







存储过程就是一条或者多条SQL语句的集合,可视为批文件。
创建存储过程
创建存储过程,需要使用CREATE PROCEDURE语句,基本语法格式如下:
CREATE PROCEDURE sp_name ( [proc_parameter] ) [characteristice...] routine_body
CREATE PROCEDURE为用来创建存储过程的关键字;
sp_name为存储过程的名称;
proc_parameter为指定存储过程的参数列表,列表形式如下:
[ IN | OUT | INOUT ] param_name type
其中,IN表示输入参数,OUT表示输出参数,INOUT表示既可以输入也可以输出;
param_name表示参数名称;
type 表示参数的类型,该类型可以是MySQL数据库中的任意类型。
characteristics指定存储过程的特性;
routine_body是SQL代码的内容,可以用BEGIN…END来表示SQL代码的开始和结束。
DELIMITER // 语句的作用是将MySQL的结束符设置为//,因为MySQL默认的语句结束符号为分号;,为了避免与存储过程中SQL语句结束符相冲突,需要使用DELIMITER改变存储过程的结束符,并以"END //"介绍存储过程。存储过程定义完毕之后再使用DELIMITER ;恢复默认结束符。DELIMITER也可以指定其他符号作为结束符。
直接在Shell里可以这么写:
注意DELIMITER ;中间必须有空格键。
mysql> DELIMITER //
mysql> CREATE PROCEDURE proc()
-> BEGIN
-> SELECT * FROM fruits;
-> END //
Query OK, 0 rows affected (0.01 sec)
mysql> DELIMITER ;
如果有MySQL工具,写起来就比较方便了
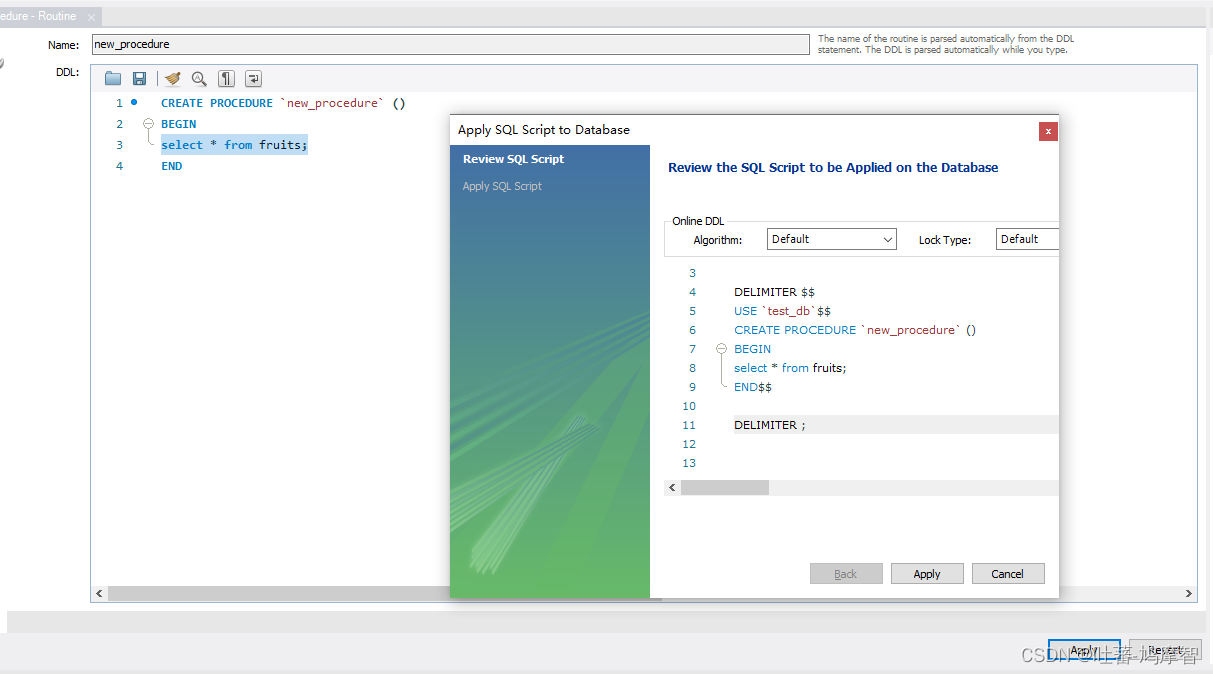
创建存储函数
创建存储函数,需要使用CREATE FUNCTION语句,基本语法格式如下:
mysql> CREATE FUNCTION func_name ( [func_parameter] )
-> RETURNS type
-> [characteristic ...] routine_body
CREATE FUNCTION为用来创建存储函数的关键字;
func_name为存储函数的名称;
func_parameter为指定存储函数的参数列表,列表形式如下:
[ IN | OUT | INOUT ] param_name type
其中,IN表示输入参数,OUT表示输出参数,INOUT表示既可以输入也可以输出;
param_name表示参数名称;
RETURNS type 表示函数返回数据的类型;
characteristics指定存储函数的特性。
USE `test_db`;
DROP function IF EXISTS `new_function`;
DELIMITER $$
USE `test_db`$$
CREATE FUNCTION `new_function` ()
RETURNS char(50)
BEGIN
RETURN (SELECT f_name FROM fruits WHERE s_id = 101);
END$$
DELIMITER ;
变量的使用
变量可以在子程序中声明并使用,变量的作用范围是在BEGIN…END程序中
在存储过程中使用DECLARE语句定义变量
定义变量
mysql> DECLARE myparam INT DEFAULT 100;
