







目录
最大匹配算法(Max Matching)

前向最大匹配算法(Forward Max Matching)

Java实现:
package NLP.NLP04;
import java.util.*;
public class NLP04_FMM {
private final Set<String> Dictionary = new HashSet<>();
/**
* 添加词库
*/
public void setDictionary(String[] words) {
Collections.addAll(this.Dictionary, words);
}
/**
* 正向最大匹配Forward Maximum Matching
*
* @param sentence 要分词的句子
* @param maxSize 词的最大长度
*/
public String[] positiveSplit(String sentence, int maxSize) {
List<String> result = new ArrayList<>();
while (sentence.length() > 0) {
String forward_maxSize = sentence.substring(0, Math.min(maxSize, sentence.length()));//先取这句话的前maxSize个字
while (!Dictionary.contains(forward_maxSize)) {//如果这些截取的字组成的词不在词典中
if (forward_maxSize.length() > 1) {
forward_maxSize = forward_maxSize.substring(0, forward_maxSize.length() - 1);//把这个前缀部分从尾部减去一个字
} else {
break;//到最后都没在词典中找到的话,退出循环,直接按照一个新词加入就行
}
}
result.add(forward_maxSize);
sentence = sentence.substring(forward_maxSize.length());//当前的句子已经匹配上一个词,要把这个词从头部减去
}
return result.toArray(new String[0]);
}
public static void main(String[] args) {
String[] words = new String[]{"他", "我", "你", "她", "呵呵", "哈哈", "中文", "字母", "数学", "吃饭", "二", "三", "读研", "究极", "去", "他们", "老人",
"走", "念书", "睡觉", "看苏", "看看", "走走", "喝水", "看电视", "手指", "脚趾", "手脚", "刚好", "好的", "并且", "短发", "滑的", "头发", "在", "吃饭",
"句子", "是", "研究", "研究生", "生物", "物化", "化学", "学", "的", "一", "位", "科学", "家", "科学家", "。", "?", "!", "吃饭饭", "睡觉觉", "恶心心"
, "边", "过年", "计算机", "计算机网络", "网络", "操作系统", "自然语言处理", "汉语", "分词", "自然", "语言", "处理"};
String[] sentences = {"他是研究生物化学的一个科学家。",
"你去研究自然语言处理。",
"她是计算机网络科学家。",
"我的头发是短发并且是滑的。",
"他边吃饭边看电视。"};
String[][] answers = {{"他", "是", "研究", "生物化学", "的", "一", "个", "科学家", "。"},
{"你", "去", "研究", "自然语言处理", "。"},
{"她", "是", "计算机", "网络", "科学家", "。"},
{"我", "的", "头发", "是", "短发", "并且", "是", "滑的", "。"},
{"他", "边", "吃饭", "边", "看", "电视", "。"}};
NLP04_FMM nlp04_fmm = new NLP04_FMM();
/*添加词到词库*/
nlp04_fmm.setDictionary(words);
int num_of_outWords = 0;
int num_of_rights = 0;
int num_of_answers = 0;
for (String sentence : sentences) {
System.out.println("sentence:" + sentence);
}
System.out.println();
for (String[] answer : answers) {
num_of_answers += answer.length;
System.out.println("answer:" + Arrays.toString(answer));
}
System.out.println();
System.out.println("FMM(正向最大匹配)分词算法:");
/*下面我指定最大词长度为7*/
for (int i = 0; i < sentences.length; i++) {
String[] FMM = nlp04_fmm.positiveSplit(sentences[i], 7);
num_of_outWords += FMM.length;
List<String> answer_list = Arrays.asList(answers[i]);
for (String result_words : FMM) {
if (answer_list.contains(result_words))
num_of_rights++;
}
System.out.println("Result:" + Arrays.toString(FMM)
.substring(1, Arrays.toString(FMM).length() - 1)
.replaceAll(", ", "/"));
}
System.out.println();
System.out.println("测试集共输出:" + num_of_outWords + "个词");
System.out.println("标准答案是:" + num_of_answers + "个词");
System.out.println("系统切分出来的结果中有" + num_of_rights + "个词是正确的");
double P = (double)num_of_rights / num_of_outWords;
double R = (double)num_of_rights / num_of_answers;
double F1 = 2 * P * R / (P + R);
System.out.println();
System.out.println("P=" + P);
System.out.println("R=" + R);
System.out.println("F1=" + F1);
}
}
测试结果

