







入门
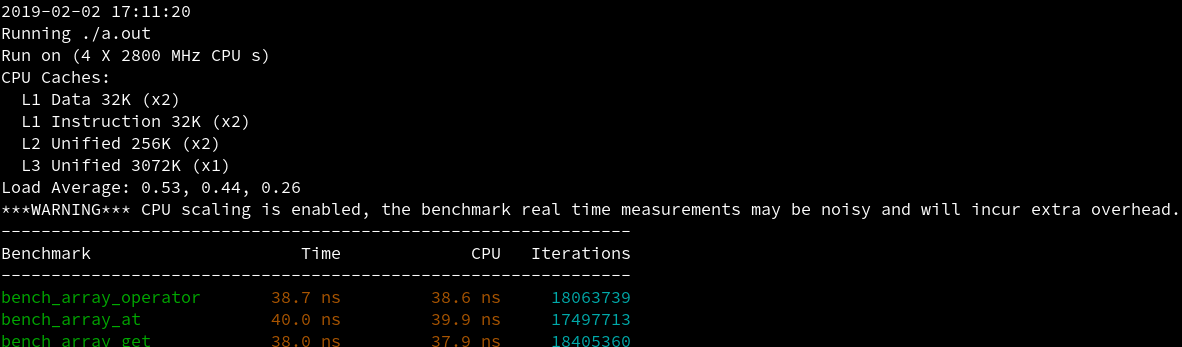
我们的例子将会对比三种访问std::array容器内元素方法的性能,进而演示benchmark的使用方法。
#include <benchmark/benchmark.h>
#include <array>
constexpr int len = 6;
// constexpr function具有inline属性,你应该把它放在头文件中
constexpr auto my_pow(const int i)
{
return i * i;
}
// 使用operator[]读取元素,依次存入1-6的平方
static void bench_array_operator(benchmark::State& state)
{
std::array<int, len> arr;
constexpr int i = 1;
for (auto _: state) {
arr[0] = my_pow(i);
arr[1] = my_pow(i+1);
arr[2] = my_pow(i+2);
arr[3] = my_pow(i+3);
arr[4] = my_pow(i+4);
arr[5] = my_pow(i+5);
}
}
BENCHMARK(bench_array_operator);
// 使用at()读取元素,依次存入1-6的平方
static void bench_array_at(benchmark::State& state)
{
std::array<int, len> arr;
constexpr int i = 1;
for (auto _: state) {
arr.at(0) = my_pow(i);
arr.at(1) = my_pow(i+1);
arr.at(2) = my_pow(i+2);
arr.at(3) = my_pow(i+3);
arr.at(4) = my_pow(i+4);
arr.at(5) = my_pow(i+5);
}
}
BENCHMARK(bench_array_at);
// std::get<>(array)是一个constexpr function,它会返回容器内元素的引用,并在编译期检查数组的索引是否正确
static void bench_array_get(benchmark::State& state)
{
std::array<int, len> arr;
constexpr int i = 1;
for (auto _: state) {
std::get<0>(arr) = my_pow(i);
std::get<1>(arr) = my_pow(i+1);
std::get<2>(arr) = my_pow(i+2);
std::get<3>(arr) = my_pow(i+3);
std::get<4>(arr) = my_pow(i+4);
std::get<5>(arr) = my_pow(i+5);
}
}
BENCHMARK(bench_array_get);
BENCHMARK_MAIN();
我们可以看到每一个benchmark测试用例都是一个类型为std::function<void(benchmark::State&)>的函数,其中benchmark::State&负责测试的运行及额外参数的传递。
随后我们使用for (auto _: state) {}来运行需要测试的内容,state会选择合适的次数来运行循环,时间的计算从循环内的语句开始,所以我们可以选择像例子中一样在for循环之外初始化测试环境,然后在循环体内编写需要测试的代码。
测试用例编写完成后我们需要使用BENCHMARK(<function_name>);将我们的测试用例注册进benchmark,这样程序运行时才会执行我们的测试。
最后是用BENCHMARK_MAIN();替代直接编写的main函数,它会处理命令行参数并运行所有注册过的测试用例生成测试结果。
示例中大量使用了constexpt,这是为了能在编译期计算出需要的数值避免对测试产生太多噪音。
参数
向测试用例传递参数
之前我们的测试用例都只接受一个benchmark::State&类型的参数,如果我们需要给测试用例传递额外的参数呢?
