







1. kubeflow介绍
Kubeflow项目致力于使机器学习(ML)工作流在Kubernetes上的部署变得简单、可移植和可扩展。目标不是重新创建其他服务,而是提供一种直接的方法,将ML的开源系统部署到不同的基础设施中。无论在哪里运行Kubernetes,都能够运行Kubeflow。
下图显示了Kubeflow的主要组件,涵盖了Kubernetes之上ML生命周期的每个步骤。
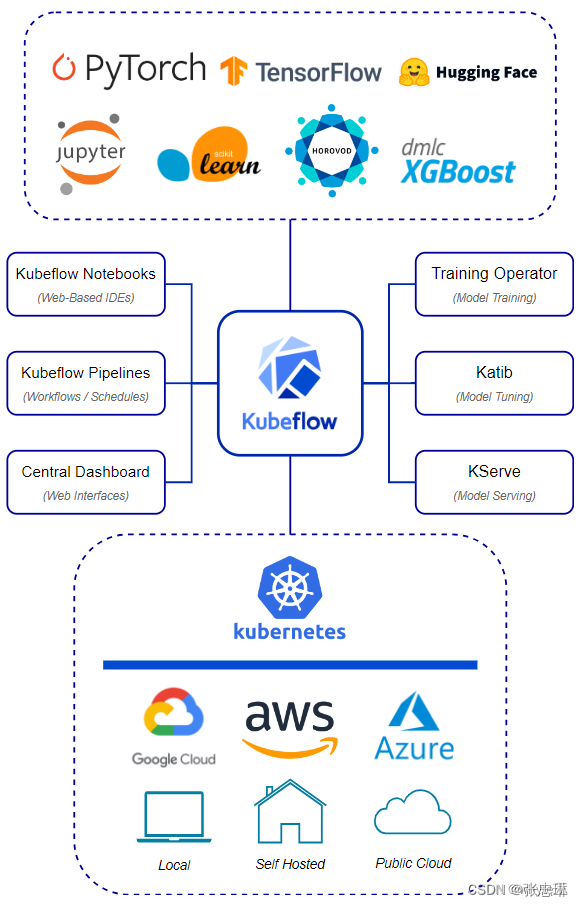
1.1 What is Kubeflow?
Kubeflow是用于Kubernetes的机器学习工具包。要使用Kubeflow,基本工作流程是:
- 下载并部署运行Kubeflow二进制文件。
- 自定义生成的配置文件。
- 运行指定的脚本,将容器部署到指定的环境中。
您可以调整配置以选择要用于ML工作流的每个阶段的平台和服务:
- 数据准备
- 模型训练
- 预测服务
- 服务管理
可以选择在本地或云环境中部署Kubernetes工作负载。
1.2 Kubeflow任务
目标是通过让Kubernetes做擅长的事情,扩展机器学习(ML)模型并尽可能简单将其部署到生产中:
- 在多样化的基础设施上可以简单、可重复、可移植的部署(例如,在笔记本电脑上进行实验,然后移到本地集群或云)
- 部署和管理松散耦合的微服务
- 根据需求进行扩展
由于ML从业者使用各种各样的工具,其中一个关键目标是根据用户需求(在合理的范围内)定制堆栈,并让系统处理“无聊的东西”。虽然开始时使用的技术范围很窄,但是我们正在处理许多不同的项目,以包括额外的工具。
最终,我们希望有一组简单的清单,能够在 Kubernetes 已经运行的任何地方轻松地使用 ML 堆栈,并且可以根据它部署到的集群进行自我配置。
2. 架构
该文档介绍了 Kubeflow 作为开发和部署机器学习(ML)系统的平台。Kubeflow是一个可以为想要构建和实验ML流水线的数据科学家提供的平台。Kubeflow 也为机器学习工程师和运营团队提供服务,将机器学习系统部署到不同的环境中进行开发、测试和生产级服务。
