






解决问题:对比文件A和文件B,查找文件A中文件B的数据,如果有,则高亮背景绿色显示。
文件A:source.xlsx
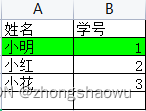
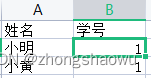
文件B: dest.xlsx
from openpyxl import Workbook
from openpyxl import load_workbook
from openpyxl.styles import Alignment,Border,Side,PatternFilldef read_workbook(filename):
wb = load_workbook(filename)
#print(wb.sheetnames)
return wbdef find_different(sourfile, sourcesheet,destfile, destsheet):
#print("find_different \n")
sourWB = read_workbook(sourfile)
sourSheet = sourWB[sourcesheet]
destWB = read_workbook(destfile)
destSheet = destWB[destsheet]
initfill = PatternFill('solid')
flag = False
fill = PatternFill('solid', fgColor="00FF00")
border = \
Border(left=Side(style='thin', color='00000000'),
bottom=Side(style='thin', color='00000000'),
right=Side(style='thin', color='00000000'),
top=Side(style='thin', color='00000000'))
initborder = \
Border(left=Side(style='thin', color='00000000'),
bottom=Side(style='thin', color='00000000'),
right=Side(style='thin', color='00000000'),
top=Side(style='thin', color='00000000'))
differences = []
#遍历两个工作表的行和单元格
for row1 in sourSheet.iter_rows(min_row=3,max_row=None,min_col=1,max_col=1,values_only=False):
for cell1 in row1:
value1 = cell1.value
if value1:
for row2 in destSheet.iter_rows(min_row=11,max_row=None,min_col=4,max_col=4,values_only=False):
for cell2 in row2:
value2 = cell2.value
if value2 == value1:
flag = True
#print(f"find the same: {value1},{value2}")
cell1.border = border
cell1.fill = fill
break
else:
flag = False
#print(f"Can't find the same: {value1}")
#没有找到匹配的单元格,记录下来
#cell1.border = initborder
#cell1.fill = initfill
#differences.append((cell1.row,cell1.column, value1))
if flag == False:
#cell1.border = initborder
#cell1.fill = initfill
differences.append(cell1)
print(differences)
sourWB.save(sourfile)
destWB.save(destfile)
returndef read_sheet2():
myworkbook = load_workbook("test.xlsx")
sheet = wb["工作表1"]
#rows = sheet.cell(row=1, column=3)
for rows in sheet:
for cell in rows:
print(cell.value,end=" ")
returndef create_mysheet(filename):
myworkbook = load_workbook(filename)
wb.save(filename)
sheet = wb.active
sheet2 = wb.create_sheet("工作表1")
sheet3 = wb.create_sheet("工作表2")
return wb#创建一个工作表
wb = Workbook()
wb.save("test1.xlsx")
wb = create_mysheet("test1.xlsx")
#保存为本地excel文件
sheet = wb.active
sheet2 = wb['工作表1']
sheet3 = wb['工作表2']
sourceFile = f"MCU_CDCU_CommunicationMatrix.xlsx"
destFile = f"F57_CDCU_Testcase_下行测试用例Lev2.xlsx"
sourceSheet = f"IVIToMCU"
destSheet = f"TC"
find_different(sourceFile,sourceSheet, destFile, destSheet)
#在前3行,前6列输入数据
for i in range(1,3):
for j in range(1,6):
cell = sheet.cell(row= i, column= j, value= 111)
cell.alignment = Alignment(horizontal="center", vertical="center")
cell.border =\
Border(left=Side(style='thin', color='00000000'),
bottom=Side(style='thin', color='00000000'),
right=Side(style='thin', color='00000000'),
top=Side(style='thin', color='00000000'))
cell.fill = PatternFill('solid', fgColor="00FF00")
sheet2.cell(row= i, column= j, value= 222)
sheet3.cell(row=i, column=j, value=333)
#for s in wb:
#print(s.title)
current = wb["工作表1"]
#read_sheet2()
wb.save("工作表1")














 2499
2499

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