举个例子,假如我们需要实现一个队列,现在有ring buffer和linked list两种实现可选,现在我们要测试两种方案在不同情况下的性能表现:
// 必要的数据结构
#include "ring.h"
#include "linked_ring.h"
// ring buffer的测试
static void bench_array_ring_insert_int_10(benchmark::State& state)
{
auto ring = ArrayRing<int>(10);
for (auto _: state) {
for (int i = 1; i <= 10; ++i) {
ring.insert(i);
}
state.PauseTiming(); // 暂停计时
ring.clear();
state.ResumeTiming(); // 恢复计时
}
}
BENCHMARK(bench_array_ring_insert_int_10);
// linked list的测试
static void bench_linked_queue_insert_int_10(benchmark::State &state)
{
auto ring = LinkedRing<int>{};
for (auto _:state) {
for (int i = 0; i < 10; ++i) {
ring.insert(i);
}
state.PauseTiming();
ring.clear();
state.ResumeTiming();
}
}
BENCHMARK(bench_linked_queue_insert_int_10);
// 还有针对删除的测试,以及针对string的测试,都是高度重复的代码,这里不再罗列
很显然,上面的测试除了被测试类型和插入的数据量之外没有任何区别,如果可以通过传入参数进行控制的话就可以少写大量重复的代码。
编写重复的代码是浪费时间,而且往往意味着你在做一件蠢事,google的工程师们当然早就注意到了这一点。虽然测试用例只能接受一个benchmark::State&类型的参数,但我们可以将参数传递给state对象,然后在测试用例中获取:
static void bench_array_ring_insert_int(benchmark::State& state)
{
auto length = state.range(0);
auto ring = ArrayRing<int>(length);
for (auto _: state) {
for (int i = 1; i <= length; ++i) {
ring.insert(i);
}
state.PauseTiming();
ring.clear();
state.ResumeTiming();
}
}
BENCHMARK(bench_array_ring_insert_int)->Arg(10);
上面的例子展示了如何传递和获取参数:
- 传递参数使用BENCHMARK宏生成的对象的Arg方法
- 传递进来的参数会被放入state对象内部存储,通过range方法获取,调用时的参数0是传入参数的需要,对应第一个参数
Arg方法一次只能传递一个参数,那如果一次想要传递多个参数呢?也很简单:
static void bench_array_ring_insert_int(benchmark::State& state)
{
auto ring = ArrayRing<int>(state.range(0));
for (auto _: state) {
for (int i = 1; i <= state.range(1); ++i) {
ring.insert(i);
}
state.PauseTiming();
ring.clear();
state.ResumeTiming();
}
}
BENCHMARK(bench_array_ring_insert_int)->Args({10, 10});
上面的例子没什么实际意义,只是为了展示如何传递多个参数,Args方法接受一个vector对象,所以我们可以使用c++11提供的大括号初始化器简化代码,获取参数依然通过state.range方法,1对应传递进来的第二个参数。
有一点值得注意,参数传递只能接受整数,如果你希望使用其他类型的附加参数,就需要另外想些办法了。
简化多个类似测试用例的生成
向测试用例传递参数的最终目的是为了在不编写重复代码的情况下生成多个测试用例,在知道了如何传递参数后你可能会这么写:
static void bench_array_ring_insert_int(benchmark::State& state)
{
auto length = state.range(0);
auto ring = ArrayRing<int>(length);
for (auto _: state) {
for (int i = 1; i <= length; ++i) {
ring.insert(i);
}
state.PauseTiming();
ring.clear();
state.ResumeTiming();
}
}
// 下面我们生成测试插入10,100,1000次的测试用例
BENCHMARK(bench_array_ring_insert_int)->Arg(10);
BENCHMARK(bench_array_ring_insert_int)->Arg(100);
BENCHMARK(bench_array_ring_insert_int)->Arg(1000);
这里我们生成了三个实例,会产生下面的结果:
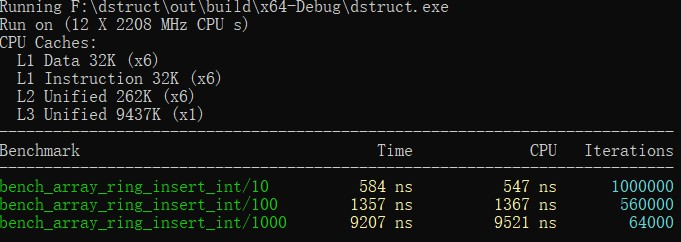
看起来工作良好,是吗?