Kubeflow是Kubernetes的ML工具包。
下图显示了Kubeflow作为一个平台,用于在Kubernetes上部署ML系统的组件:
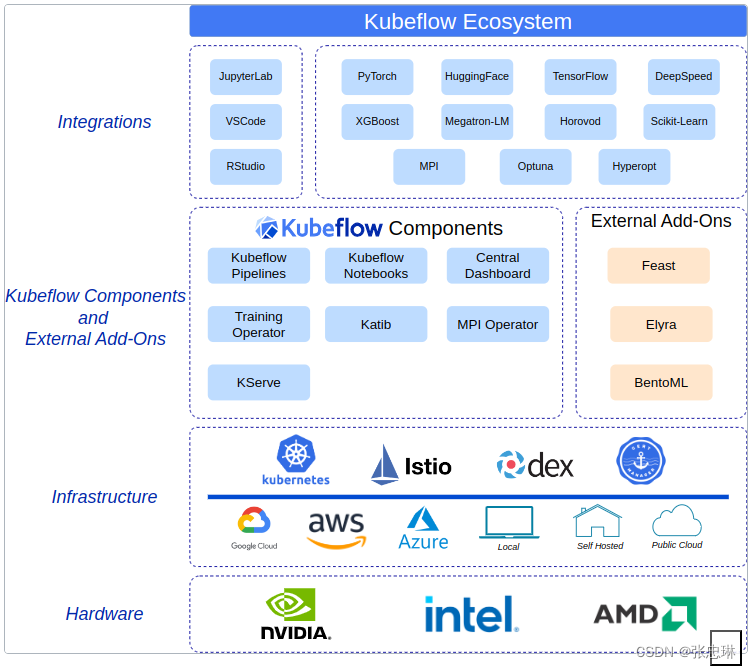
Kubeflow 构建于 Kubernetes 之上,作为部署、扩展和管理复杂系统的系统。使用Kubeflow配置接口(见下文),您可以指定工作流所需的ML工具。然后,您可以将工作流部署到各种云、本地和内部平台,以便进行试验和生产使用。
2.1 介绍ML工作流
在开发和部署机器学习系统时,机器学习工作流通常由几个阶段组成。开发机器学习系统是一个迭代的过程。您需要评估机器学习工作流程各个阶段的输出,并在必要时对模型和参数应用更改,以确保模型持续产生您需要的结果。
为了简单起见,以下图表显示了工作流阶段的顺序。工作流末尾的箭头指向流,表示流程的迭代性质:
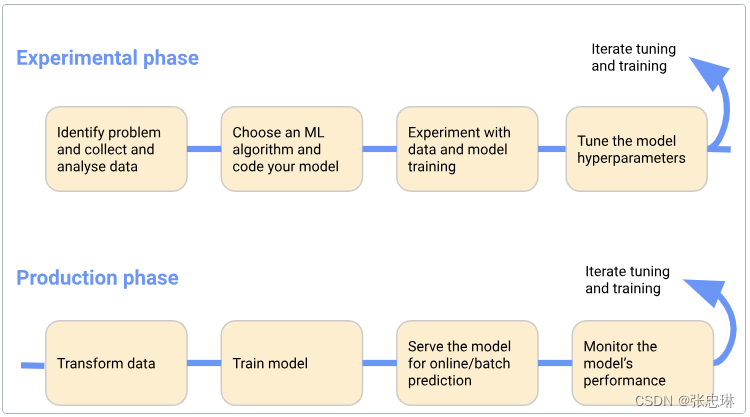
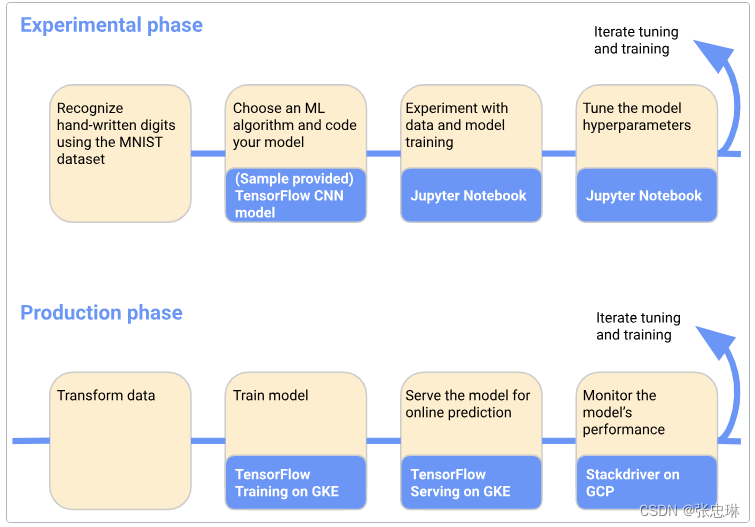
在机器学习工作流程中包含实验阶段和生产阶段。
A. 在实验阶段,基于初始假设开发模型,并反复测试和更新模型以产生你想要的结果:
- 确定想要机器学习系统解决的问题。
- 收集和分析训练机器学习模型所需的数据。
- 选择一个机器学习框架和算法,并对模型的初始版本进行编码。
- 对数据进行实验,并训练模型。
- 调整模型的超参数,以确保处理最有效率并获得最准确的结果。
B. 在生产阶段,您部署了一个执行以下过程的系统:
- 将数据转换成训练系统所需的格式。为了确保模型在训练和预测过程中行为一致,转换过程在实验阶段和生产阶段必须相同。
- 训练机器学习模型。
- 将模型提供给在线预测或批处理运行。
- 监控模型的性能,并将结果反馈到调整或重新训练模型的过程中。
2.2 ML工作流的Kubeflow组件
下一张图将Kubeflow添加到工作流中,显示了Kubeflow在每个阶段哪些组件是有用的:
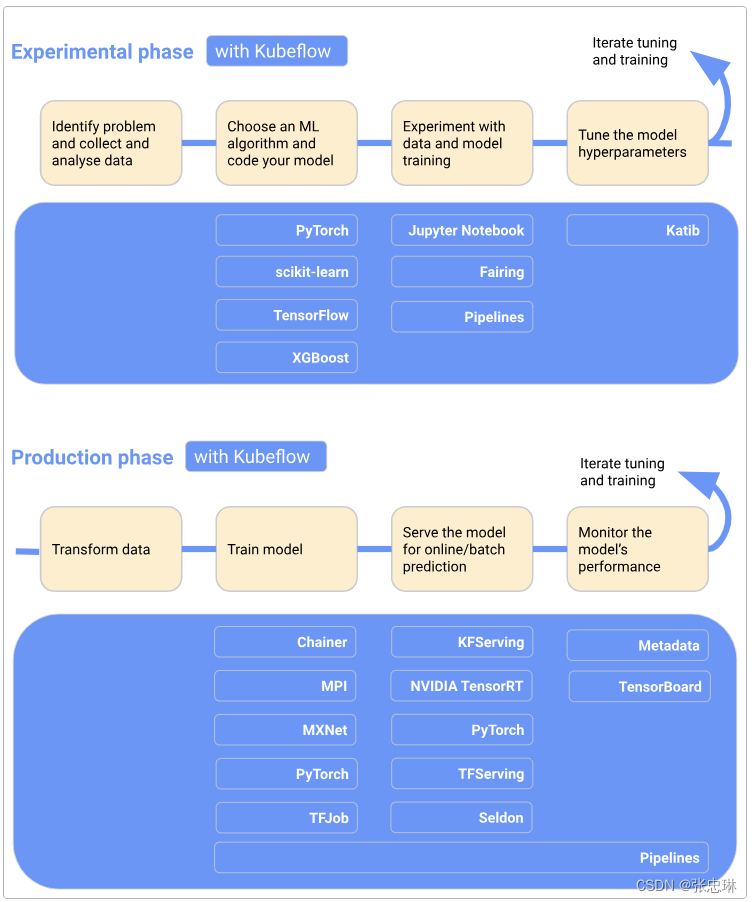
要了解更多信息,请阅读以下 Kubeflow 组件指南:
- Kubeflow 包括用于生成和管理 Jupyter notebooks 的服务。使用 noteboks 进行交互式数据科学和机器学习工作流的实验。
- Kubeflow Pipelines 是一个基于 Docker 容器构建、部署和管理多步骤 ML 工作流的平台。
- Kubeflow 提供了几个组件,您可以使用它们来构建机器学习培训、超参数调优和跨多个平台服务工作负载。
2.3 ML工作流的例子
以下图表展示了一个简单的特定机器学习工作流程示例,您可以使用它来训练并提供一个在MNIST数据集上训练的模型:
3. 安装 kubeflow
无论您在哪里运行Kubernetes,都应该能够运行Kubeflow。安装Kubeflow主要有两种方法:
- Packaged Distributions
- Raw Manifests (advanced users)
3.1 Install with a single command
GitHub - kubeflow/manifests at v1.8-branch
while ! kustomize build example | kubectl apply -f -; do echo "Retrying to apply resources"; sleep 10; done
国内环境拉取镜像失败可以增加前缀 :
gcr.io/ml-pipeline/metadata-envoy:2.0.0-alpha.7
m.daocloud.io/gcr.io/ml-pipeline/metadata-envoy:2.0.0-alpha.7

跑起来了,试用看看,跑一些案例。后面看看实现细节
参考:

















 915
915

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









