









文章目录
前言
innodb锁与事务模型这块确实比较复杂,没有许多经验的积累是没办法深刻理解的。不过好在本系列是指引系列,所谓抛砖引玉,下面就开始抛砖了。
我们再来看下 innodb 的基本结构,这就是地图啊,非常重要!对它进一步拆解。
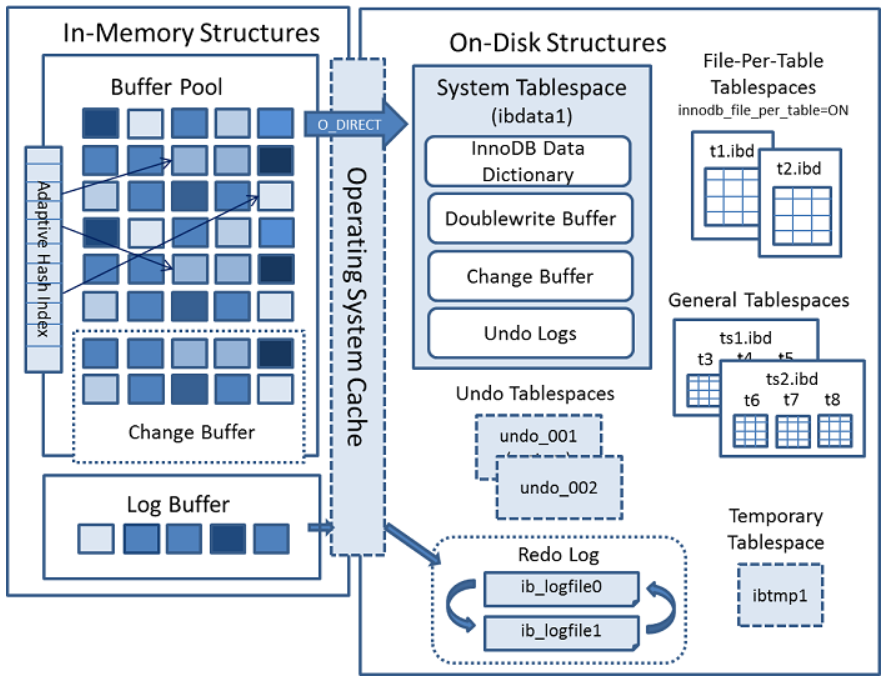
关于这幅"地图",我们在mysql指引(六):InnoDB的基本结构 中已经说过一些。
简要回顾几个点:
- innodb中有很多种类型的
页,页就是innodb管理数据的最小单元 - 每个表空间都是一堆页的集合。系统有一个全局的系统表空间,默认情况下,每张数据表都有一个自己的表空间
innodb结构拆解
逻辑上的划分
拆解之前,先说下最关键的引子就在于速度,分为两块:
- 内存的读写速度远高于磁盘
- 磁盘的顺序IO速度远高于随机IO速度
假如磁盘的IO速度和内存访问一样快,那也就没内存什么事了,则innodb的结构可要大改了。
除了速度之外,我们更加关心可靠性,也就是面对各种异常,数据都能保证可靠。
再有一点就是关于实现事务的ACID要求。
这些方面结合起来就构成了 innodb 的基本结构。
WAL
首先来看一个概念,WAL(Write Ahead Log) ,即日志先于数据落盘。
数据可以先写到内存中,当日志持久化到磁盘后,才算执行成功。后续可以再某个时间点将数据刷到磁盘中。
这样在享受到持久化可靠性的同时也能享受到内存的速度,一举两得。
redo log
最重要的最基础的 redo log ,他是解决可靠性的核心,innodb地图中很多组件都要依赖于 redo log 提供的能力。
WAL 中提到的日志,在这里实际上就是 redo log。
redo log 记录当然不是直接的数据信息,但是后续可能通过这条记录来恢复数据。可以暂时理解 记录 ≈ 数据的另一种编码 。
下文还需继续说redo log
Buffer Pool
上面写到内存中,实际上就是写到 Buffer Pool中。关于 Buffer Pool ,我们前文提到过。Buffer Pool是非常重要的缓存池,基本上会将内存的大部分都留给它,足以见其重要性。下文简称为 BP
BP管理的缓存单位就是在 mysql指引(八):innodb页结构 中提到的 页 ,当然,页种类有很多,我们先关注的是 数据页 。
查询语句
假设首次执行查询时,BP中肯定没有数据页的。所以是直接去磁盘中将记录所在的页读取到内存中,即缓存到BP中。这样下次再次读取该记录或者相邻的记录时,就会直接命中BP中的缓存,而不需要走磁盘IO。
但是
我们假设下面的情景:
BP大小为1G,其中300M的数据页是系统中被经常访问的,700M的数据页是偶尔访问的。可是不断会有新的数据页进入BP,那也意味着同样不断有数据页从BP中被淘汰出去(即被覆盖)。那么BP如何保证淘汰的数据页是不经常使用的,即从 700M 的这些数据页中进行淘汰呢?
