






![]()
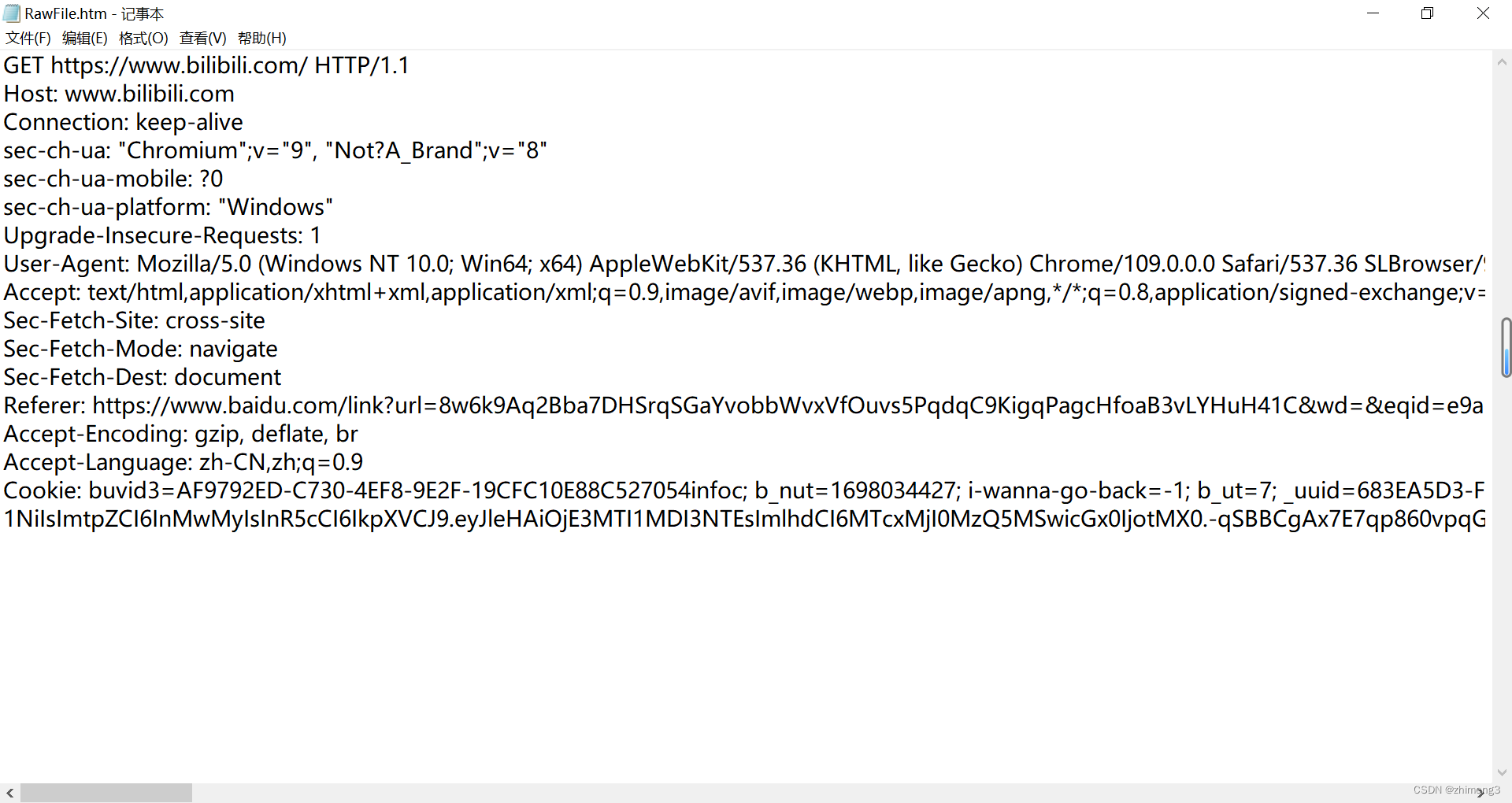
如图在要将数据传输给服务器时,通常会将用到上图中的GEA等请求。
GET请求,通常会将要传给服务器的数据,加到url的query string中body中
![]()
还有POST请求,通常把要传给服务器的数据加入到body中。
上述都是习惯用法(都是不是强制要求,可以不遵守比如)。
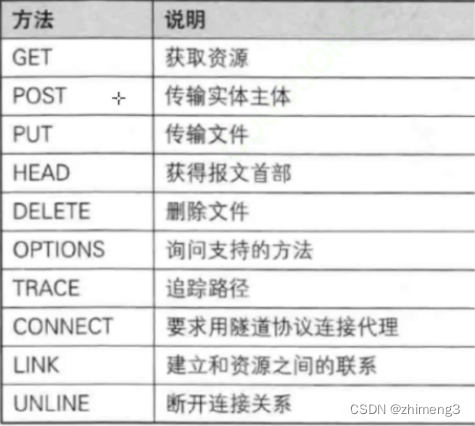
总共有上述方法,但是经常用的只有GET和POST方法其他方法基本上不用。
GET和POST的区别
GET和POST没有本质区别(双方可以替换对方的应用场景)
在使用习惯上存在差异
1.GEI经常是把传递给服务器的数据放到query string 中; POST则是经常放到body中. (使用习惯上最大的差别)
(上述情况并非绝对,GET也可以使用body,POST也可以使用query string.使用的前提是客户端/服务器都得按照一样的方式来处理代码)
2.语义上的差异.(虽然语义上HTTP的使用是比较混乱的,但是相比之下,GET和POST还是比较明确的)
GET大多数还是用来获取数据
POST大多数还是用来提交数据(登录+上传)
三条错误的说法
1.GET请求能传递的数据量有上限,POST传递的数据量没有上限.
早期版本的浏览器(由于硬件资源不足),针对GET请求的URL的长度做出了限制.
实际上,RFC标准文档中并没有明确规定URL能有多长
目前的浏览器和服务器的实现过程中, URL可以非常长的.(甚至说可以使用URL传递一些图片这样的数据
2.GET请求传递数据不安全.POST请求传递数据更安全
如果使用GET请求来实现登录
点击登录的时候,就会把用户名和密码放到url中,进一步的显示到浏览器地址栏里.(不就被别人看到了吗)相比之下,POST 则是在body中,不会在界面上显示出来,所以就更安全
(通常说的“安全”指的是你传递的数据,不容易被黑客获取.或者被黑客获取到之后,不容易被破解)
3.GET 只能给服务器传输文本数据.POST可以给服务器传输文本和二进制数据.
1)GET也不是不能使用body(body中是可以直接放二进制的)
2) GET也可以把二进制的数据进行base64转码,放到url的query string 中.
1.GET请求是幂等的.POST请求不是幂等的.
(幂等是一个数学概念就是输入相同的内容,输出是稳定的)也就是说这种请求很稳定出现错误的情况很低.
GET和POST具体是否是幂等,取决于代码的实现GET是否幂等,
也不绝对.只不过RFC标准文档上建议GET请求实现成幂等的
如B站的每次进入B站之后的请求不可能是幂等,如果幂等那么每次视频都一样违背了他做视频网站的初心。
2.GET请求可以被浏览器缓存,POST不可以被缓存
幂等性的延续.如果请求是幂等,自然就可以缓存
3.GET请求可以被浏览器收藏夹收藏,POST不能收藏,收藏的时候可能会丢失 body
Header
Header里的键值对是很多的.以下是其重要键值对的一部分
![]()
这个信息也是存在于url中。
但是,在使用代理的情况下,
Host的内容是可能和url中的内容不同的.
![]()
body中的数据格式
![]()
body的数据长度
只有请求中有body,才会有这两个属性
通常情况下GET请求没有body; POST请求有body
body中的格式,方式很多
请求:
1. json
2. form表单的格式
3. form-data的格式
响应:
1.html
2.css
3. js
4. json
5.图片
后续给服务器提交给请求,不同的Content-Type,服务器处理数据的逻辑是不同的
服务器返回数据给浏览器,也需要设置合适的Content-Type,
浏览器也会根据不同的Content-Type做出不同的处理
TCP涉及到粘包问题.
HTTP在传输层就是基于TCP的.
使用同一个TCP连接,传输多个HTTP数据包, 此时,就会使多个HTTP数据包在TCP接收缓冲区中挨在一起.
接收方解析的时候,就需要能够清楚HTTP数据包之间的边界.
对于GET这种没有body的请求,直接使用空行(分隔符)
对于POST这种有body的请求,就结合空行和Content-Length
User-Agent(简称UA)
![]()
其描述了使用什么设备来进行上网
很早以前,网页非常简单,就只是一些单纯的文字.浏览器功能也比较原始.
后来,网页内容越来越丰富了,浏览器的功能也开始逐渐升级.
1)显示图片2)支持样式3)支持js4)支持多媒体5等
由于这个升级过程很快的.(新的浏览器出现的很快)
新的浏览器诞生之后,并不是立即就占据全部市场.相当一部分时间里新浏览器和旧浏览器,并存的.
网站的开发者就遇到困难了.网站并发者就需要考虑到,是否要兼容旧版本浏览器?
事实上,可以使用User-Agent来进行区分的.
由于UA中记录了浏览器的版本.哪个版本的浏览器都支持哪些特性,
网站开发者就可以通过看UA里的内容来进行区分
现在,浏览器之间的差异非常小了.此时,UA的作用就没那么关键了.
现在UA主要是用来区分PC端还是移动端
Referer
描述了当前页面是从哪个页面跳转来的.
如果是直接在地址栏输入url(或者点击收藏夹中的按钮)都是没有Referer.