为变量赋值
mysql> DECLARE var1,var2,var3 INT;
mysql> SET var1 = 10, var2=20;
mysql> SET var3 = var1 + var2;
调用存储过程和函数
存储过程必须使用CALL语句调用,并且存储过程和数据库相关,如果要执行其他数据库中的存储过程,需要指定数据库名称,例如CALL dbname.procname.
示例:
mysql> use test_db;
Database changed
mysql> CALL AvgFruitPrice();
+------+------+------------+---------+
| f_id | s_id | f_name | f_price |
+------+------+------------+---------+
| a1 | 101 | apple | 5.20 |
| a2 | 103 | apricot | 2.20 |
| b1 | 101 | blackberry | 10.20 |
| b2 | 104 | berry | 7.60 |
| b5 | 107 | xxxx | 3.60 |
| bs1 | 102 | orange | 11.20 |
| bs2 | 105 | melon | 8.20 |
| c0 | 101 | cherry | 3.20 |
| l2 | 104 | lemon | 6.40 |
| m1 | 106 | mango | 15.70 |
| m2 | 105 | xbabay | 2.60 |
| m3 | 105 | xxtt | 11.60 |
| o2 | 103 | coconut | 9.20 |
| t1 | 102 | banana | 10.30 |
| t2 | 102 | grape | 5.30 |
| t4 | 107 | xbababa | 3.60 |
+------+------+------------+---------+
16 rows in set (0.01 sec)
Query OK, 0 rows affected (0.01 sec)
DELIMITER $$
CREATE FUNCTION `new_function`(sid integer) RETURNS int
BEGIN
RETURN (SELECT COUNT(*) FROM test_db.fruits WHERE s_id = sid);
END$$
DELIMITER ;
注意:set global log_bin_trust_function_creators=TRUE;
调用存储函数
mysql> SELECT new_function(101);
+-------------------+
| new_function(101) |
+-------------------+
| 3 |
+-------------------+
1 row in set (0.01 sec)
删除存储过程和函数
mysql> DROP PROCEDURE AvgFruitPrice333;
Query OK, 0 rows affected (0.08 sec)
mysql> DROP FUNCTION new_function;
Query OK, 0 rows affected (0.01 sec)
















 310
310











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