这是问题1。
再来看,假设此时进行全表扫描,假如表大小为2G,则如何保证不出现 “劣币驱逐良币”的现象,即不对 300M 数据页造成干扰呢?
这是问题2。
上面两个问题就引出了 BP 的 LRU 缓存淘汰算法,关于 LRU 是在任何缓存系统中都常见的算法。更细节的可以自行搜索资料,有很多BP的LRU说明。这个不是本篇的重点。
简要描述下,BP将内存分为两个区,暂称为一个热区一个冷区。300M的数据是在热区中,700M的数据页是在冷区中。
当新读入一个数据页时,就从冷区中淘汰一个数据页即可。至于淘汰哪个,就是LRU决定的。
当进行全表扫描时,实际上整体流程如下,假设每个数据页放着多条记录:
- mysql的执行器调用innodb引擎接口,告诉他读取第一行记录。这行记录所在数据页就被缓存到BP的冷区中。
- 执行器继续调用 innodb 引擎接口,读取下一行记录。由于第一行记录所在数据页已经在BP中了,所以第二行记录同样可以在BP中的这个数据页找到。
- 此时,由于该数据页被访问了一次,一般来讲,应该被放到热区中。但其实不会,因为这里做了特殊处理。第一步第二步的两次调用间隔实际上非常非常短,innodb中有一个参数来控制该时间间隔,假如设置为 K 毫秒。由于两次访问该数据页的时间间隔小于 K,所以该数据页仍然会保留在冷区中。这样就避免驱逐良币。
- 就算一张表的大小为1T,也不会将服务内存占满,因为执行器将数据存放到结果集中,在达到一定大小后会通过网络直接发送给客户端。然后继续读取数据。
- 假设现在再次进行全表扫描,由于两次访问同一个数据页的时间间隔大于K,所以对应的数据页就会移到热区。
好了,以上是提到BP不得不说的一个点,先放一放,接着来看更新语句。
更新语句
暂时省略额外的步骤,先简单看下更新的过程。
更新记录时,如果对应的数据页在BP中,则直接更新数据页即可。更新完成之后,至于数据页什么时候被刷到磁盘,这就和更新过程没关系了。
随后,查询数据的过程也和上文的查询语句一样,和更新过程没关系。
如果数据页不在内存中,此时执行更新操作怎么办呢?难道要先从磁盘读入内存,更新完成之后,在一个合适的时机再刷入到磁盘中吗?肯定不合适,白白浪费了性能。
这时,就要 change buffer 的配合了。
change buffer
主要说内存中的 change buffer,磁盘中的不影响理解。
对于不在内存中的数据页的修改,innodb直接向内存中的 change buffer 写入更新操作,这样就算更新完成了。
假如后续新的数据页A被读取内存中,则在返回结果之前,会利用 change buffer 中的记录去更新这个数据页A,这个过程叫做 merge。
除了这个时机,change buffer 还会被后台线程定期merge到磁盘域的数据页。
但是 change buffer 的应用场景有限制,可以自行查看。
undo log
undo log 是回滚日志,主要的作用两点:
- 事务回滚
- 用于MVCC(关于MVCC后续文章讲解)
undo log 中记录的是事务操作的相反操作,即逻辑记录。比如增加一条记录,对应到 undo log 中就是删除一条记录。
好了,先看到这里,下面会和redo 一起提到。
log buffer
log buffer是比较重要的,它缓存两类log:
- undo log
- redo log
关键点在于图中中部的 Operating system cache ,地图中有一个细节如下:
- BP和磁盘的交互就是直接有一个标注
O_DIRECT箭头过去的 - 而log buffer 和磁盘的交互,则是一个箭头到
operating system cache,另一个箭头到再从operating system cache到磁盘
这里先留个悬念,会在下篇来个番外篇讲述下。
doublewrite buffer
磁盘领域中,表空间和数据字典以前提到过,就不讲了。DW(doublewrite)操作提升了 page 写入到磁盘的可靠性。一个典型的场景:
数据页写入刚写了一半,服务器宕机。则磁盘中该数据页就是不完整的,出现 部分写失效 的情况。
所以在共享表空间中留出一块 DW区。当脏页需要从BP刷盘时,则首先将脏页顺序刷入DW区,然后再刷到实际的数据区。
这样,当向数据区刷盘时,系统宕机。重启恢复时,就可以从DW区中对宕机时出现部分写失效的页面进行恢复。
Master Thread说明
后台线程中,最主要的就是这个 Master Thread 线程了。他做的事情很多,仅列举下下文用到的知识点:
- 每秒定时将 log buffer 中的日志刷盘
- 每秒定时将 BP 中的数据页刷盘
事务结合 redo undo的分析
这里仅限定在图中的 innodb 结构范围,我们来看下 redo undo 的机制。
比如一个事务中,更新了多条记录。则会产生很多条 redo log,redo log就是对于 页 的物理修改记录。与此同时,也会产生多条undo log。简要过程如下:
- 生成记录A的 undo log
- 修改记录A
- 生成 redo log。
为了保证事务的ACID特性,innodb默认在事务提交前,会将 redo log全部刷盘,然后才算提交成功。
基于此,事务执行过程中,redo log会首先写入到 log buffer中,然后等待事务提交的时候,再从 log buffer中刷盘。别忘记 Master Thread 的存在,它会每秒将 log buffer 中的日志刷盘。
undo log同样会写入到 log buffer 中,所以和redo 刷盘机制一样。当执行中的事务需要回滚时,就利用 undo 这个逻辑日志进行回滚即可。
BP中的数据页被事务修改后,在事务提交之前,同样会被 Master Thread 刷盘。
这样,我们可以来看下 系统宕机后的恢复逻辑:
系统宕机后,内存中的数据全都不复存在,BP中的脏页来不及刷到磁盘。不过没关系,我们可以通过 redo log来对磁盘中的数据页进行恢复,这个比较好理解。所以WAL机制很重要,所以redo log需要在磁盘中保存,也即事务提交后需要刷盘。
可是,为什么 undo log 也需要在磁盘中保存呢?
事务执行过程中,由于 Master Thread 存在,可能某些脏页和生成的 redo 已经被刷盘了。那么宕机恢复时,由于 undo 没有持久化保存,导致对应的脏页无法回滚。所以 undo 也要在磁盘中保存。
为什么不可以利用 redo log 对脏页回滚呢?
因为 redo 记录的是 页 的物理修改,并没有记录逻辑修改。所以无法对脏页进行回滚。而 undo 记录的是脏页的逻辑操作,故可以通过 undo 执行操作,回滚脏页。
最后,将 undo 页 也看成是 数据页的话 :
那么,事务执行过程中产生的 undo log 同样要和数据页一样,受到 WAL 机制的保护。故直接利用 redo log 去记录 undo页的修改,实现 undo 的WAL机制。
这样子,完整的非只读类事务执行 有下面几点:
- undo写入 log buffer,记录对应的 redo log
- 修改内存中的数据页(如果数据页不存在,符合条件则修改 change buffer)
- 记录数据页操作对应的 redo log,写入 log buffer 中
- 事务提交时,将 log buffer 中的 日志刷盘
这样,总共就操作了几次内存,只走了一次磁盘IO,综合下来,性能非常高。同时,结合 redo undo 等,又保证了可靠性和持久性。
还有很多细节无法在一篇中说明,本篇主要再次了解 innodb 的基本结构和 redo undo 的功能。为后续的 MVCC、事务ACID实现等做铺垫。
















 1803
1803

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