没错,结果是正确的,但是记得我们前面说过的吗——不要编写重复的代码!是的,上面我们手动编写了用例的生成,出现了可以避免的重复。
幸好Arg和Args会将我们的测试用例使用的参数进行注册以便产生用例名/参数的新测试用例,并且返回一个指向BENCHMARK宏生成对象的指针,换句话说,如果我们想要生成仅仅是参数不同的多个测试的话,只需要链式调用Arg和Args即可:
BENCHMARK(bench_array_ring_insert_int)->Arg(10)->Arg(100)->Arg(1000);
结果和上面一样。
但这还不是最优解,我们仍然重复调用了Arg方法,如果我们需要更多用例时就不得不又要做重复劳动了。
对此google benchmark也有解决办法:我们可以使用Range方法来自动生成一定范围内的参数。
先看看Range的原型:
BENCHMAEK(func)->Range(int64_t start, int64_t limit);
start表示参数范围起始的值,limit表示范围结束的值,Range所作用于的是一个_闭区间_。
但是如果我们这样改写代码,是会得到一个错误的测试结果:
BENCHMARK(bench_array_ring_insert_int)->Range(10, 1000);

为什么会这样呢?那是因为Range默认除了start和limit,中间的其余参数都会是某一个基底(base)的幂,基地默认为8,所以我们会看到64和512,它们分别是8的平方和立方。
想要改变这一行为也很简单,只要重新设置基底即可,通过使用RangeMultiplier方法:
BENCHMARK(bench_array_ring_insert_int)->RangeMultiplier(10)->Range(10, 1000);
现在结果恢复如初了。
使用Ranges可以处理多个参数的情况:
BENCHMARK(func)->RangeMultiplier(10)->Ranges({{10, 1000}, {128, 256}});
第一个范围指定了测试用例的第一个传入参数的范围,而第二个范围指定了第二个传入参数可能的值(注意这里不是范围了)。
与下面的代码等价:
BENCHMARK(func)->Args({10, 128})
->Args({100, 128})
->Args({1000, 128})
->Args({10, 256})
->Args({100, 256})
->Args({1000, 256})
实际上就是用生成的第一个参数的范围于后面指定内容的参数做了一个笛卡尔积。
使用参数生成器
如果我想定制没有规律的更复杂的参数呢?这时就需要实现自定义的参数生成器了。
一个参数生成器的签名如下:
void CustomArguments(benchmark::internal::Benchmark* b);
我们在生成器中计算处参数,然后调用benchmark::internal::Benchmark对象的Arg或Args方法像上两节那样传入参数即可。
随后我们使用Apply方法把生成器应用到测试用例上:
BENCHMARK(func)->Apply(CustomArguments);
下面看下Apply的具体使用:
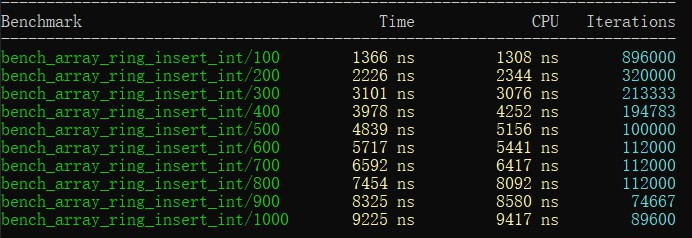
// 这次我们生成100,200,...,1000的测试用例,用range是无法生成这些参数的
static void custom_args(benchmark::internal::Benchmark* b)
{
for (int i = 100; i <= 1000; i += 100) {
b->Arg(i);
}
}
BENCHMARK(bench_array_ring_insert_int)->RangeMultiplier(10)->Apply(custom_args);
自定义参数的测试结果:
计算时间复杂度
我们人为制造几个时间复杂度分别为O(n), O(logn), O(n^n)的测试用例:
// 这里都是为了演示而写成的代码,没有什么实际意义
static void bench_N(benchmark::State& state)
{
int n = 0;
for ([[maybe_unused]] auto _ : state) {