cookie
Cookie可以认为是浏览器在本地存储数据的一种机制.
浏览器的数据来自于服务器.
浏览器后续的操作也是要提交给服务器的.
服务器这边管理了一个网站的各种核心数据
在程序运行过程中,会有一些数据,需要在浏览器这边存储的.并且在后续请求的时候数据可能需要再发给服务器上次登陆时间.上次访问时间.用户的身份信息.累计的访问次数等
(临时性的数据.存储在浏览器比较合适的.)
实际上更容易想到的是,把这样的数据直接存储到本地文件中~~
但是实际上不可行的.浏览器为了考虑到安全性禁止网页直接访问你的电脑的文件系统中也就无法直接生成一个硬盘的文件来存储数据了.
怕访问某个网站,结果网页里有病毒,读取到个人隐私.
为了保证安全性,又能进行存储数据,于是就引入了Cookie
(也是按照硬盘文件的方式保存的,但是浏览器把操作文件给封装了网页只能往Cookie中存储键值对)
Cookie往往是从服务器返回的数据(也可以是页面自己生成的)
Cookie的值每次登入网页会进行刷新来改变上一次保存的信息。
Cookie存储到浏览器所在主机的硬盘上.并且是按照域名为维度来存储的.
(每个域名下可以存自己的Cookie,彼此之间不影响)
Cookie是按照键值对的形式来组织的.这里的键值对也都是程序猿自定义的(和query string差不多)
后续再请求这个服务器的时候,就会把Cookie 中的内容自动代入到请求中,发给服务器.
服务器通过Cookie的内容做一些逻辑上的处理.
![]()
键值对之间,使用;分割.键和值使用=分割,这些内容就是浏览器本地存储的cookie,都会再后续请求服务器的时候,把这些内容给代入到请求中,传给服务器














 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