N-最短路径算法(Python实现)
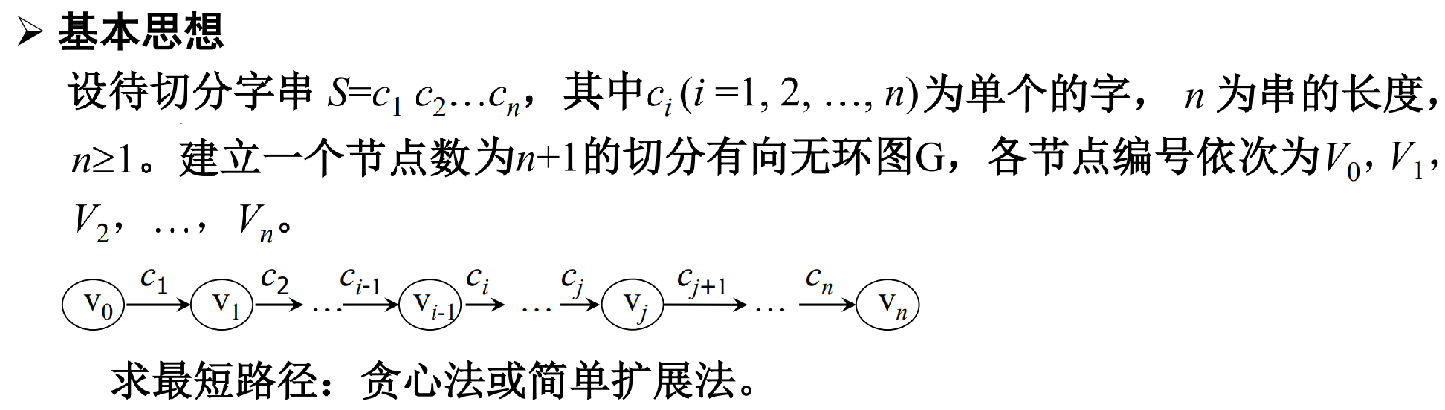
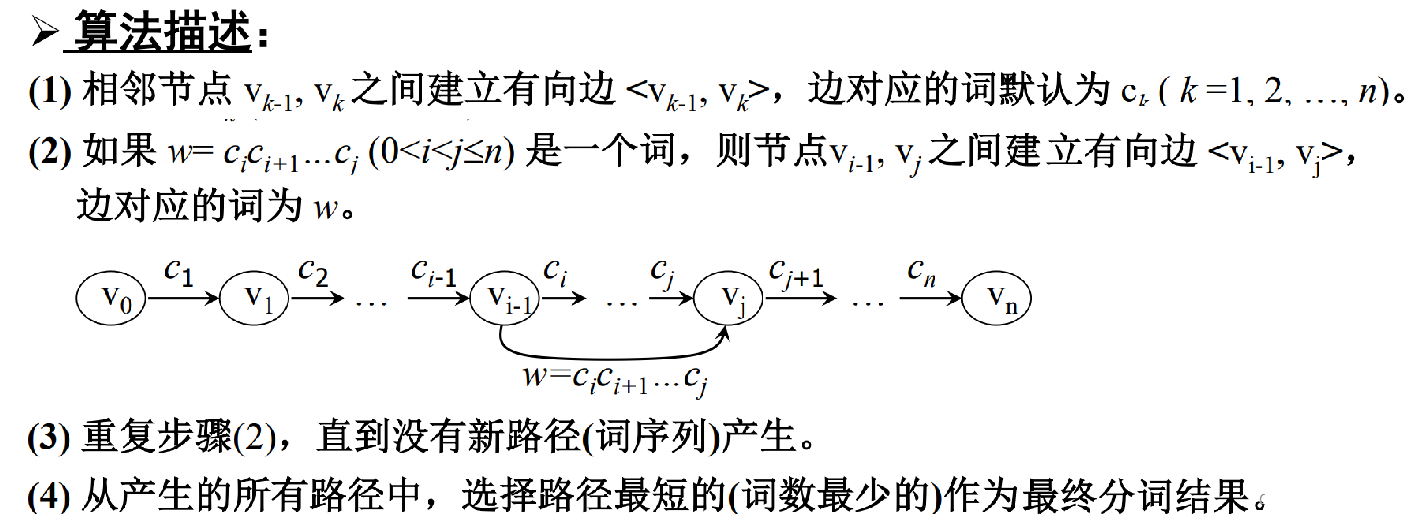
算法思想
N最短路径算法是一种基于词典的分词算法. 每个句子将生成一个有向无环图DAG, 每个字作为图的一个定点, 边代表可能的分词.

