务将不同表拆分到不同库中。
特点:
- 按业务对数据分级管理、维护、监控、扩展
- 在高并发下,提高磁盘IO和数据量连接数
垂直分表
垂直分表:以字段为依据,根据字段属性将不同字段拆分到不同表中(可以是同一个库)
一般是把不常用的字段单独放在一张表,或者把一些大字段拆分出来放在附表中。
特点:
- 冷热数据分离
- 减少IO过渡争抢,两表互不影响。
水平分库
水平分库:将一个库的数据拆分到多个库中。
常见路由规则
- 根据id节点取模(和redis的分片集群差不多)
- 按id也就是范围路由,节点1(1-100万 ),节点2(100万-200万)
特点:
- 解决了单库大数量,高并发的性能瓶颈问题
- 提高了系统的稳定性和可用性

水平分表
水平分表:将一个表的数据拆分到多个表中(可以在同一个库内)。
常见路由规则
- 根据id节点取模(和redis的分片集群差不多)
- 按id也就是范围路由,节点1(1-100万 ),节点2(100万-200万)
特点:
- 优化单一表数据量过大而产生的性能问题;
- 避免IO争抢并减少锁表的几率;
总结
1,水平分库,将一个库的数据拆分到多个库中,解决海量数据存储和高并发的问题
2,水平分表,解决单表存储和性能的问题
3,垂直分库,根据业务进行拆分,高并发下提高磁盘IO和网络连接数
4,垂直分表,冷热数据分离,多表互不影响
分库引发的新问题和解决方法
分库之后可能出现的问题如下:
-
分布式事务一致性问题
假设现在垂直分库,有订单对应的订单表在A库,有用户对应的用户表在B库。我有一个事务涉及到订单表和用户表,即需要同时操作多个在不同库中的表,因为每个库都有属于自己的事务,那么如果只有一个库提交失败,其他都提交成功,就会产生分布式事务不一致的问题。 -
跨节点关联查询
A库和B库中的不同的表要进行关联。 -
跨节点分页、排序函数
即使做了取模,也不好分页。 -
主键避重
每个表中的主键可能重复。
解决方法,使用中间件sharding-sphere或者mycat,一个是本地拦截处理(sharding-jdbc),一个是服务器端拦截处理(mycat)
mycat
MyCat 属于服务器端的数据库中间件,可以通过代码直连数据库,通过改写SQL分发,以保证数据的安全。它复写了MyCat协议,将MyCat server伪装成一个 MyCat 数据库。这种操作会导致它的效率偏低,损耗略高。不过,它无须修改代码,比较方便。相比于只支持java的sharding-sphere,它跨语言,跨平台,跨数据库的能力更加优秀。
-
分布式事务一致性问题:
MyCat支持两阶段提交(2PC)协议,可以确保分布式事务的一致性。 -
跨节点关联查询:
MyCat提供了全局表(Global Table)的概念,通过在MyCat中定义全局表,可以将跨节点的关联查询转化为本地查询,实现数据的关联获取。 -
跨节点分页、排序函数:
MyCat提供了特定的函数和语法来处理,例如SEQ_NEXTVAL函数等。 -
主键避重:
MyCat提供了全局序列(Global Sequence)的功能,可以用于生成唯一的主键值。
相关面试题和回答
MySQL主从同步原理是什么?
候选人:
mysql主从同步的核心是其二进制日志文件binlog,该文件中记录了所有的 DDL语句和 DML语句,但不包括数据查询(SELECT、SHOW)语句。
其主从同步的过程大概分为三步:
- Master 主库在事务提交时,会把数据变更记录在二进制日志文件 Binlog 中。
- 从库通过IOthread读取主库的二进制日志文件 Binlog ,写入到从库的中继日志 Relay Log 。
- 从库再通过SQLthread重做中继日志中的事件,从而改变自己原有的数据。
你们项目用过MySQL的分库分表吗?
候选人:
嗯,因为我们都是微服务开发,每个微服务对应了一个数据库,是根据业务进行拆分的,这个其实就是垂直拆分。
那你之前使用过水平分库吗?
候选人:
嗯,这个是使用过的,我们当时的业务是(xxx),一开始,我们也是单库,后来这个业务逐渐发展,业务量上来的很迅速,其中(xx)表已经存放了超过1000万的数据,我们做了很多优化也不好使,性能依然很慢,所以当时就使用了水平分库。
我们一开始先做了3台服务器对应了3个数据库,由于库多了,需要分片,我们当时采用的mycat来作为数据库的中间件。数据都是按照id(自增)取模的方式来存取的。
当然一开始的时候,那些旧数据,我们做了一些清洗的工作,我们也是按照id取模规则分别存储到了各个数据库中,好处就是可以让各个数据库分摊存储和读取的压力,解决了我们当时性能的问题
















 1479
1479











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











