







理论
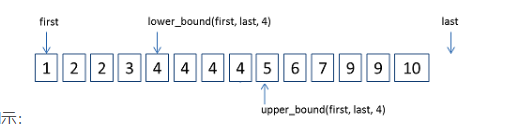
lower_bound( )和upper_bound( )都是利用二分查找的方法在一个排好序的数组中进行查找的。
在从小到大的排序数组中,
-
lower_bound( begin,end,num):从数组的begin位置到end-1位置二分查找第一个大于或等于num的数字,如果找到返回找到元素的地址否则返回last的地址。(这样不注意的话会越界,小心)。通过返回的地址减去起始地址begin,得到找到数字在数组中的下标。
-
upper_bound( begin,end,num):从数组的begin位置到end-1位置二分查找第一个大于num的数字,如果找到返回找到元素的地址否则返回last的地址。(同样这样不注意的话会越界,小心)。通过返回的地址减去起始地址begin,得到找到数字在数组中的下标。
在从大到小的排序数组中,重载lower_bound()和upper_bound()
-
lower_bound( begin,end,num,greater() ):从数组的begin位置到end-1位置二分查找第一个小于或等于num的数字,找到返回该数字的地址,不存在则返回end。通过返回的地址减去起始地址begin,得到找到数字在数组中的下标。
-
upper_bound( begin,end,num,greater() ):从数组的begin位置到end-1位置二分查找第一个小于num的数字,找到返回该数字的地址,不存在则返回end。通过返回的地址减去起始地址begin,得到找到数字在数组中的下标。
时间复杂度:一次查询O(log n),n为数组长度。
示例
第一个例子
#include <iostream>
#include <algorithm>
#include <vector>
using namespace std;
int main(){
vector<int> v= {3,4,1,2,8, 1, 2};
//先排序
sort(v.begin(),v.end()); // 1, 1 , 2, 2 3 4 8
std::vector<int>::iterator iter1, iter2, iter3, iter4, iter5;
iter1 = lower_bound(v.begin(),v.end(),-1) ;//1
iter2 = lower_bound(v.begin(),v.end(),1); // 1
iter3 = lower_bound(v.begin(),v.end(),2); // 2
iter4 = lower_bound(v.begin(),v.end(),8); // 8
iter5 = lower_bound(v.begin(),v.end(),9); // 无效
if(iter1 == v.end()){
printf("找不到, iter1无效, 会越界: %d\r\n", iter1 - v.begin());
}else{
printf("iter1 = [%d]\r\n", v[iter1 - v.begin()]);
}
if(iter2 == v.end()){
printf("找不到, iter2无效, 会越界: %d\r\n", iter2 - v.begin());
}else{
printf("iter2 = [%d]\r\n", v[iter2 - v.begin()]);
}
if(iter3 == v.end()){
printf("找不到, iter3无效, 会越界: %d\r\n", iter3 - v.begin());
}else{
printf("iter3 = [%d]\r\n", v[iter3 - v.begin()]);
}
// 1 2 3 4 8
if(iter4 == v.end()){
printf("找不到, iter4无效, 会越界: %d\r\n", iter4 - v.begin());
}else{
printf("iter4 = [%d]\r\n", v[iter4 - v.begin()]);
}
if(iter5 == v.end()){
printf("找不到, iter5无效, 会越界: %d\r\n", iter5 - v.begin());
}else{
printf("iter5 = [%d]\r\n", v[iter5 - v.begin()]);
}
}
第二个例子
#include <iostream>
#include <algorithm>
#include <vector>
using namespace std;
int main(){
vector<int> v= {3,4,1,2,8, 1, 2};
//先排序
sort(v.begin(),v.end()); // 1, 1 , 2, 2 3 4 8
std::vector<int>::iterator iter1, iter2, iter3, iter4, iter5;
//less<int>() 是建小堆,排升序。
iter1 = lower_bound(v.begin(),v.end(),-1, less<int>()) ;//1
iter2 = lower_bound(v.begin(),v.end(),1, less<int>()); // 1
iter3 = lower_bound(v.begin(),v.end(),2, less<int>()); // 2
iter4 = lower_bound(v.begin(),v.end(),8, less<int>()); // 8
iter5 = lower_bound(v.begin(),v.end(),9, less<int>()); // 无效
if(iter1 == v.end()){
printf("找不到, iter1无效, 会越界: %d\r\n", iter1 - v.begin());
}else{
printf("iter1 = [%d]\r\n", v[iter1 - v.begin()]);
}
if(iter2 == v.end()){
printf("找不到, iter2无效, 会越界: %d\r\n", iter2 - v.begin());
}else{
printf("iter2 = [%d]\r\n", v[iter2 - v.begin()]);
}
if(iter3 == v.end()){
printf("找不到, iter3无效, 会越界: %d\r\n", iter3 - v.begin());
}else{
printf("iter3 = [%d]\r\n", v[iter3 - v.begin()]);
}
// 1 2 3 4 8
if(iter4 == v.end()){
printf("找不到, iter4无效, 会越界: %d\r\n", iter4 - v.begin());
}else{
printf("iter4 = [%d]\r\n", v[iter4 - v.begin()]);
}
if(iter5 == v.end()){
printf("找不到, iter5无效, 会越界: %d\r\n", iter5 - v.begin());
}else{
printf("iter5 = [%d]\r\n", v[iter5 - v.begin()]);
}
}
第三个例子:仿函数传参
typedef struct Student
{
int _id; //学号
int _num; //排名
Student(int id, int num)
:_id(id)
, _num(num)
{}
}Stu;
struct CompareV
{
bool operator() (const Stu& s1, const Stu& s2)// 排名升序
{
return s1._num < s2._num;
}
};
int main()
{
vector<Stu> vS = { { 101, 34 }, { 103, 39 }, { 102, 35 } };
//CompareV()排完序后是这个丫子
//101 34
//102 35
//103 39
auto iter = lower_bound(vS.begin(), vS.end(), Stu(200,33), CompareV());
cout << iter - vS.begin() << endl; //我们就找到了按仿函数排序(找排名比33大的位置 就是0)
system("pause");
}
lower_bound的底层实现
它底层实际上是一个二分查找
int lower_bound(vector<int>& nums, int x) {
int left = 0;
int right = nums.size() - 1;
while (left <= right) {
int mid = left +(right - left) / 2;
if (x > nums[mid]) {
left = mid + 1;
}
else {
right = mid - 1;
}
}
return left;
}















 1183
1183











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