在上图中, 边的起点为词的第一个字, 边的终点为词尾的下一个字。 边1表示“我”字单字成词, 边2表示 “只是”可以作为一个单词。
每个边拥有一个权值, 表示该词出现的概率。 最简单的做法是采用词频作为权值。
N最短路径分词即在上述有向无环图中寻找N条权值和最大的路径, 路径上的边标志了最可能的分词结果。通常我们只寻找权值和最大的那一条路径。

根据上图的权值最大路径得到的分词结果为:“我/只是/做/了/一些/微小/的/工作”
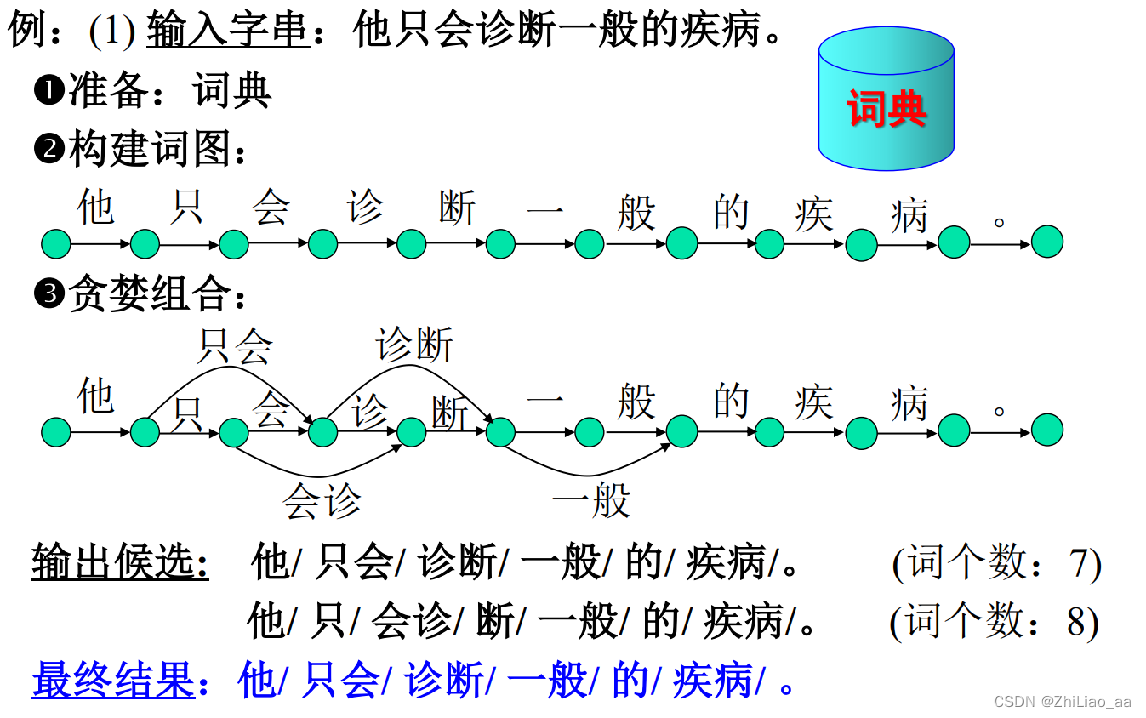
举例
评价指标