for (int i = 0; i < state.range(0); ++i) {
benchmark::DoNotOptimize(n += 2); // 这个函数防止编译器将表达式优化,会略微降低一些性能
}
}
state.SetComplexityN(state.range(0));
}
BENCHMARK(bench_N)->RangeMultiplier(10)->Range(10, 1000000)->Complexity();
static void bench_LogN(benchmark::State& state)
{
int n = 0;
for ([[maybe_unused]] auto _ : state) {
for (int i = 1; i < state.range(0); i *= 2) {
benchmark::DoNotOptimize(n += 2);
}
}
state.SetComplexityN(state.range(0));
}
BENCHMARK(bench_LogN)->RangeMultiplier(10)->Range(10, 1000000)->Complexity();
static void bench_Square(benchmark::State& state)
{
int n = 0;
auto len = state.range(0);
for ([[maybe_unused]] auto _ : state) {
for (int64_t i = 1; i < len*len; ++i) {
benchmark::DoNotOptimize(n += 2);
}
}
state.SetComplexityN(len);
}
BENCHMARK(bench_Square)->RangeMultiplier(10)->Range(10, 100000)->Complexity();
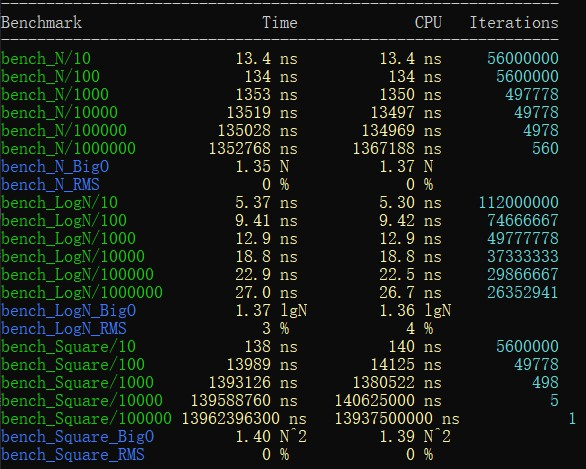
需要关注的是新出现的state.SetComplexityN和Complexity。
首先是state.SetComplexityN,参数是一个64位整数,用来表示算法总体需要处理的数据总量。benchmark会根据这个数值,再加上运行耗时以及state的迭代次数计算出一个用于后面预估平均时间复杂度的值。
Complexity会根据同一组的多个测试用例计算出一个较接近的平均时间复杂度和一个均方根值,需要和state.SetComplexityN配合使用。
Complexity还有一个参数,可以接受一个函数或是benchmark::BigO枚举,它的作用是提示benchmark该测试用例的时间复杂度,默认值为benchmark::oAuto,测试中会自动帮我们计算出时间复杂度。对于较为复杂的算法,而我们又有预期的时间按复杂度,这时我们就可以将其传给这个方法,比如对于第二个测试用例,我们还可以这样写:
static void bench_LogN(benchmark::State& state)
{
// 中间部分与前面一样,略过
}
BENCHMARK(bench_LogN)->RangeMultiplier(10)->Range(10, 1000000)->Complexity(benchmark::oLogN);
在选择正确的提示后对测试结果几乎没有影响,除了偏差值可以降得更低,使结果更准确。
Complexity在计算时间复杂度时会保留复杂度的系数,因此,如果我们发现给出的提示的时间复杂度前的系数过大的话,就意味着我们的预估发生了较大的偏差,同时它还会计算出RMS值,同样反应了时间复杂度的偏差情况。
运行我们的测试:
显示时间单位
Benchmark* Unit(TimeUnit unit);
设置显示时间单位:
kNanosecond, kMicrosecond, kMillisecond, kSecond.
例子:
BENCHMARK(xxxxx)->Unit(benchmark::kMillisecond);
















 794
794











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