实现词典
# 词典将根据输入的文本, 统计各单词的词频:
# 得到的词频存储在Words.txt文件下
class WordDictModel:
def __init__(self):
self.word_dict = {}
self.data = None
self.stop_words = {}
def load_data(self, filename):
self.data = open(filename, "r", encoding="utf-8")
# update函数可以在原有词典的基础上, 根据新的输入更新词频.
def update(self):
# build word_dict
for line in self.data:
words = line.split(" ")
for word in words:
if word in self.stop_words:
continue
if self.word_dict.get(word):
self.word_dict[word] += 1
else:
self.word_dict[word] = 1
# 得到的词频存储在Words.txt文件下
def save(self, filename="Words.txt", code="txt"):
fw = open(filename, 'w', encoding="utf-8")
data = {
"word_dict": self.word_dict
}
for key in self.word_dict:
tmp = "%s %d\n" % (key, self.word_dict[key])
fw.write(tmp)
fw.close()
# 读取Words.txt词频文件
def load(self, filename="Words.txt", code="txt"):
fr = open(filename, 'r', encoding='utf-8')
# load model
model = {}
word_dict = {}
for line in fr:
tmp = line.split(" ")
if len(tmp) < 2:
continue
word_dict[tmp[0]] = int(tmp[1])
model = {"word_dict": word_dict}
fr.close()
# update word dict
word_dict = model["word_dict"]
for key in word_dict:
if self.word_dict.get(key):
self.word_dict[key] += word_dict[key]
else:
self.word_dict[key] = word_dict[key]
最短路径分词:
# encoding=utf-8
from Word_Dictionary import WordDictModel
# 最短路径分词
# 分词器需要继承WordDictModel, 并利用其词典. 遍历输入语句中所有子串, 并查询其词频构造有向无环图:
class DAGSegment(WordDictModel):
# 产生的dag格式:
# {
# 0: [(1, 1)],
# 1: [(2, 1), (3, 738)],
# 2: [(3, 1)],
# 3: [(4, 1)],
# 4: [(5, 1)],
# 5: [(6, 1), (7, 2309)],
# 6: [(7, 1)],
# 7: [(8, 1), (9, 304)],
# 8: [(9, 1)],
# 9: [(10, 1)],
# 10: [(11, 1), (12, 2605)],
# 11: [(12, 1)],
# }
# 字典中的值代表其键的后继顶点, 如1: [(2, 1), (3, 738)]表示顶点1到顶点2的权值为1, 到顶点3的权值为738.
def build_dag(self, sentence):
dag = {}
for start in range(len(sentence)):
unique = [start + 1]
tmp = [(start + 1, 1)]
for stop in range(start+1, len(sentence)+1):
fragment = sentence[start:stop]
num = self.word_dict.get(fragment, 0)
if num > 0 and (stop not in unique):
tmp.append((stop, num))
unique.append(stop)
dag[start] = tmp
# print(dag[start])
return dag
# 最短路径最好使用Floyd或Dijkstra算法.但其耗时太久, 大多数情况下使用贪心算法求得次优解就可以达到所需精度:
def predict(self, sentence):
Len = len(sentence)
route = [0] * Len
dag = self.build_dag(sentence) # {i: (stop, num)}
for i in range(0, Len):
route[i] = max(dag[i], key=lambda x: x[1])[0]
return route
测试结果
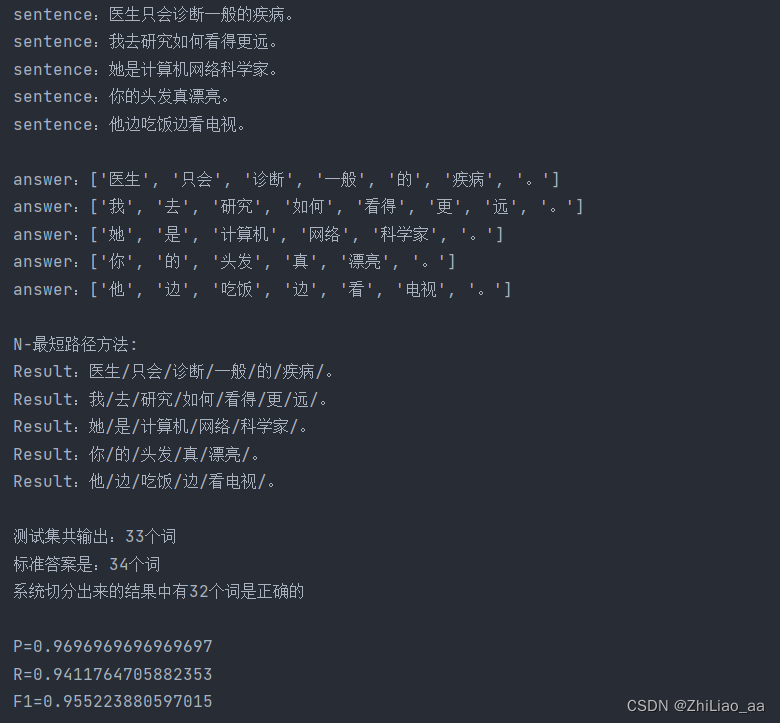
















 329
329











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











